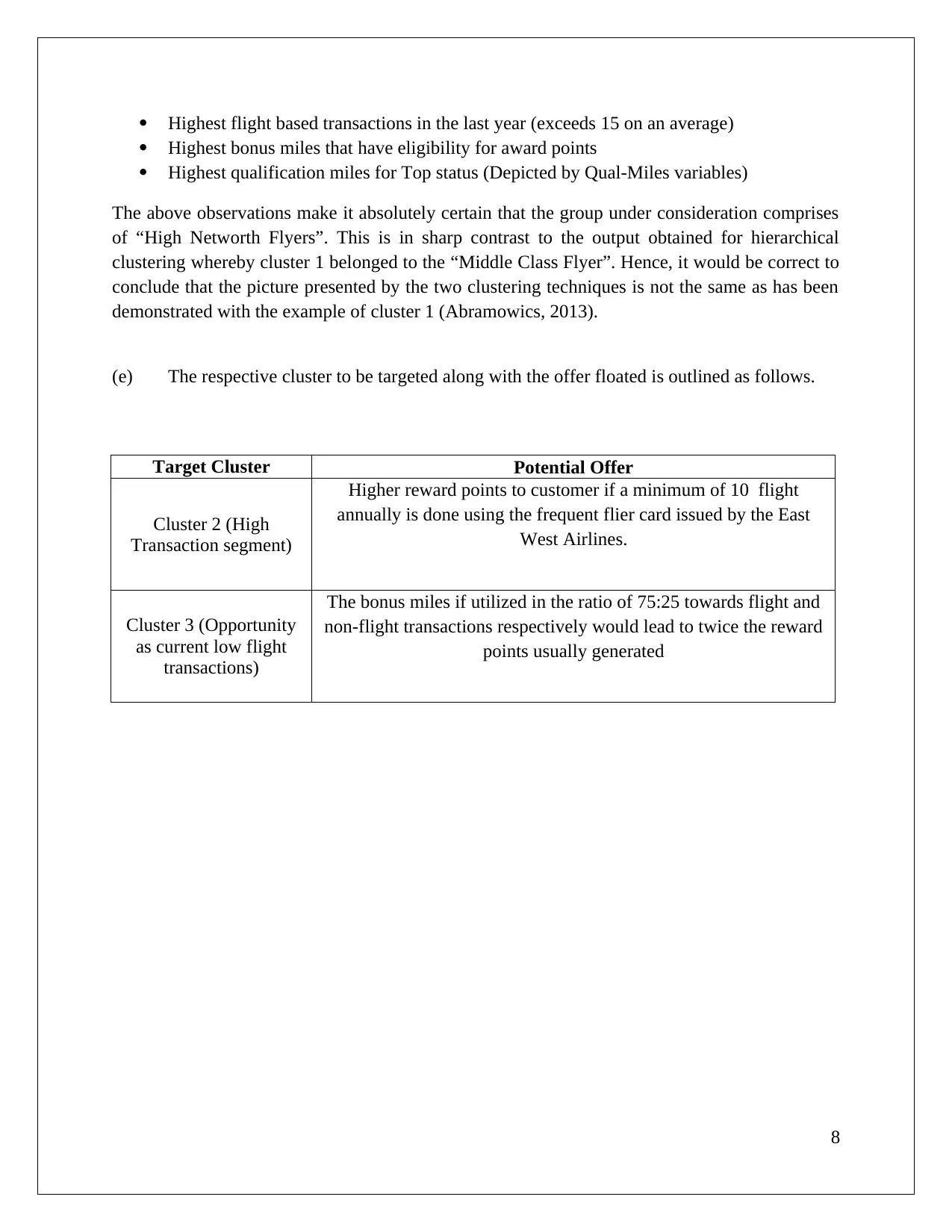
Comparative Analysis of Clustering Techniques in Business Applications
VerifiedAdded on 2020/05/11
|10
|1748
|51
AI Summary
The assignment presents an analytical approach to understanding association rule algorithms within the domain of data mining, focusing on their application in deriving meaningful business insights from transaction datasets. A significant portion is dedicated to evaluating two clustering techniques: hierarchical clustering and K-Means clustering, applied to an airline customer dataset. The objective is to determine how different methodologies categorize customers based on spending behavior and travel frequency. This comparative analysis highlights the varying outcomes of each technique and their implications for business strategy. Additionally, strategic offers tailored to specific customer clusters identified by these methods are proposed, illustrating a practical application of data mining in enhancing business intelligence efforts.





1 out of 10
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.