Detailed Report on Statistical Analysis of Asian and French Cuisine
VerifiedAdded on 2023/06/10
|11
|1993
|190
Report
AI Summary
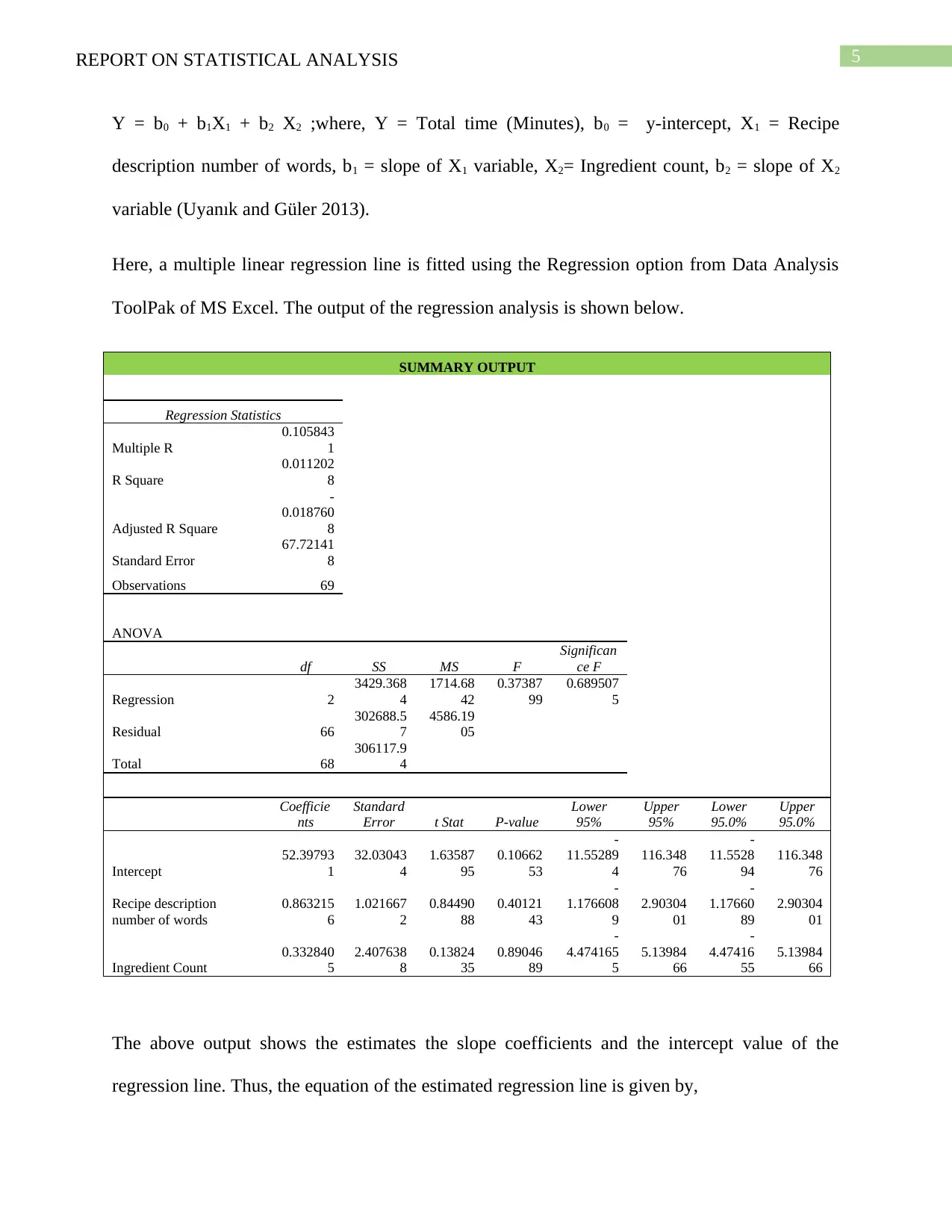
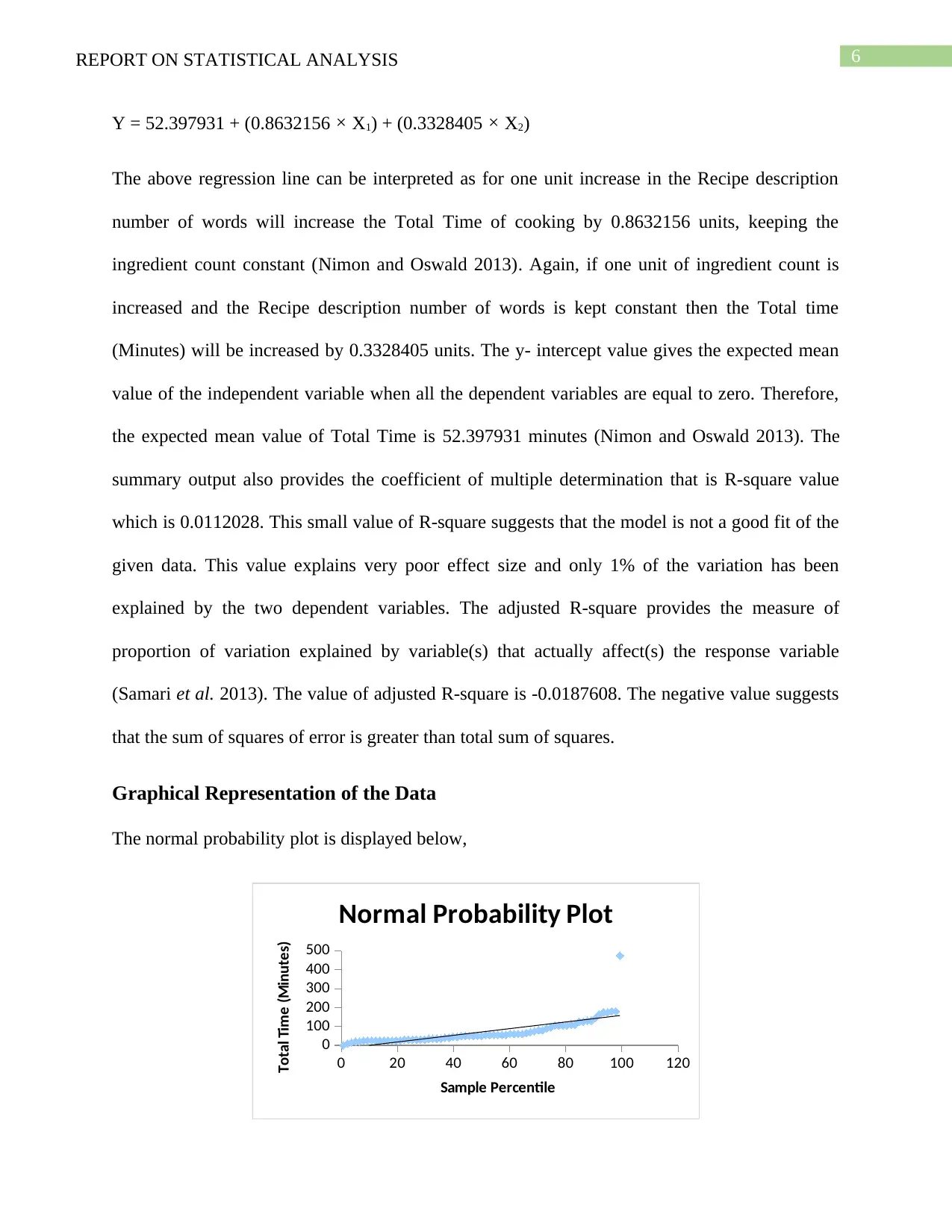
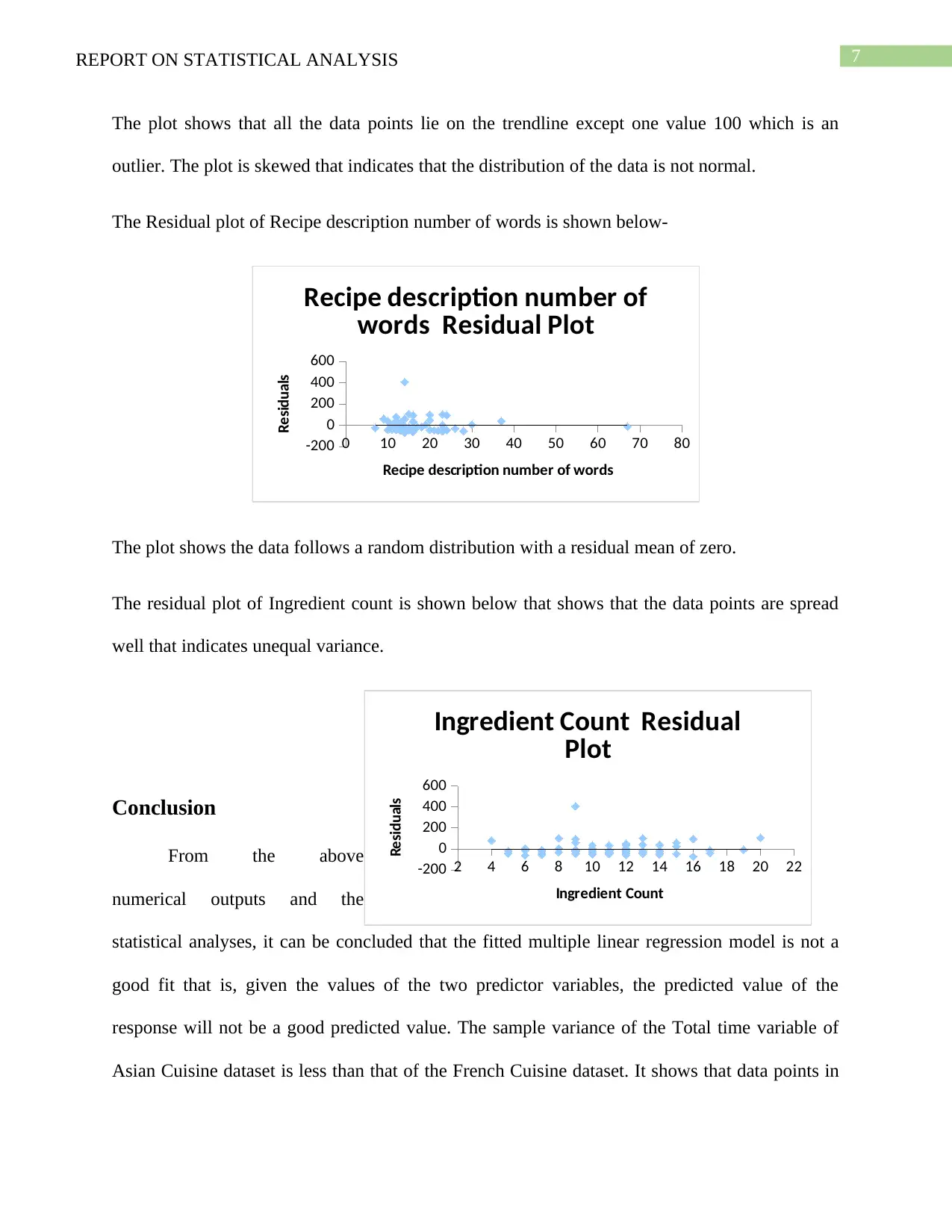
This report presents a statistical analysis of cuisine data collected from taste.com.au in 2018, focusing on Asian and French cuisines. The analysis includes descriptive statistics for variables like 'Total Time,' revealing insights into the distribution and variance of cooking times for both cuisine types. Multiple linear regression is employed to assess the impact of 'Recipe description number of words' and 'Ingredient count' on 'Total time,' although the model demonstrates a poor fit. Graphical representations, including normal probability plots and residual plots, further illustrate data characteristics and model limitations. The report concludes that while changes in recipe description length and ingredient count do affect total cooking time, the effect is not statistically significant, and the fitted regression model is not a reliable predictor.








1 out of 11
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.