AI Weekly Progress Report: Artificial Intelligence Project Overview
VerifiedAdded on 2023/06/05
|13
|1904
|499
Report
AI Summary
This report details the weekly progress of an artificial intelligence project over twelve weeks. The project explores various aspects of AI, including the impact of driverless cars on insurance, the application of Robotic Process Automation (RPA), and the use of machine learning in the insurance industry. The report also covers research on Long Short-Term Memory (LSTM) networks, reinforcement learning algorithms, and the implementation of Variational Autoencoders (VAE) for data augmentation. Key milestones include identifying the effects of automated vehicles, benefits of RPA, customer need identification, and the conditioning of LSTM networks. The project also involves cloning a Snake game to a gymnasium environment, researching argument averaging strategies, and using Atari games for model conditioning. The report concludes with discussions on implementing elongated attention and the impact of various regulation procedures in Reinforcement Learning (RL) programs.

Running head: AI WEEKLY PROGRESS REPORT
AI WEEKLY PROGRESS REPORT
Name
Institution
Date
AI WEEKLY PROGRESS REPORT
Name
Institution
Date
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
AI WEEKLY PROGRESS REPORT 2
WEEKLY PROGRESS REPORT
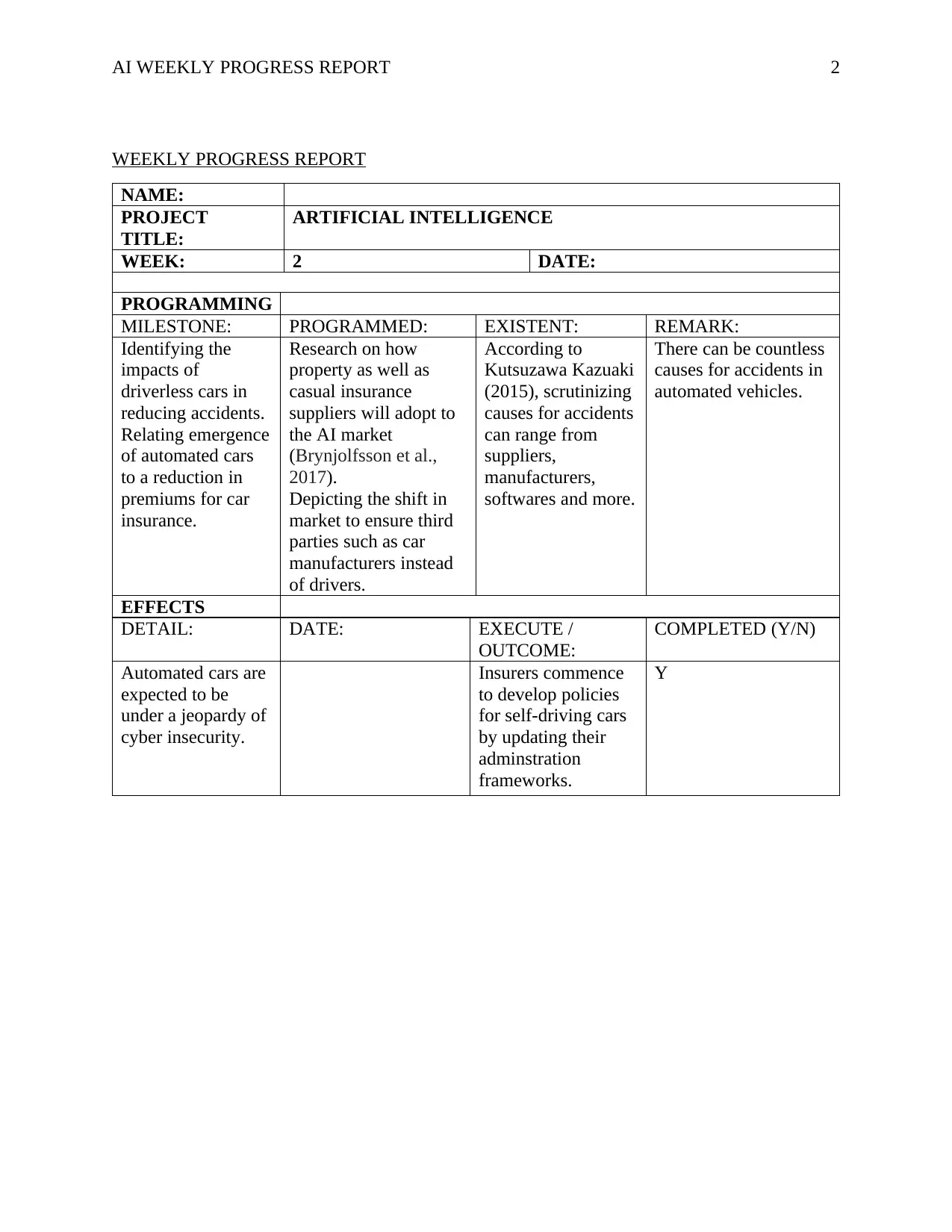
NAME:
PROJECT
TITLE:
ARTIFICIAL INTELLIGENCE
WEEK: 2 DATE:
PROGRAMMING
MILESTONE: PROGRAMMED: EXISTENT: REMARK:
Identifying the
impacts of
driverless cars in
reducing accidents.
Relating emergence
of automated cars
to a reduction in
premiums for car
insurance.
Research on how
property as well as
casual insurance
suppliers will adopt to
the AI market
(Brynjolfsson et al.,
2017).
Depicting the shift in
market to ensure third
parties such as car
manufacturers instead
of drivers.
According to
Kutsuzawa Kazuaki
(2015), scrutinizing
causes for accidents
can range from
suppliers,
manufacturers,
softwares and more.
There can be countless
causes for accidents in
automated vehicles.
EFFECTS
DETAIL: DATE: EXECUTE /
OUTCOME:
COMPLETED (Y/N)
Automated cars are
expected to be
under a jeopardy of
cyber insecurity.
Insurers commence
to develop policies
for self-driving cars
by updating their
adminstration
frameworks.
Y
WEEKLY PROGRESS REPORT
NAME:
PROJECT
TITLE:
ARTIFICIAL INTELLIGENCE
WEEK: 2 DATE:
PROGRAMMING
MILESTONE: PROGRAMMED: EXISTENT: REMARK:
Identifying the
impacts of
driverless cars in
reducing accidents.
Relating emergence
of automated cars
to a reduction in
premiums for car
insurance.
Research on how
property as well as
casual insurance
suppliers will adopt to
the AI market
(Brynjolfsson et al.,
2017).
Depicting the shift in
market to ensure third
parties such as car
manufacturers instead
of drivers.
According to
Kutsuzawa Kazuaki
(2015), scrutinizing
causes for accidents
can range from
suppliers,
manufacturers,
softwares and more.
There can be countless
causes for accidents in
automated vehicles.
EFFECTS
DETAIL: DATE: EXECUTE /
OUTCOME:
COMPLETED (Y/N)
Automated cars are
expected to be
under a jeopardy of
cyber insecurity.
Insurers commence
to develop policies
for self-driving cars
by updating their
adminstration
frameworks.
Y
AI WEEKLY PROGRESS REPORT 3
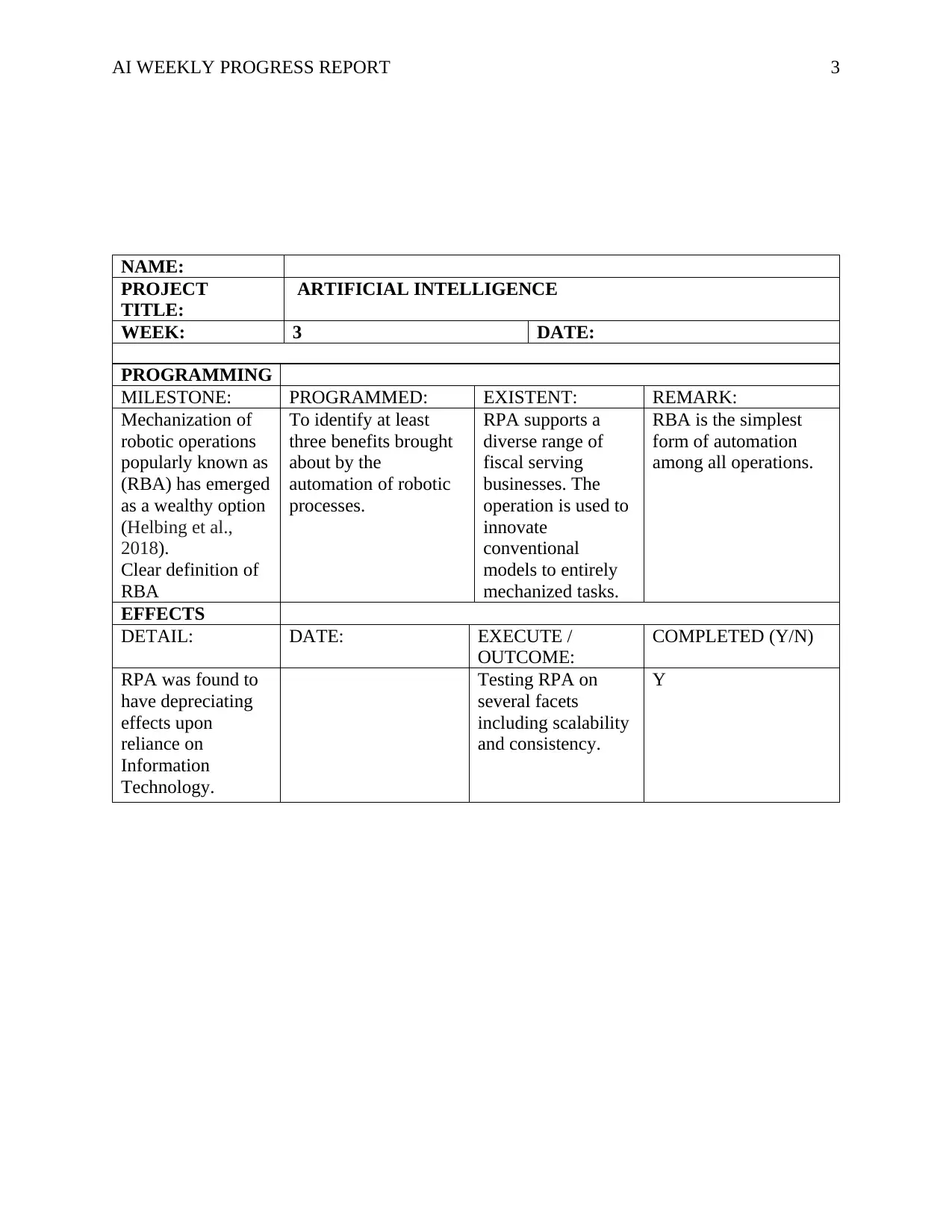
NAME:
PROJECT
TITLE:
ARTIFICIAL INTELLIGENCE
WEEK: 3 DATE:
PROGRAMMING
MILESTONE: PROGRAMMED: EXISTENT: REMARK:
Mechanization of
robotic operations
popularly known as
(RBA) has emerged
as a wealthy option
(Helbing et al.,
2018).
Clear definition of
RBA
To identify at least
three benefits brought
about by the
automation of robotic
processes.
RPA supports a
diverse range of
fiscal serving
businesses. The
operation is used to
innovate
conventional
models to entirely
mechanized tasks.
RBA is the simplest
form of automation
among all operations.
EFFECTS
DETAIL: DATE: EXECUTE /
OUTCOME:
COMPLETED (Y/N)
RPA was found to
have depreciating
effects upon
reliance on
Information
Technology.
Testing RPA on
several facets
including scalability
and consistency.
Y
NAME:
PROJECT
TITLE:
ARTIFICIAL INTELLIGENCE
WEEK: 3 DATE:
PROGRAMMING
MILESTONE: PROGRAMMED: EXISTENT: REMARK:
Mechanization of
robotic operations
popularly known as
(RBA) has emerged
as a wealthy option
(Helbing et al.,
2018).
Clear definition of
RBA
To identify at least
three benefits brought
about by the
automation of robotic
processes.
RPA supports a
diverse range of
fiscal serving
businesses. The
operation is used to
innovate
conventional
models to entirely
mechanized tasks.
RBA is the simplest
form of automation
among all operations.
EFFECTS
DETAIL: DATE: EXECUTE /
OUTCOME:
COMPLETED (Y/N)
RPA was found to
have depreciating
effects upon
reliance on
Information
Technology.
Testing RPA on
several facets
including scalability
and consistency.
Y
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
AI WEEKLY PROGRESS REPORT 4
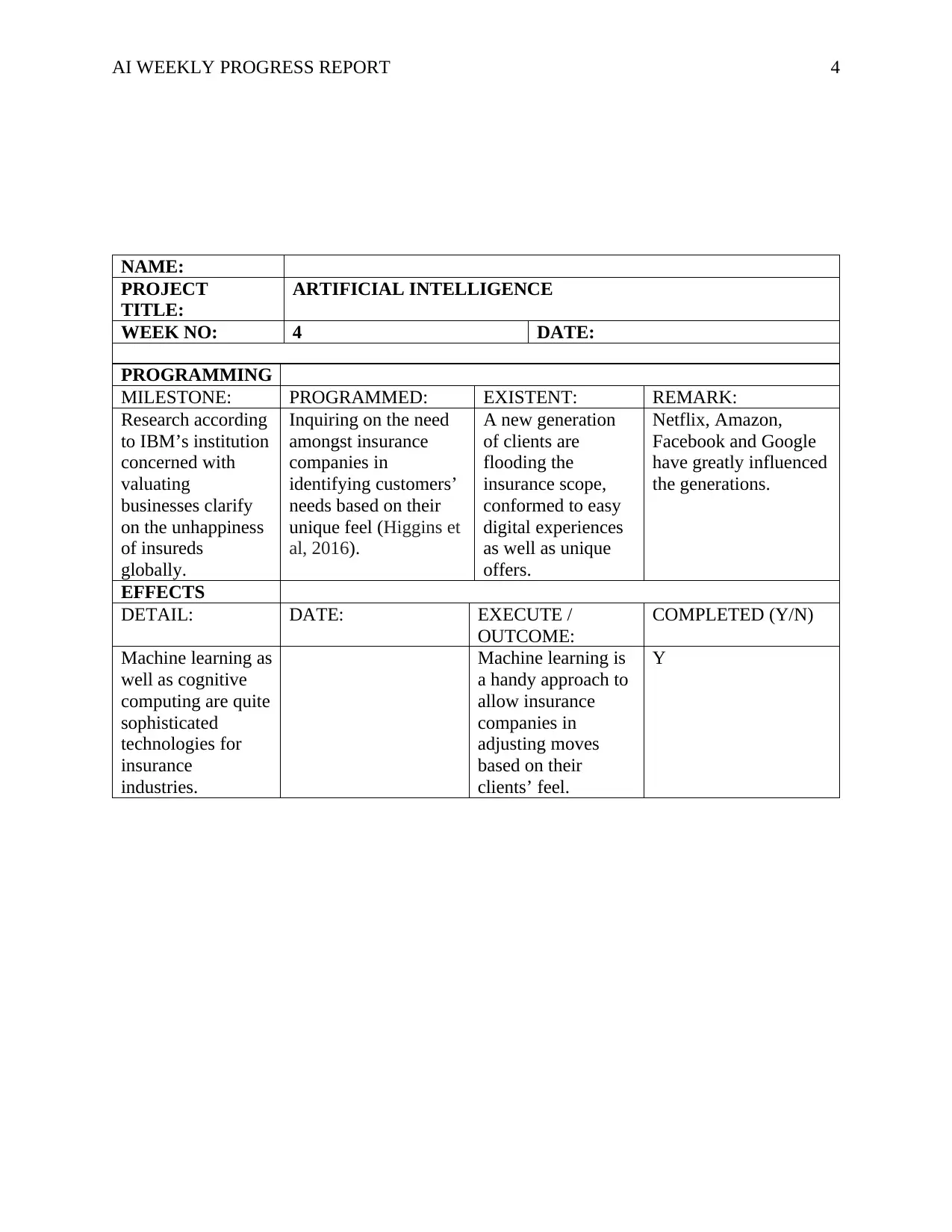
NAME:
PROJECT
TITLE:
ARTIFICIAL INTELLIGENCE
WEEK NO: 4 DATE:
PROGRAMMING
MILESTONE: PROGRAMMED: EXISTENT: REMARK:
Research according
to IBM’s institution
concerned with
valuating
businesses clarify
on the unhappiness
of insureds
globally.
Inquiring on the need
amongst insurance
companies in
identifying customers’
needs based on their
unique feel (Higgins et
al, 2016).
A new generation
of clients are
flooding the
insurance scope,
conformed to easy
digital experiences
as well as unique
offers.
Netflix, Amazon,
Facebook and Google
have greatly influenced
the generations.
EFFECTS
DETAIL: DATE: EXECUTE /
OUTCOME:
COMPLETED (Y/N)
Machine learning as
well as cognitive
computing are quite
sophisticated
technologies for
insurance
industries.
Machine learning is
a handy approach to
allow insurance
companies in
adjusting moves
based on their
clients’ feel.
Y
NAME:
PROJECT
TITLE:
ARTIFICIAL INTELLIGENCE
WEEK NO: 4 DATE:
PROGRAMMING
MILESTONE: PROGRAMMED: EXISTENT: REMARK:
Research according
to IBM’s institution
concerned with
valuating
businesses clarify
on the unhappiness
of insureds
globally.
Inquiring on the need
amongst insurance
companies in
identifying customers’
needs based on their
unique feel (Higgins et
al, 2016).
A new generation
of clients are
flooding the
insurance scope,
conformed to easy
digital experiences
as well as unique
offers.
Netflix, Amazon,
Facebook and Google
have greatly influenced
the generations.
EFFECTS
DETAIL: DATE: EXECUTE /
OUTCOME:
COMPLETED (Y/N)
Machine learning as
well as cognitive
computing are quite
sophisticated
technologies for
insurance
industries.
Machine learning is
a handy approach to
allow insurance
companies in
adjusting moves
based on their
clients’ feel.
Y
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
AI WEEKLY PROGRESS REPORT 5
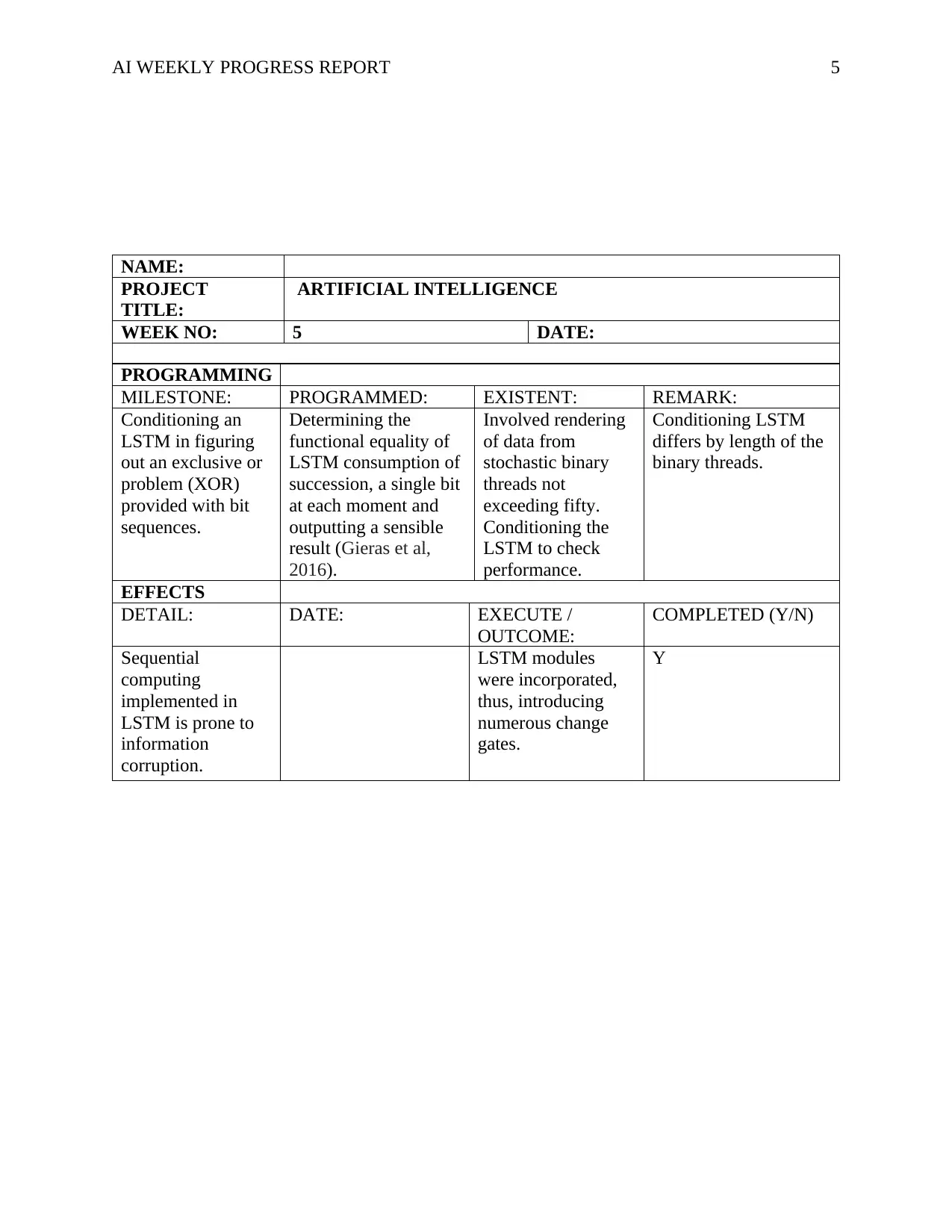
NAME:
PROJECT
TITLE:
ARTIFICIAL INTELLIGENCE
WEEK NO: 5 DATE:
PROGRAMMING
MILESTONE: PROGRAMMED: EXISTENT: REMARK:
Conditioning an
LSTM in figuring
out an exclusive or
problem (XOR)
provided with bit
sequences.
Determining the
functional equality of
LSTM consumption of
succession, a single bit
at each moment and
outputting a sensible
result (Gieras et al,
2016).
Involved rendering
of data from
stochastic binary
threads not
exceeding fifty.
Conditioning the
LSTM to check
performance.
Conditioning LSTM
differs by length of the
binary threads.
EFFECTS
DETAIL: DATE: EXECUTE /
OUTCOME:
COMPLETED (Y/N)
Sequential
computing
implemented in
LSTM is prone to
information
corruption.
LSTM modules
were incorporated,
thus, introducing
numerous change
gates.
Y
NAME:
PROJECT
TITLE:
ARTIFICIAL INTELLIGENCE
WEEK NO: 5 DATE:
PROGRAMMING
MILESTONE: PROGRAMMED: EXISTENT: REMARK:
Conditioning an
LSTM in figuring
out an exclusive or
problem (XOR)
provided with bit
sequences.
Determining the
functional equality of
LSTM consumption of
succession, a single bit
at each moment and
outputting a sensible
result (Gieras et al,
2016).
Involved rendering
of data from
stochastic binary
threads not
exceeding fifty.
Conditioning the
LSTM to check
performance.
Conditioning LSTM
differs by length of the
binary threads.
EFFECTS
DETAIL: DATE: EXECUTE /
OUTCOME:
COMPLETED (Y/N)
Sequential
computing
implemented in
LSTM is prone to
information
corruption.
LSTM modules
were incorporated,
thus, introducing
numerous change
gates.
Y
AI WEEKLY PROGRESS REPORT 6
NAME:
PROJECT
TITLE:
ARTIFICIAL INTELLIGENCE
WEEK NO: 6 DATE:
PROGRAMMING
MILESTONE: PROGRAMMED: EXISTENT: REMARK:
Cloning a previous
Snake game to a
gymnasium
surrounding as well
as resolving it in
algorithms of
reinforcement
learning (Huang et
al, 2016).
The research aimed to
design policies in the
game that could
ascertain winning.
It involved three
parts including
environment, agent
and scrutiny of the
acquired doings.
The snake had to
acquire various abilities
to ascertain workability
of algorithm.
EFFECTS
DETAIL: DATE: EXECUTE /
OUTCOME:
COMPLETED (Y/N)
The method
employed required
experimenting with
numerous
approaches in a
self-play manner.
The agent learnt to
assail, ambush and
gang against other
snakes. Similarly, it
entirely managed to
pursue food.
Y
NAME:
PROJECT
TITLE:
ARTIFICIAL INTELLIGENCE
WEEK NO: 6 DATE:
PROGRAMMING
MILESTONE: PROGRAMMED: EXISTENT: REMARK:
Cloning a previous
Snake game to a
gymnasium
surrounding as well
as resolving it in
algorithms of
reinforcement
learning (Huang et
al, 2016).
The research aimed to
design policies in the
game that could
ascertain winning.
It involved three
parts including
environment, agent
and scrutiny of the
acquired doings.
The snake had to
acquire various abilities
to ascertain workability
of algorithm.
EFFECTS
DETAIL: DATE: EXECUTE /
OUTCOME:
COMPLETED (Y/N)
The method
employed required
experimenting with
numerous
approaches in a
self-play manner.
The agent learnt to
assail, ambush and
gang against other
snakes. Similarly, it
entirely managed to
pursue food.
Y
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
AI WEEKLY PROGRESS REPORT 7
NAME:
PROJECT
TITLE:
ARTIFICIAL INTELLIGENCE
WEEK NO: 7 DATE:
PROGRAMMING
MILESTONE: PROGRAMMED: EXISTENT: REMARK:
Researching about
the impacts of
argument averaging
out strategies
sampling
distribution as well
as a level of
correspondence in
RL algorithm.
Finding the simplest
result by averaging
slopes of each user on
each instance of
upgrade.
Possibility to save
on bandwidth costs
by communication
is found from
upgrading users
separately from
average arguments.
Reinforcement
Learning can be
optimized by increasing
arguments. Similarly,
implementing rules
such as EASGD
increase linked between
arguments.
EFFECTS
DETAIL: DATE: EXECUTE /
OUTCOME:
COMPLETED (Y/N)
RL algorithms is
claimed not to be
working despite
being followed with
a hype of a program
best in all.
Implementing RL
algorithms using
reward procedures
can be used to
eliminated
bothersome
dispositions.
Y
NAME:
PROJECT
TITLE:
ARTIFICIAL INTELLIGENCE
WEEK NO: 7 DATE:
PROGRAMMING
MILESTONE: PROGRAMMED: EXISTENT: REMARK:
Researching about
the impacts of
argument averaging
out strategies
sampling
distribution as well
as a level of
correspondence in
RL algorithm.
Finding the simplest
result by averaging
slopes of each user on
each instance of
upgrade.
Possibility to save
on bandwidth costs
by communication
is found from
upgrading users
separately from
average arguments.
Reinforcement
Learning can be
optimized by increasing
arguments. Similarly,
implementing rules
such as EASGD
increase linked between
arguments.
EFFECTS
DETAIL: DATE: EXECUTE /
OUTCOME:
COMPLETED (Y/N)
RL algorithms is
claimed not to be
working despite
being followed with
a hype of a program
best in all.
Implementing RL
algorithms using
reward procedures
can be used to
eliminated
bothersome
dispositions.
Y
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
AI WEEKLY PROGRESS REPORT 8
NAME:
PROJECT
TITLE:
ARTIFICIAL INTELLIGENCE
WEEK NO: 8 DATE:
PROGRAMMING
MILESTONE: PROGRAMMED: EXISTENT: REMARK:
Use Atari games to
condition more than
ten adept
assurances. The
move requires
generation of
around ten
thousand directions
of one thousand
treads.
Fitting a procreative
framework from an
example including
Transformer to the path
followed by objects as
acquired in the ten
games
The eleven game
could be tuned up
using the models
from ten games. As
such, quantification
based on pre-
training the games
were derived.
The size of the model
determines the
usefulness of the
conditioning process.
EFFECTS
DETAIL: DATE: EXECUTE /
OUTCOME:
COMPLETED (Y/N)
The method
involves fallacies of
planning which
insinuates that
completion will
always be long
overdue.
So as to reduce the
size and time
consumed by
transferring data, a
pre-condition model
is employed
minimizes by ten
times.
Y
NAME:
PROJECT
TITLE:
ARTIFICIAL INTELLIGENCE
WEEK NO: 8 DATE:
PROGRAMMING
MILESTONE: PROGRAMMED: EXISTENT: REMARK:
Use Atari games to
condition more than
ten adept
assurances. The
move requires
generation of
around ten
thousand directions
of one thousand
treads.
Fitting a procreative
framework from an
example including
Transformer to the path
followed by objects as
acquired in the ten
games
The eleven game
could be tuned up
using the models
from ten games. As
such, quantification
based on pre-
training the games
were derived.
The size of the model
determines the
usefulness of the
conditioning process.
EFFECTS
DETAIL: DATE: EXECUTE /
OUTCOME:
COMPLETED (Y/N)
The method
involves fallacies of
planning which
insinuates that
completion will
always be long
overdue.
So as to reduce the
size and time
consumed by
transferring data, a
pre-condition model
is employed
minimizes by ten
times.
Y
AI WEEKLY PROGRESS REPORT 9
NAME:
PROJECT TITLE: ARTIFICIAL INTELLIGENCE
WEEK NO: 9 DATE:
PROGRAMMING
MILESTONE: PROGRAMMED: EXISTENT: REMARK:
Instead of
implementing the
Transformer
framework using
soft attention,
implement
elongated attention
since it can be
changed into
Recurrent Neural
Networks (RNN)
Choosing amid
language framework
activities, conditioning
the transformer as well
as finding means to
retrieve similar bits per
word by utilising an
elongated-attention
transformer and
distinct arguments
(Mnih, et al, 2015).
Transformers
implementing
elongated attention
need advanced
identification and
content arrays
compared to
softmax using care.
Linear attention is done
without the need to
increase number of
arguments.
EFFECTS
DETAIL: DATE: EXECUTE /
OUTCOME:
COMPLETED (Y/N)
Using a
Reinforcement
Learning (RL)
framework,
especially
straighten it to the
transformer across a
diverse setting is
impossible.
Strengthening the
linear attention
method is efficient
for attaining
required results.
Y
NAME:
PROJECT TITLE: ARTIFICIAL INTELLIGENCE
WEEK NO: 9 DATE:
PROGRAMMING
MILESTONE: PROGRAMMED: EXISTENT: REMARK:
Instead of
implementing the
Transformer
framework using
soft attention,
implement
elongated attention
since it can be
changed into
Recurrent Neural
Networks (RNN)
Choosing amid
language framework
activities, conditioning
the transformer as well
as finding means to
retrieve similar bits per
word by utilising an
elongated-attention
transformer and
distinct arguments
(Mnih, et al, 2015).
Transformers
implementing
elongated attention
need advanced
identification and
content arrays
compared to
softmax using care.
Linear attention is done
without the need to
increase number of
arguments.
EFFECTS
DETAIL: DATE: EXECUTE /
OUTCOME:
COMPLETED (Y/N)
Using a
Reinforcement
Learning (RL)
framework,
especially
straighten it to the
transformer across a
diverse setting is
impossible.
Strengthening the
linear attention
method is efficient
for attaining
required results.
Y
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
AI WEEKLY PROGRESS REPORT 10
NAME:
PROJECT
TITLE:
ARTIFICIAL INTELLIGENCE
WEEK NO: 10 DATE:
PLANNING
MILESTONE: PROGRAMMED: EXISTENT: REMARK:
Leaning a
Variational
Autoencoder
(VAE) of
information so
as to conduct
augmentation
(Russell &
Norvig, 2016).
The neural
network assists
in generating
complex
frameworks
with regard to
data sets.
The aim was to
condition VAE using
input data. The
conditioning detail
ought to be transformed
through converting to an
inactive space and
reverting it into output.
The method accrued
to enhanced
generalization as an
advantage of
information
augmentation.
Similarly, it uses
numerous
transformation and
alters lightning
aspect.
VAE implements three
components including
an encoder, decoder as
well as a loss
subroutine.
EFFECTS
DETAIL: DATE: EXECUTE /
OUTCOME:
COMPLETED (Y/N)
VAE poses
technological
sophistication
thence, created
potential tracts
as a powerful
and essential
strategical
technique.
Development of
frameworks of
eminent esteem
results to decision
based advantages.
Y
NAME:
PROJECT
TITLE:
ARTIFICIAL INTELLIGENCE
WEEK NO: 10 DATE:
PLANNING
MILESTONE: PROGRAMMED: EXISTENT: REMARK:
Leaning a
Variational
Autoencoder
(VAE) of
information so
as to conduct
augmentation
(Russell &
Norvig, 2016).
The neural
network assists
in generating
complex
frameworks
with regard to
data sets.
The aim was to
condition VAE using
input data. The
conditioning detail
ought to be transformed
through converting to an
inactive space and
reverting it into output.
The method accrued
to enhanced
generalization as an
advantage of
information
augmentation.
Similarly, it uses
numerous
transformation and
alters lightning
aspect.
VAE implements three
components including
an encoder, decoder as
well as a loss
subroutine.
EFFECTS
DETAIL: DATE: EXECUTE /
OUTCOME:
COMPLETED (Y/N)
VAE poses
technological
sophistication
thence, created
potential tracts
as a powerful
and essential
strategical
technique.
Development of
frameworks of
eminent esteem
results to decision
based advantages.
Y
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
AI WEEKLY PROGRESS REPORT 11
NAME:
PROJECT
TITLE:
ARTIFICIAL INTELLIGENCE
WEEK NO: 11 DATE:
PLANNING
MILESTONE: PROGRAMMED: EXISTENT: REMARK:
Empirical
inspection as
well as
qualitative
explanation of
the impacts
behind various
regulation
procedures on a
selected
Reinforcement
Learning
program
Through a monitored
deep learning,
regulation is
exceedingly significant
to enhance rendering
functions using methods
including dropout, L2
regulation as well as
batch normalization
(Riikkinen et al, 2018).
Q-learning and
policy slopes are
algorithms used to
learn however not
very beneficial with
regards to regulation.
Developers should use
little models in
Reinforcement Learning
compared to monitored
learning since larger
frameworks project poor
performances.
EFFECTS
DETAIL: DATE: EXECUTE /
OUTCOME:
COMPLETED (Y/N)
Overfitting of
large models
cause poor
performance.
Implementing small
frameworks of RL
and not in monitored
learning.
Y
NAME:
PROJECT
TITLE:
ARTIFICIAL INTELLIGENCE
WEEK NO: 11 DATE:
PLANNING
MILESTONE: PROGRAMMED: EXISTENT: REMARK:
Empirical
inspection as
well as
qualitative
explanation of
the impacts
behind various
regulation
procedures on a
selected
Reinforcement
Learning
program
Through a monitored
deep learning,
regulation is
exceedingly significant
to enhance rendering
functions using methods
including dropout, L2
regulation as well as
batch normalization
(Riikkinen et al, 2018).
Q-learning and
policy slopes are
algorithms used to
learn however not
very beneficial with
regards to regulation.
Developers should use
little models in
Reinforcement Learning
compared to monitored
learning since larger
frameworks project poor
performances.
EFFECTS
DETAIL: DATE: EXECUTE /
OUTCOME:
COMPLETED (Y/N)
Overfitting of
large models
cause poor
performance.
Implementing small
frameworks of RL
and not in monitored
learning.
Y

AI WEEKLY PROGRESS REPORT 12
References
Brynjolfsson, E., Rock, D., & Syverson, C. (2017). Artificial intelligence and the modern
productivity paradox: A clash of expectations and statistics. In Economics of Artificial
Intelligence. University of Chicago Press.
Gieras, J. F., Piech, Z. J., & Tomczuk, B. (2016). Linear synchronous motors: transportation
and automation systems. CRC press.
Helbing, D., Frey, B. S., Gigerenzer, G., Hafen, E., Hagner, M., Hofstetter, Y., ... & Zwitter, A.
(2018). Will democracy survive big data and artificial intelligence?. In Towards Digital
Enlightenment (pp. 73-98). Springer, Cham.
Higgins, I., Matthey, L., Pal, A., Burgess, C., Glorot, X., Botvinick, M., ... & Lerchner, A.
(2016). beta-vae: Learning basic visual concepts with a constrained variational
framework.
Huang, Z., Xu, W., & Yu, K. (2015). Bidirectional LSTM-CRF models for sequence
tagging. arXiv preprint arXiv:1508.01991.
Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., ... & Petersen,
S. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540),
529.
Riikkinen, M., Saarijärvi, H., Sarlin, P., & Lähteenmäki, I. (2018). Using artificial intelligence to
create value in insurance. International Journal of Bank Marketing.
References
Brynjolfsson, E., Rock, D., & Syverson, C. (2017). Artificial intelligence and the modern
productivity paradox: A clash of expectations and statistics. In Economics of Artificial
Intelligence. University of Chicago Press.
Gieras, J. F., Piech, Z. J., & Tomczuk, B. (2016). Linear synchronous motors: transportation
and automation systems. CRC press.
Helbing, D., Frey, B. S., Gigerenzer, G., Hafen, E., Hagner, M., Hofstetter, Y., ... & Zwitter, A.
(2018). Will democracy survive big data and artificial intelligence?. In Towards Digital
Enlightenment (pp. 73-98). Springer, Cham.
Higgins, I., Matthey, L., Pal, A., Burgess, C., Glorot, X., Botvinick, M., ... & Lerchner, A.
(2016). beta-vae: Learning basic visual concepts with a constrained variational
framework.
Huang, Z., Xu, W., & Yu, K. (2015). Bidirectional LSTM-CRF models for sequence
tagging. arXiv preprint arXiv:1508.01991.
Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., ... & Petersen,
S. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540),
529.
Riikkinen, M., Saarijärvi, H., Sarlin, P., & Lähteenmäki, I. (2018). Using artificial intelligence to
create value in insurance. International Journal of Bank Marketing.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 13
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.