HA1011 Applied Quantitative Methods Assignment 2 Solution, T1 2019
VerifiedAdded on 2023/03/23
|13
|1415
|20
Homework Assignment
AI Summary
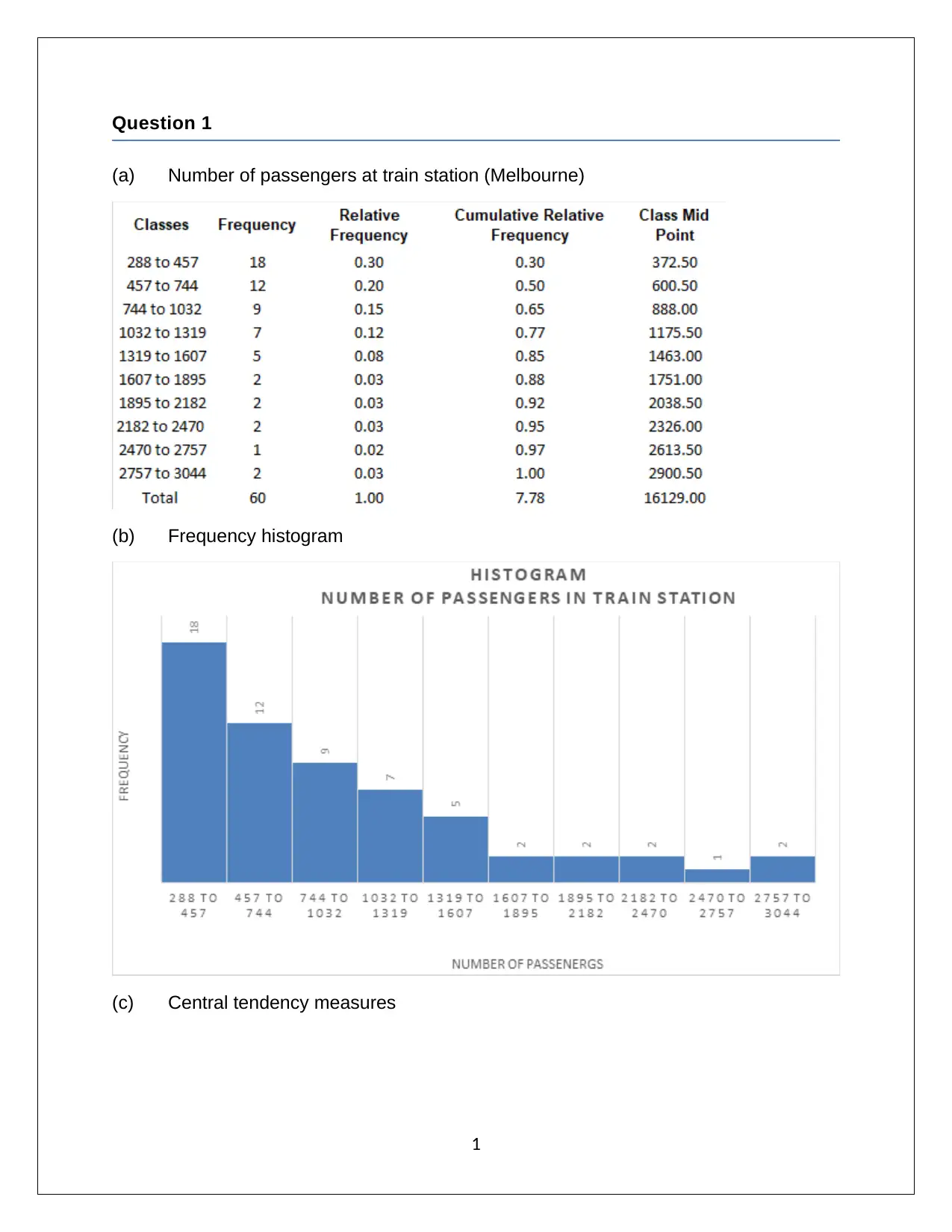
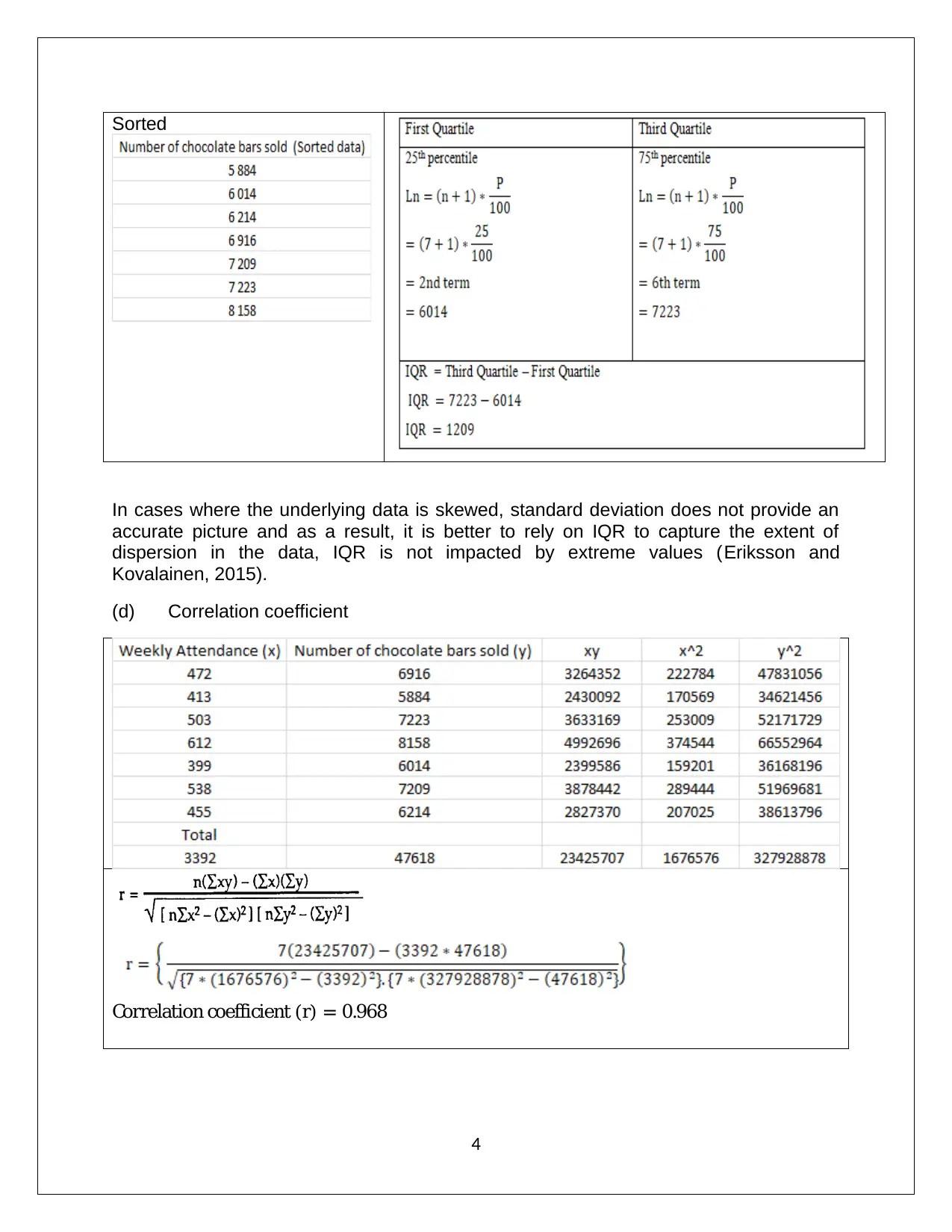
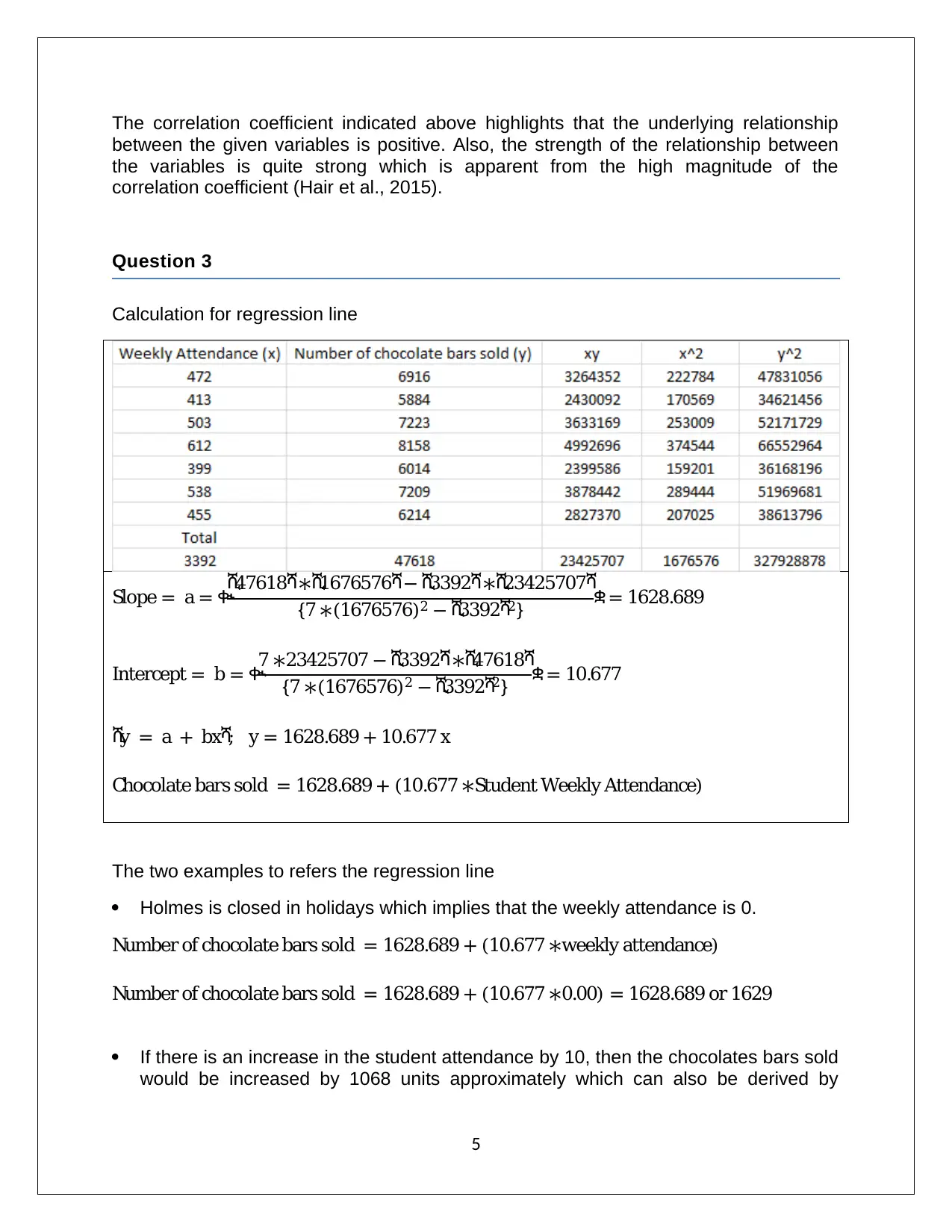
This assignment solution for Applied Quantitative Methods (HA1011) covers a range of statistical concepts and techniques. The solution includes analysis of data, frequency histograms, and measures of central tendency, along with the application of standard deviation, interquartile range, and correlation coefficients. It further delves into regression analysis, calculating the regression line and R-squared values to assess the relationship between variables. The solution also addresses probability calculations involving different scenarios, including Bayesian probability. Additionally, the assignment explores binomial and Poisson distributions, and applies the normal distribution to solve probability problems. Finally, the solution demonstrates the application of the central limit theorem and hypothesis testing to analyze sample data.









1 out of 13
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.