Data Visualization using R: BUS5VA Assignment 2, Semester 2 2019
VerifiedAdded on 2022/10/11
|10
|4553
|9
Practical Assignment
AI Summary
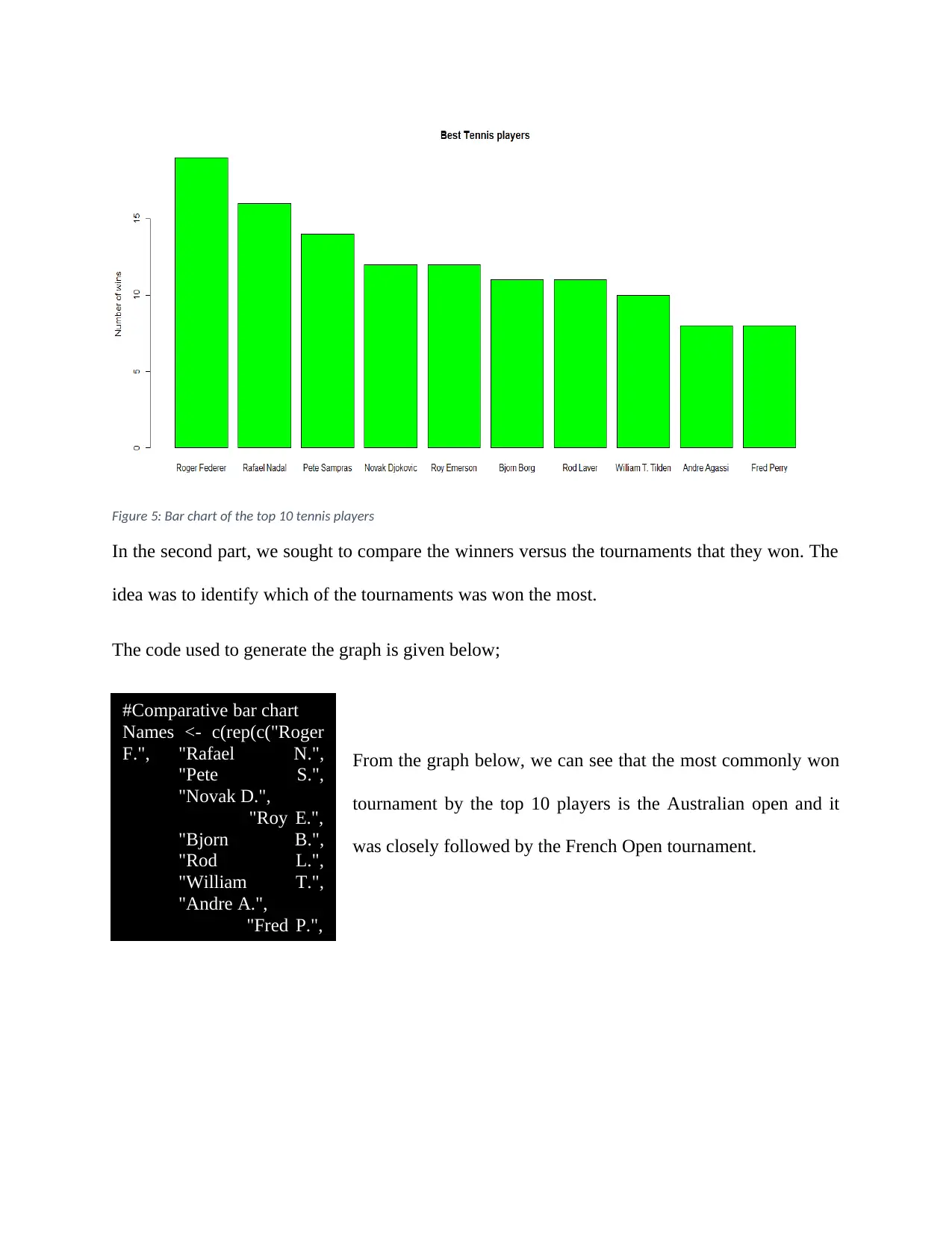
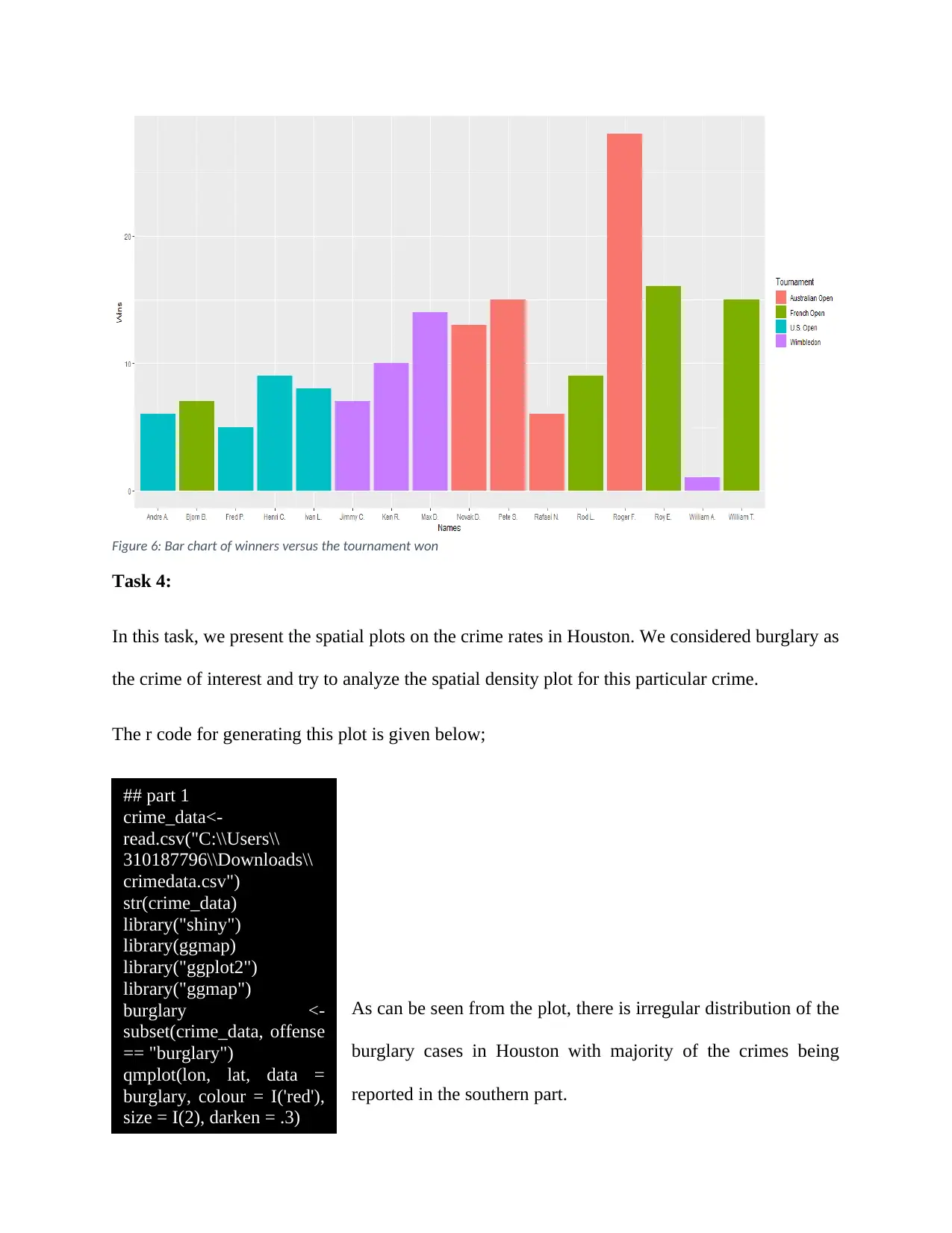
This assignment solution demonstrates data visualization techniques using R, addressing four tasks. Task 1 analyzes health condition proportions over time using bar charts, exploring changes between 2001 and 2018. Task 2 visualizes stock returns for top companies like Apple, Amazon, Google, and Facebook, identifying risky stocks and comparing market shares based on volume. Task 3 focuses on tennis player analysis, visualizing top players and comparing winners across tournaments using bar charts. Task 4 presents spatial plots to analyze crime rates, specifically burglary, in Houston. The solution includes R code for data import, manipulation, and visualization, along with interpretations of the generated plots and charts.




1 out of 10

Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.