Advanced Databases and Applications CP5520: Clustering in Data Mining
VerifiedAdded on 2023/06/07
|21
|4137
|413
Report
AI Summary
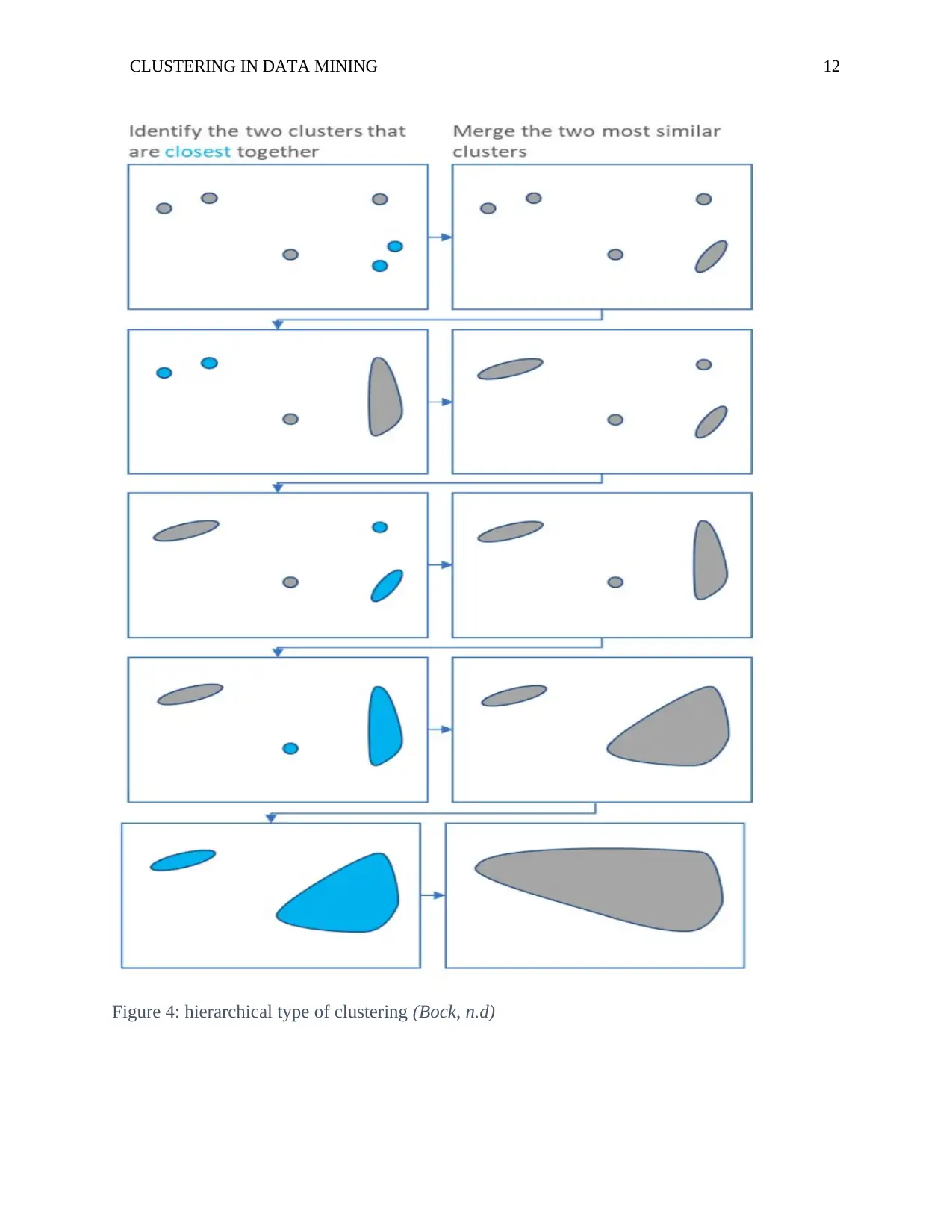
This research paper provides a comprehensive overview of clustering in data mining. It begins by defining clustering and its role in data mining, emphasizing its application in various fields such as image processing and market research. The paper then delves into the core concepts of data mining, detailing its procedure and the iterative process of knowledge discovery. A significant portion of the paper is dedicated to exploring the diverse types of clustering techniques, including partition, hierarchical, exclusive, and overlapping clustering, with a focus on k-means and CLARA algorithms. Through a detailed literature review, the paper analyzes the significance of clustering, its advantages, and its relevance in extracting valuable insights from large datasets. The research questions address the definition of clustering, types of clustering, data mining, and the rationale behind using clustering in data mining. The paper concludes by summarizing the key findings and emphasizing the importance of clustering as a fundamental technique in data analysis.











1 out of 21
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.