BUS5SBF: Statistics for Business and Finance - Household Data Analysis
VerifiedAdded on 2020/02/24
|9
|1028
|149
Homework Assignment
AI Summary
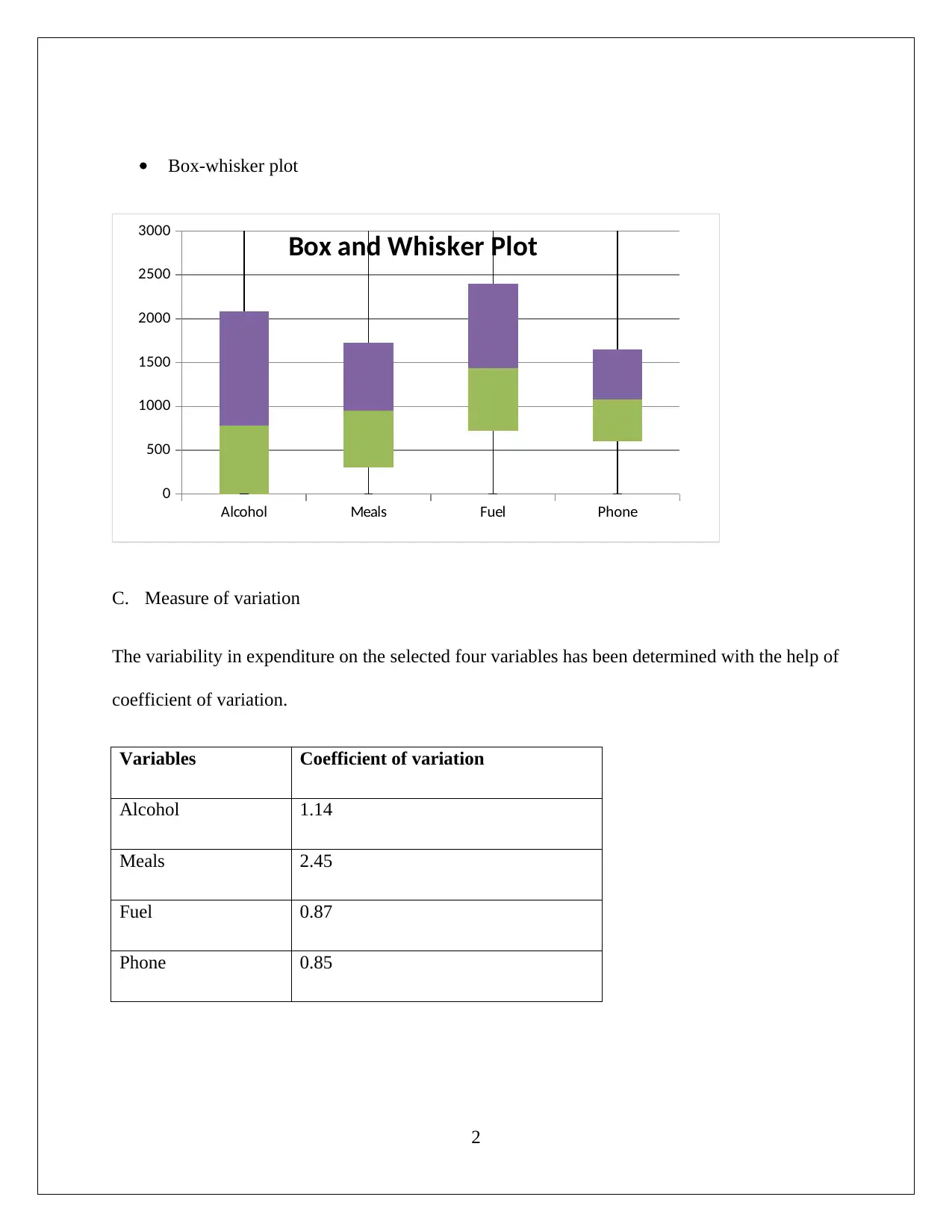
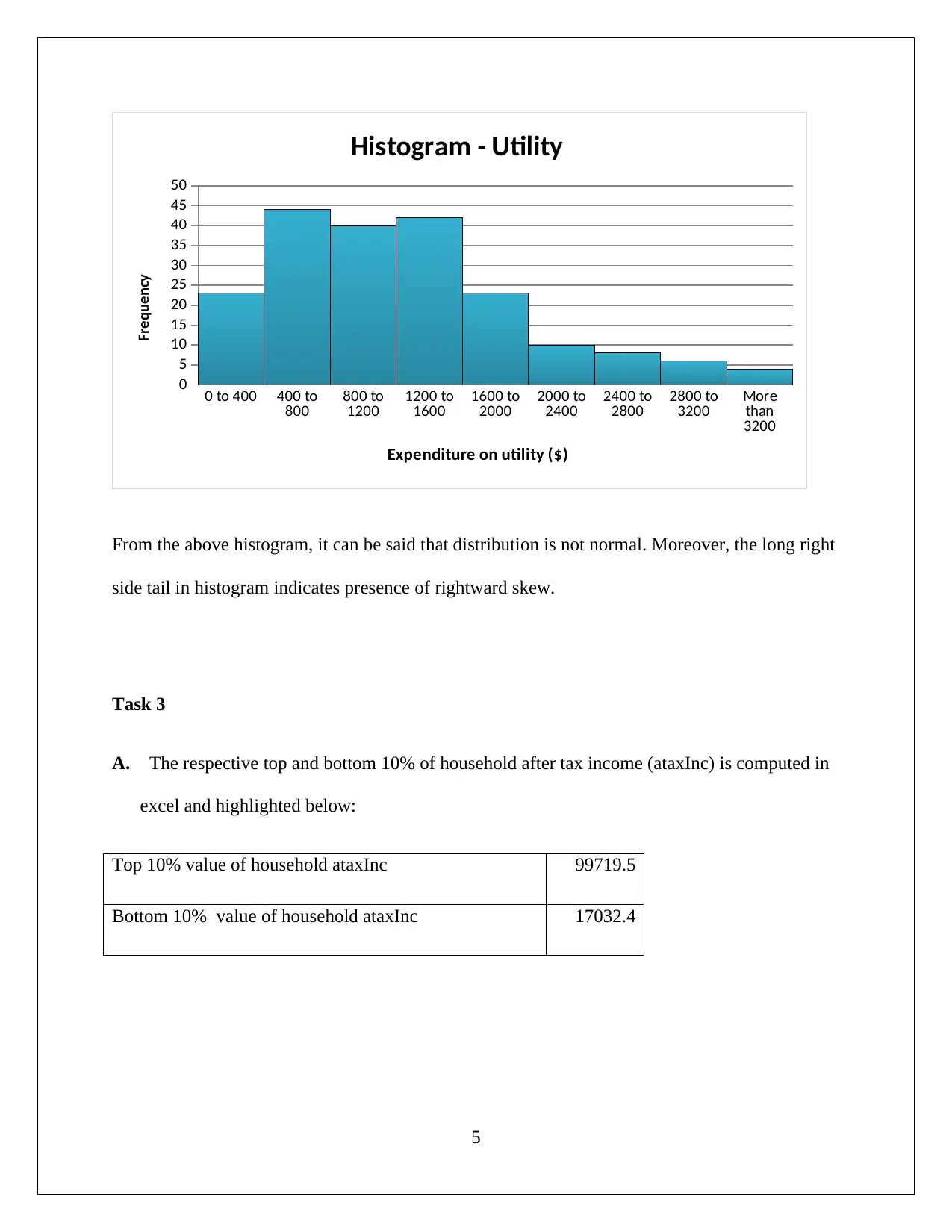
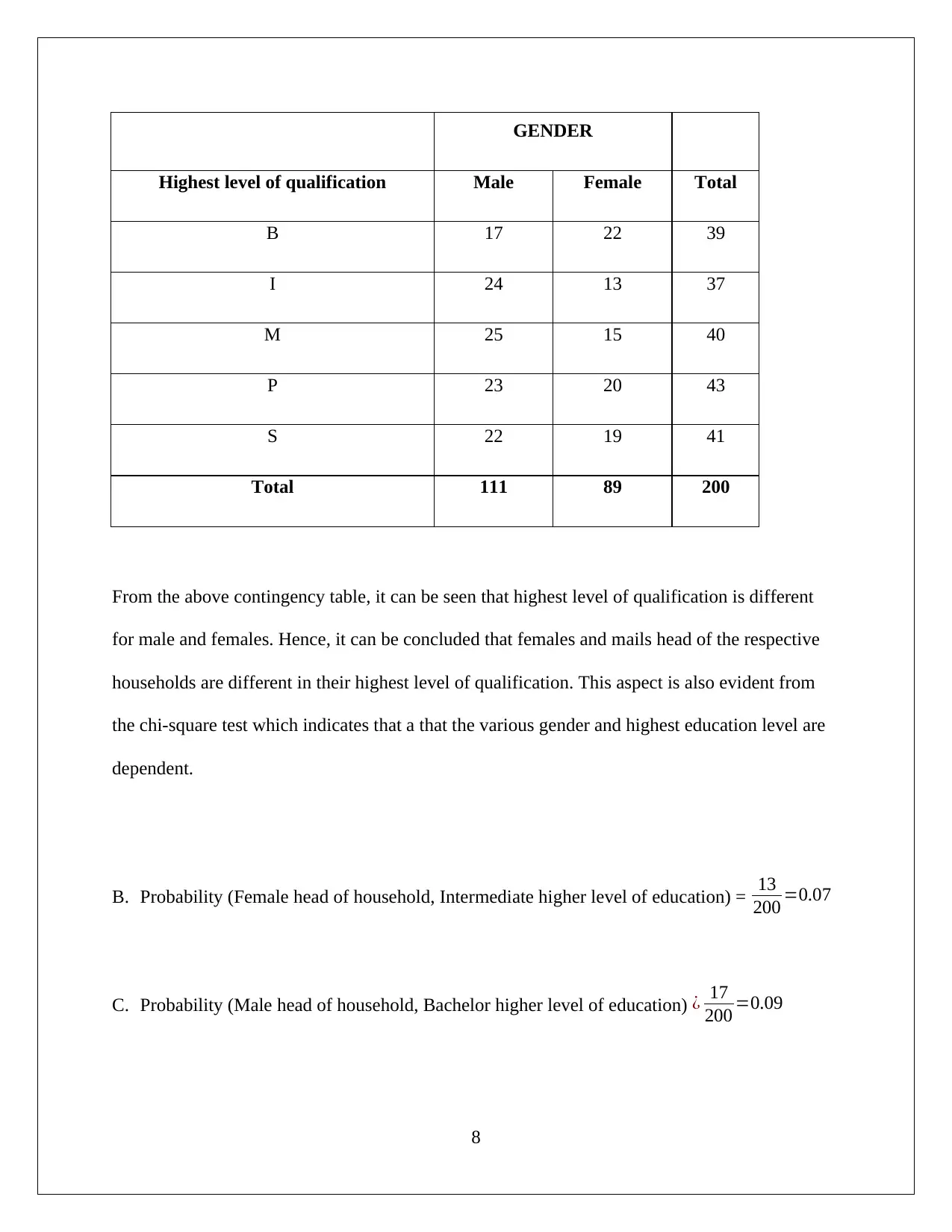
This document presents a comprehensive analysis of household data, addressing various statistical concepts and techniques. The analysis begins with a discussion of sampling methods, comparing random and stratified sampling, and justifying the use of stratified sampling. Descriptive statistics, including measures of variation (coefficient of variation) and box-whisker plots, are used to analyze the expenditure on variables like alcohol, meals, fuel, and phone. The assignment also explores frequency distributions and histograms for utility expenditures, identifying the distribution's characteristics. Furthermore, the document investigates income disparities by comparing the top and bottom 10% of household after-tax income and examines the relationship between after-tax income and total expenditure using correlation and scatter plots. Finally, a contingency table is constructed to analyze the relationship between gender and education levels, and the independence of events is tested using probability calculations and chi-square tests. The analysis provides insights into household characteristics, income distribution, and relationships between variables, demonstrating a strong understanding of statistical concepts.






1 out of 9
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.