Advance Analytic Capability of Different Issues Using Python & R
VerifiedAdded on 2021/12/11
|38
|7533
|73
Project
AI Summary
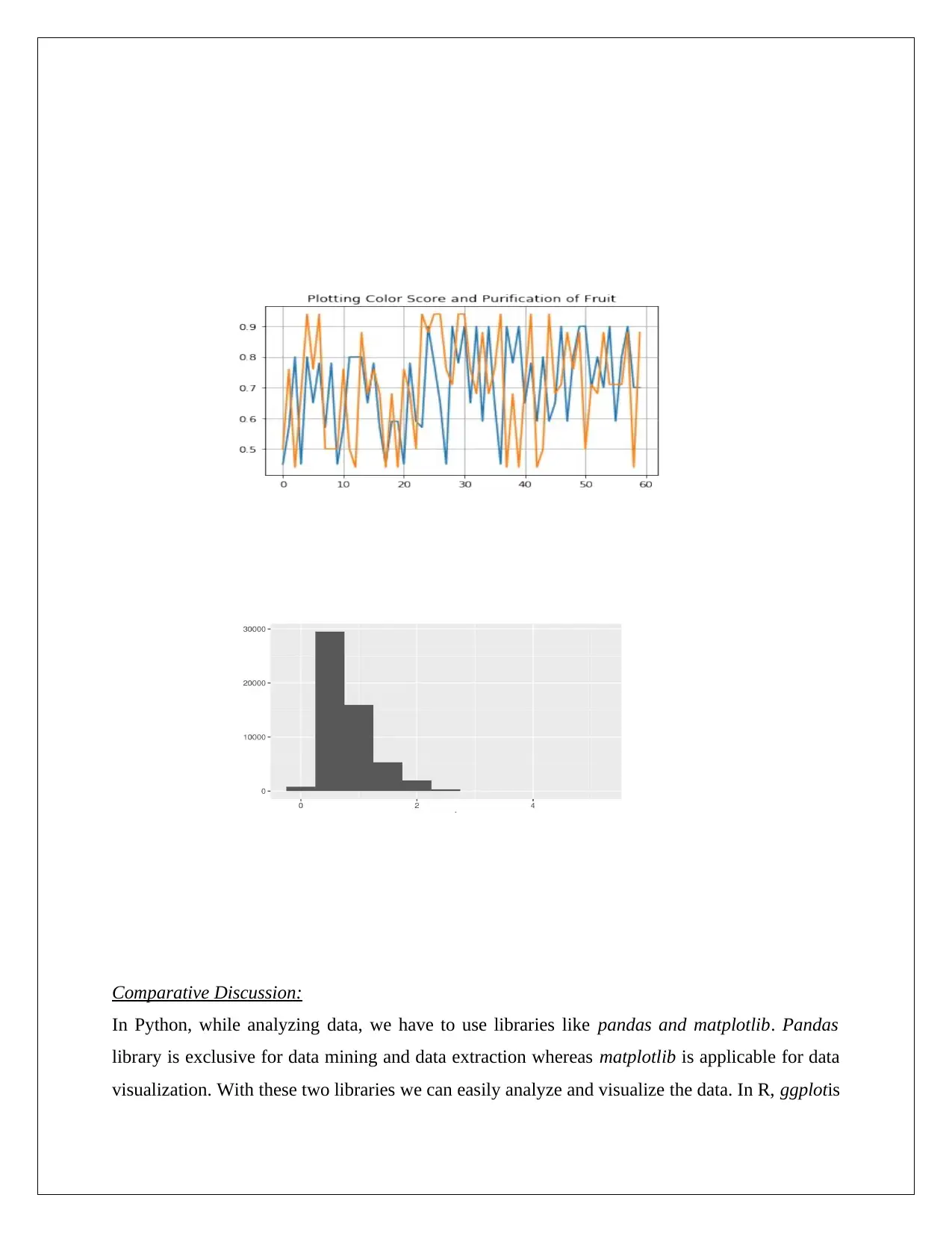
This project provides a comparative analysis of Python and R programming languages for addressing various challenges in artificial intelligence and machine learning. It begins with an introduction to the languages, highlighting their features, advantages, and applications in areas such as data science, data mining, and web development. The project then delves into specific analytical techniques, including analytical tools, classification, association analysis, correlation, regression, clustering, and anomaly detection. The assignment provides code examples and comparative discussions of how each technique can be implemented using both Python and R, along with the libraries and tools used for data analysis and visualization. The project emphasizes the strengths of each language in different contexts, particularly highlighting R's capabilities in statistical analysis and Python's versatility in diverse AI applications. The project aims to provide insights into the practical application of Python and R in tackling complex data-driven problems within the domain of artificial intelligence.











1 out of 38
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.