Statistics Assignment: Analyzing Startup Costs and Regression Modeling
VerifiedAdded on 2020/03/23
|11
|439
|100
Homework Assignment
AI Summary
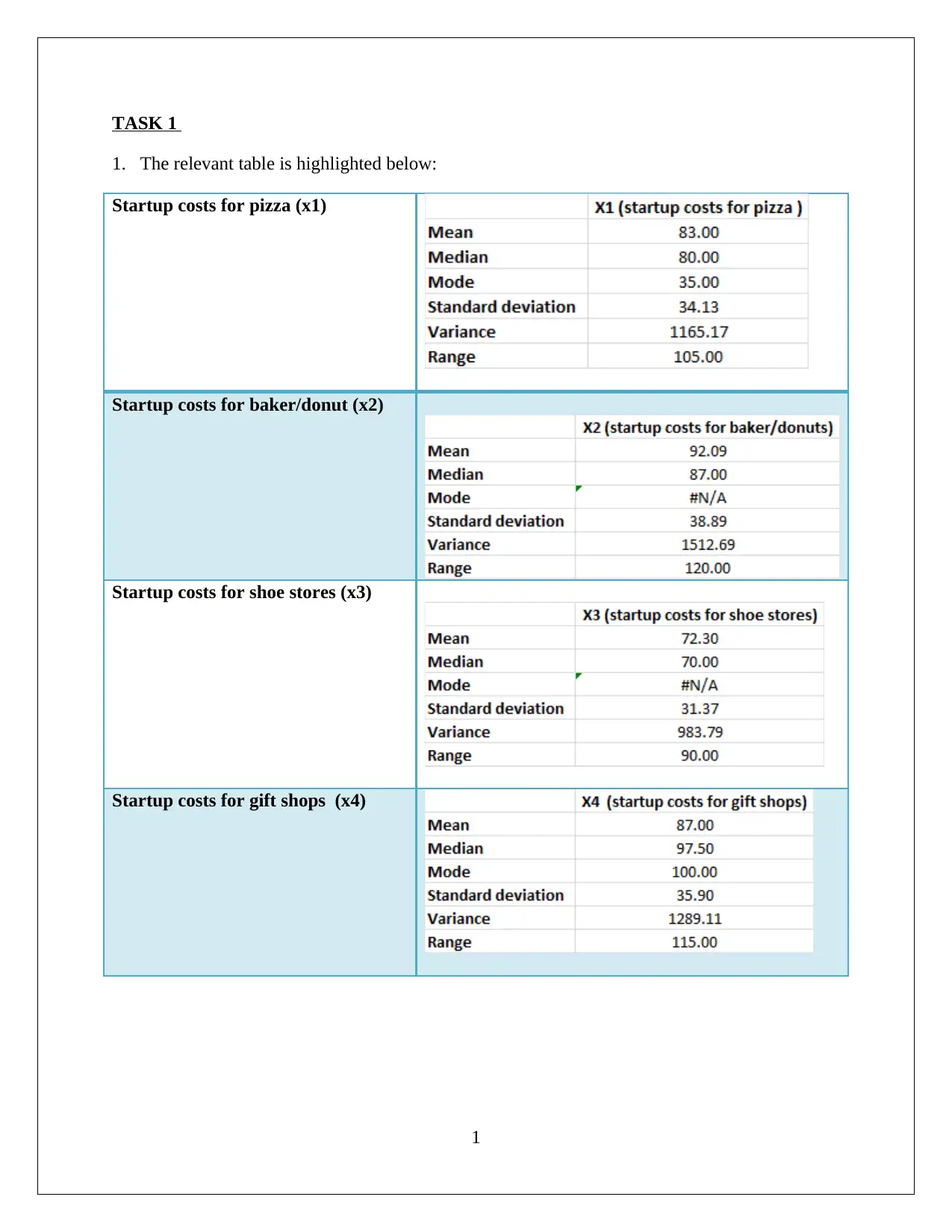
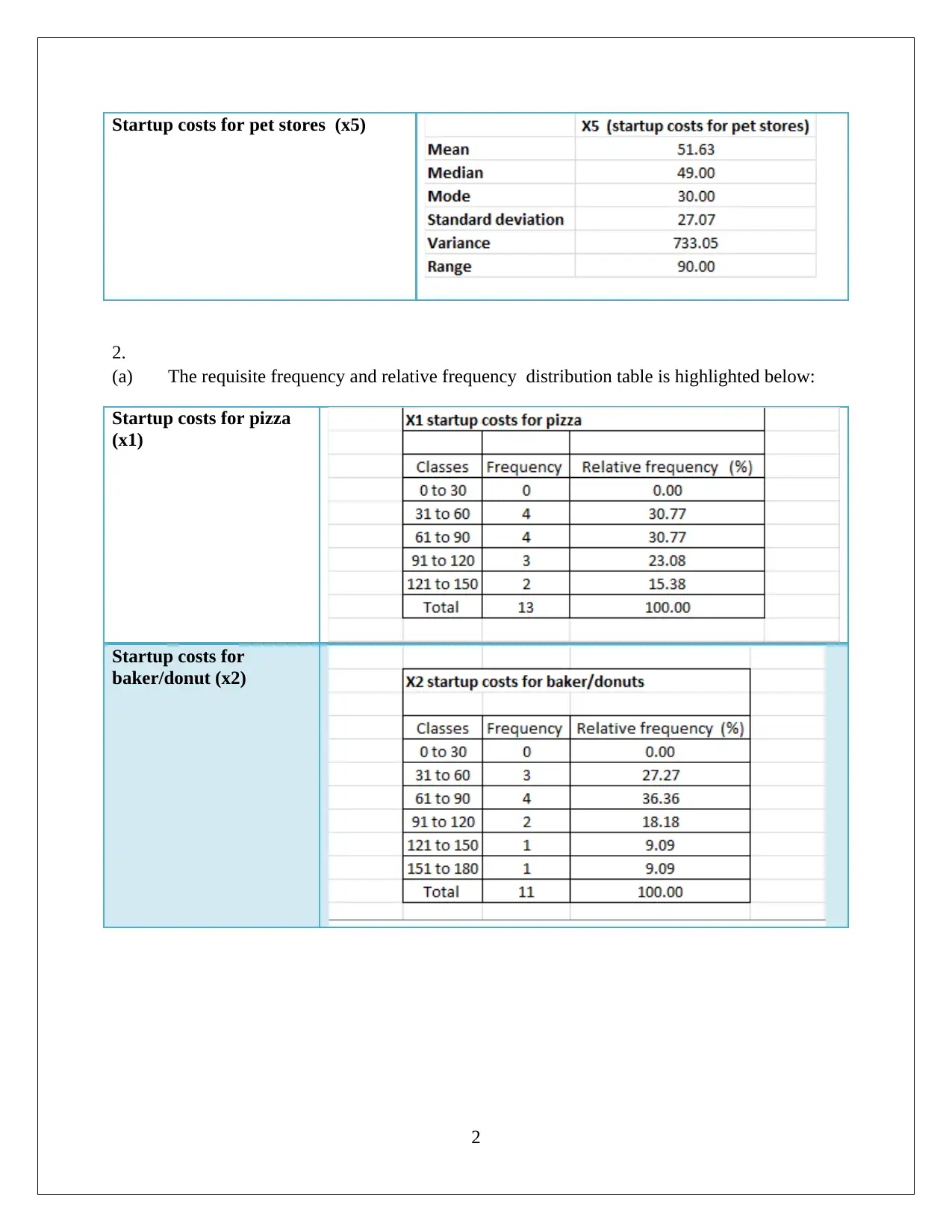
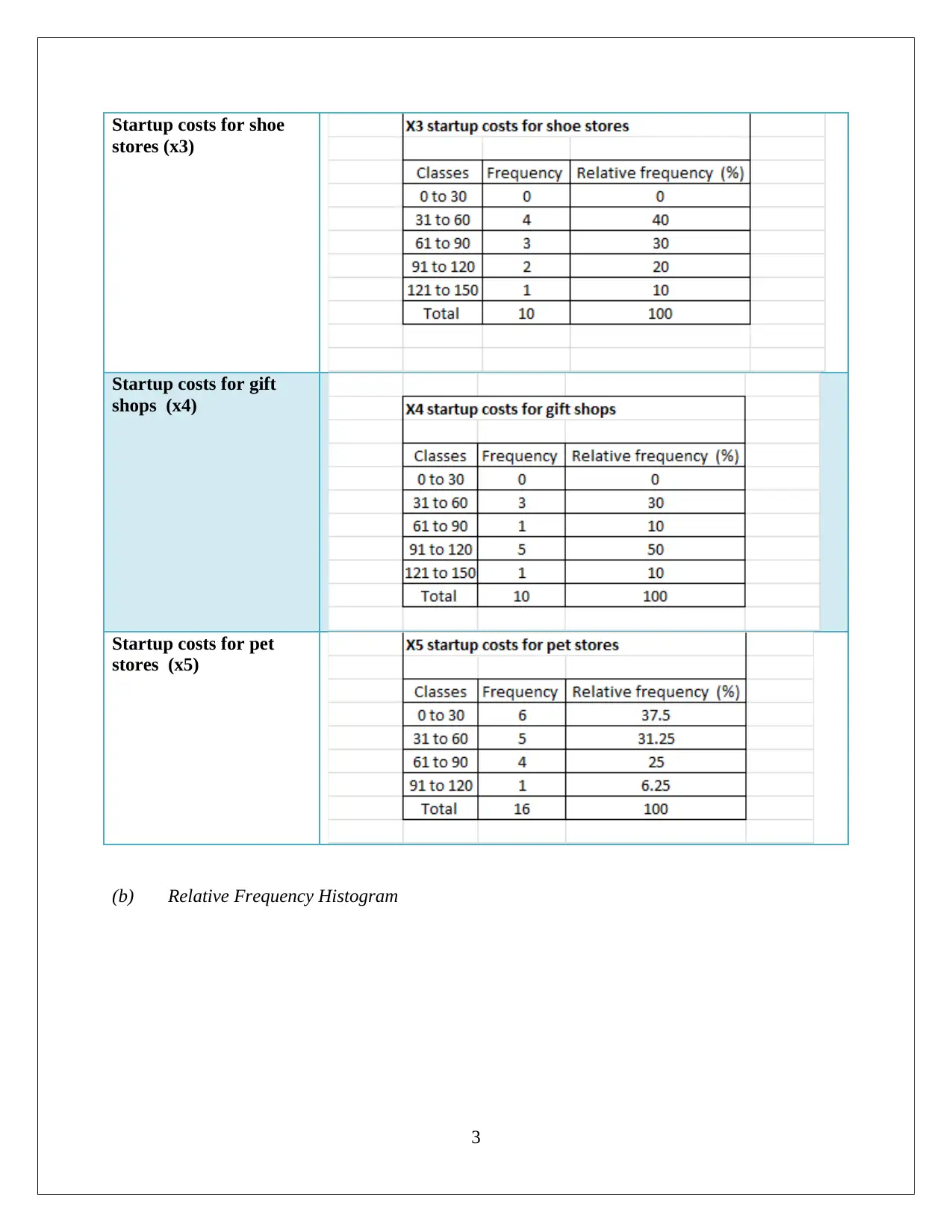
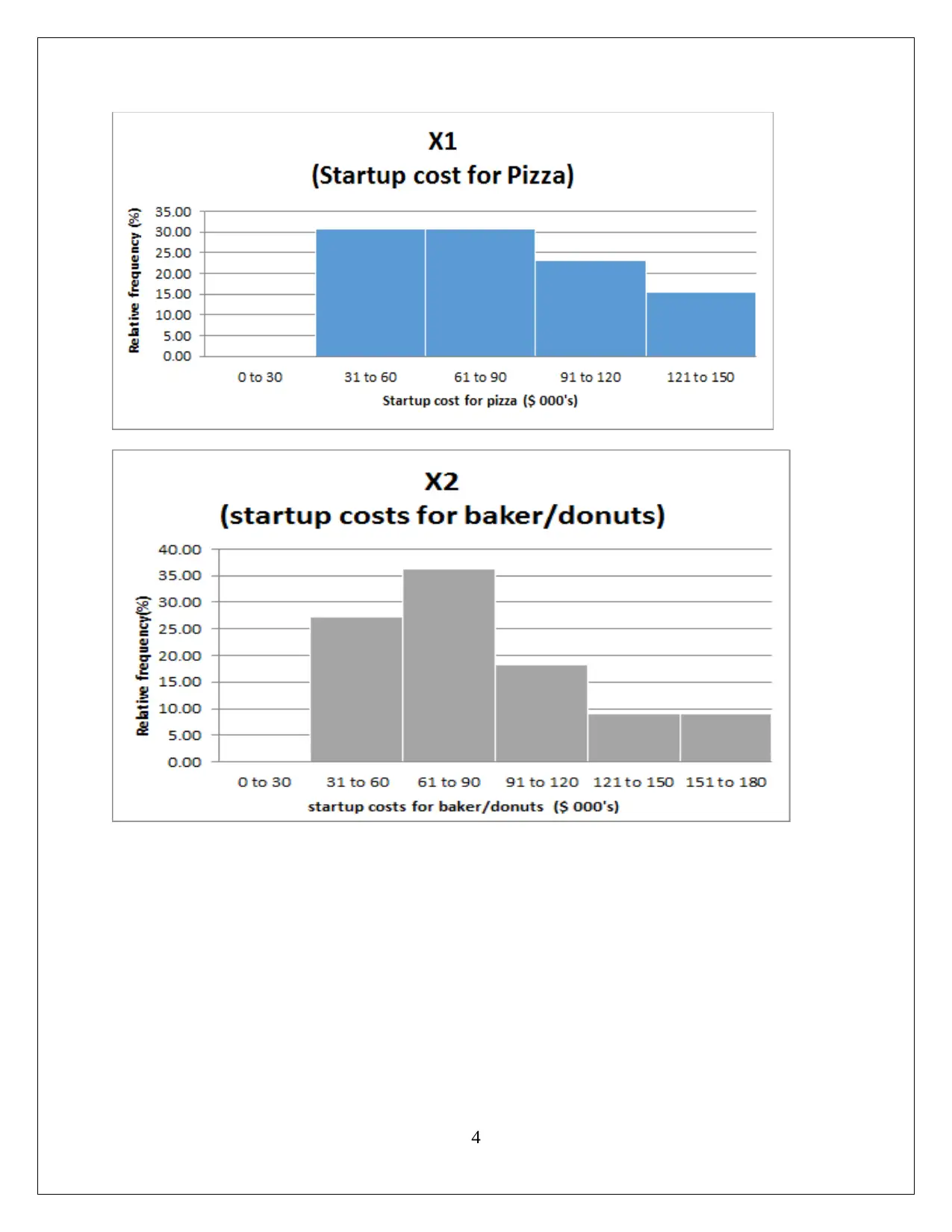
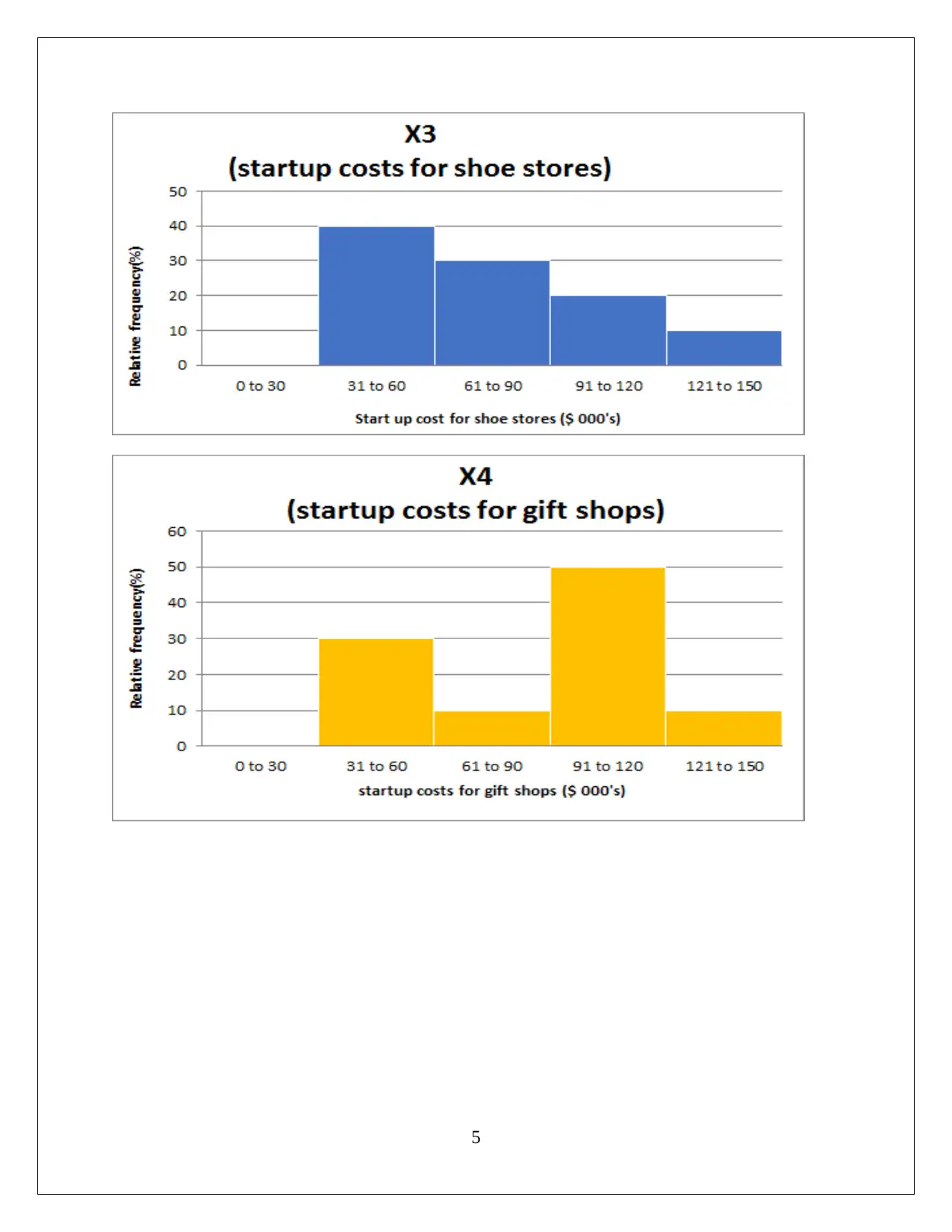
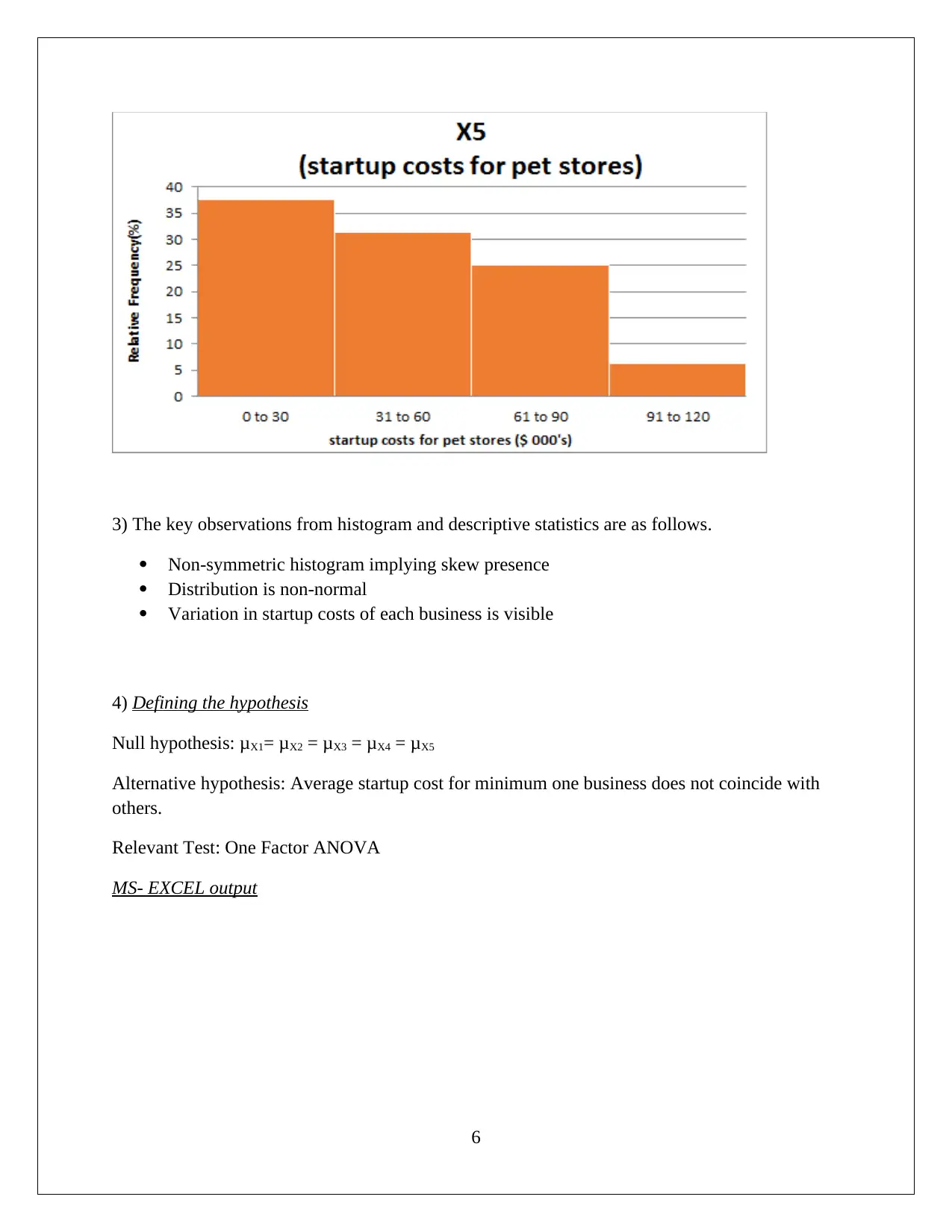
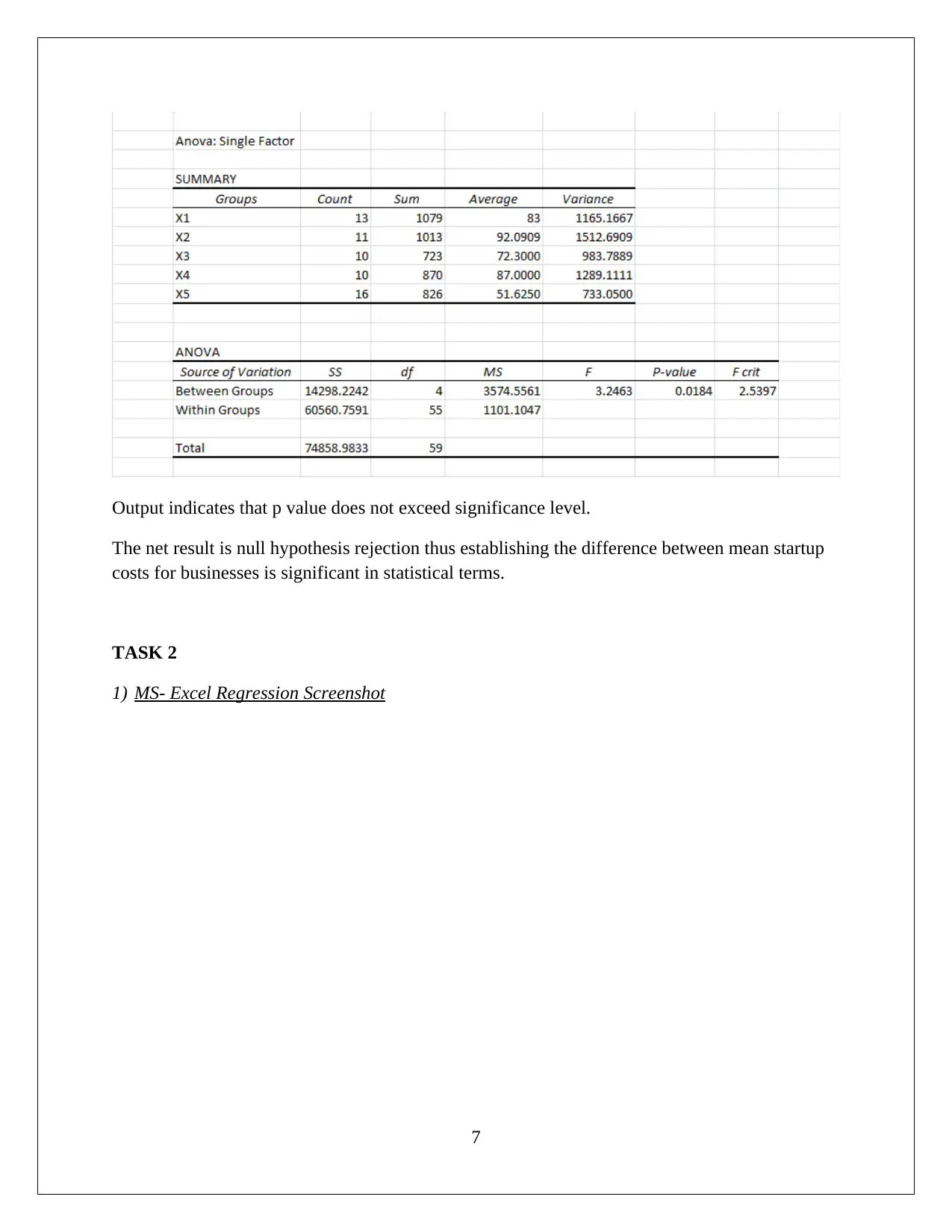
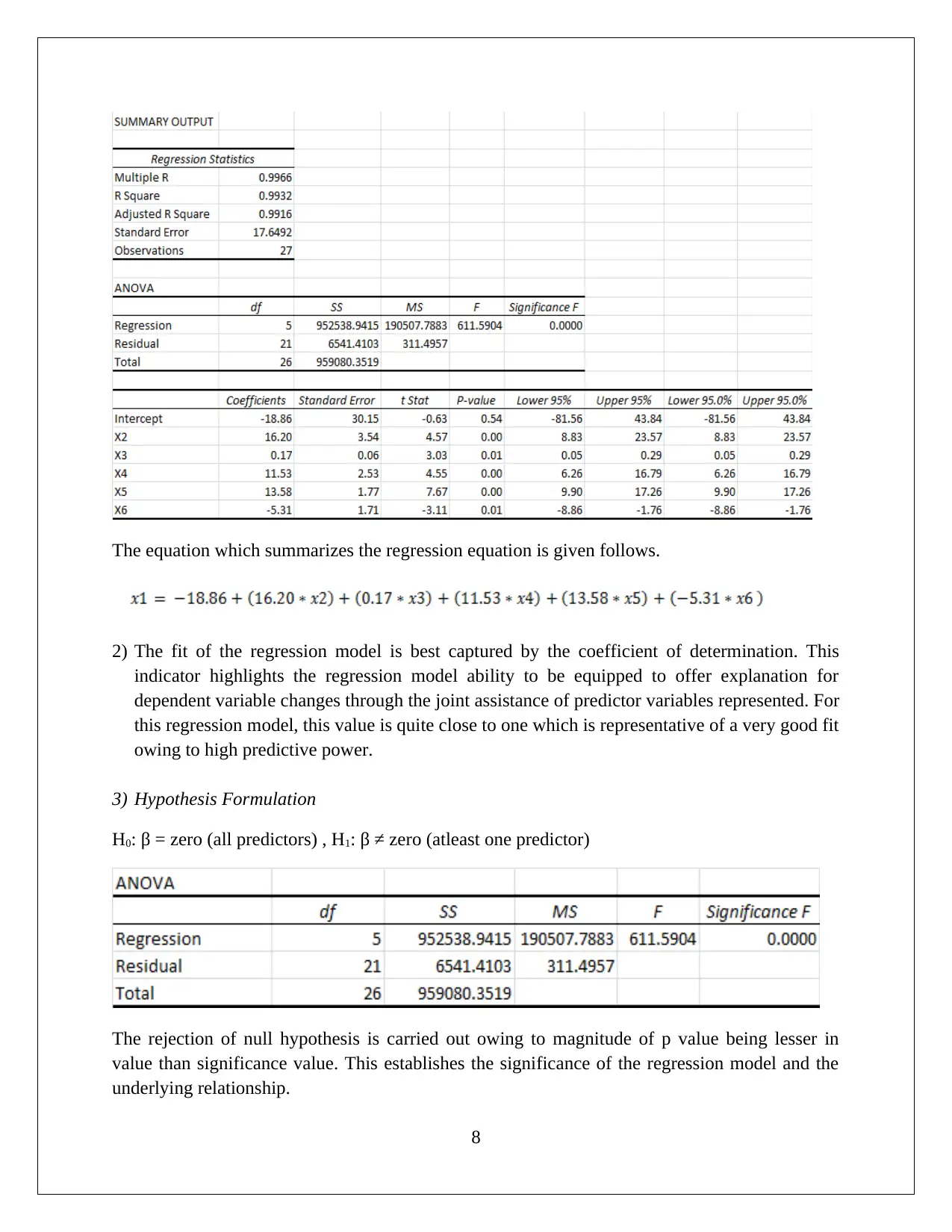
This statistics assignment delves into the analysis of startup costs across different business types using statistical methods. It involves constructing a relative frequency distribution table and interpreting a histogram to understand the distribution of startup costs. The assignment then formulates and tests hypotheses using ANOVA (Analysis of Variance) to determine if there are significant differences in the mean startup costs among various businesses. Furthermore, it utilizes regression analysis to model the relationship between variables, assesses the model's fit using the coefficient of determination, and interprets the significance of regression coefficients. The solution includes the interpretation of p-values and the formulation of null and alternative hypotheses. The assignment also includes the use of MS-Excel for data analysis and model building, providing insights into the practical application of statistical techniques in business contexts. This assignment provides a comprehensive overview of statistical analysis, hypothesis testing, and regression modeling.


1 out of 11
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.