Data Mining Assignment - Analysis of Association Rules and Clusters
VerifiedAdded on 2020/03/16
|4
|433
|163
Homework Assignment
AI Summary
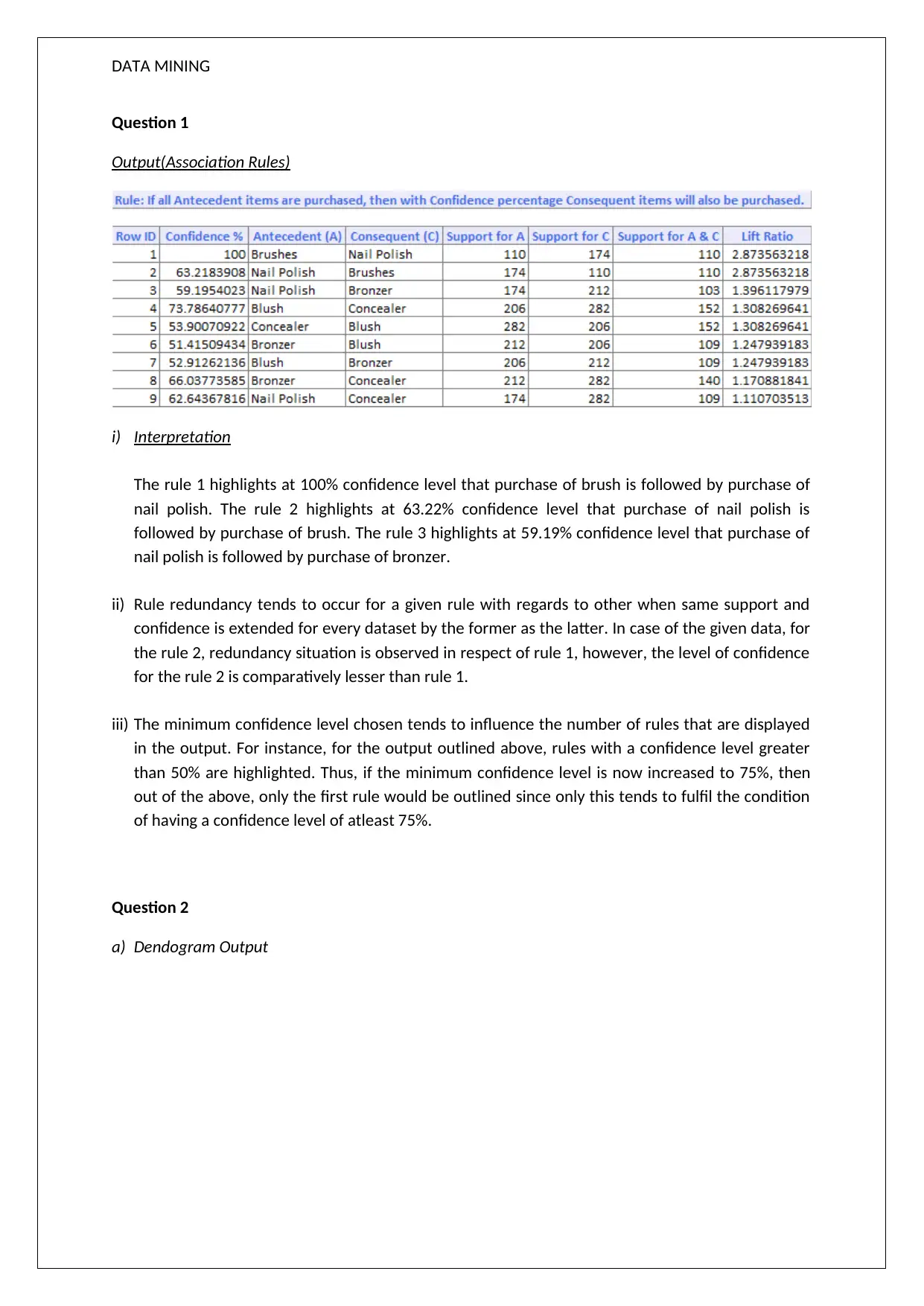
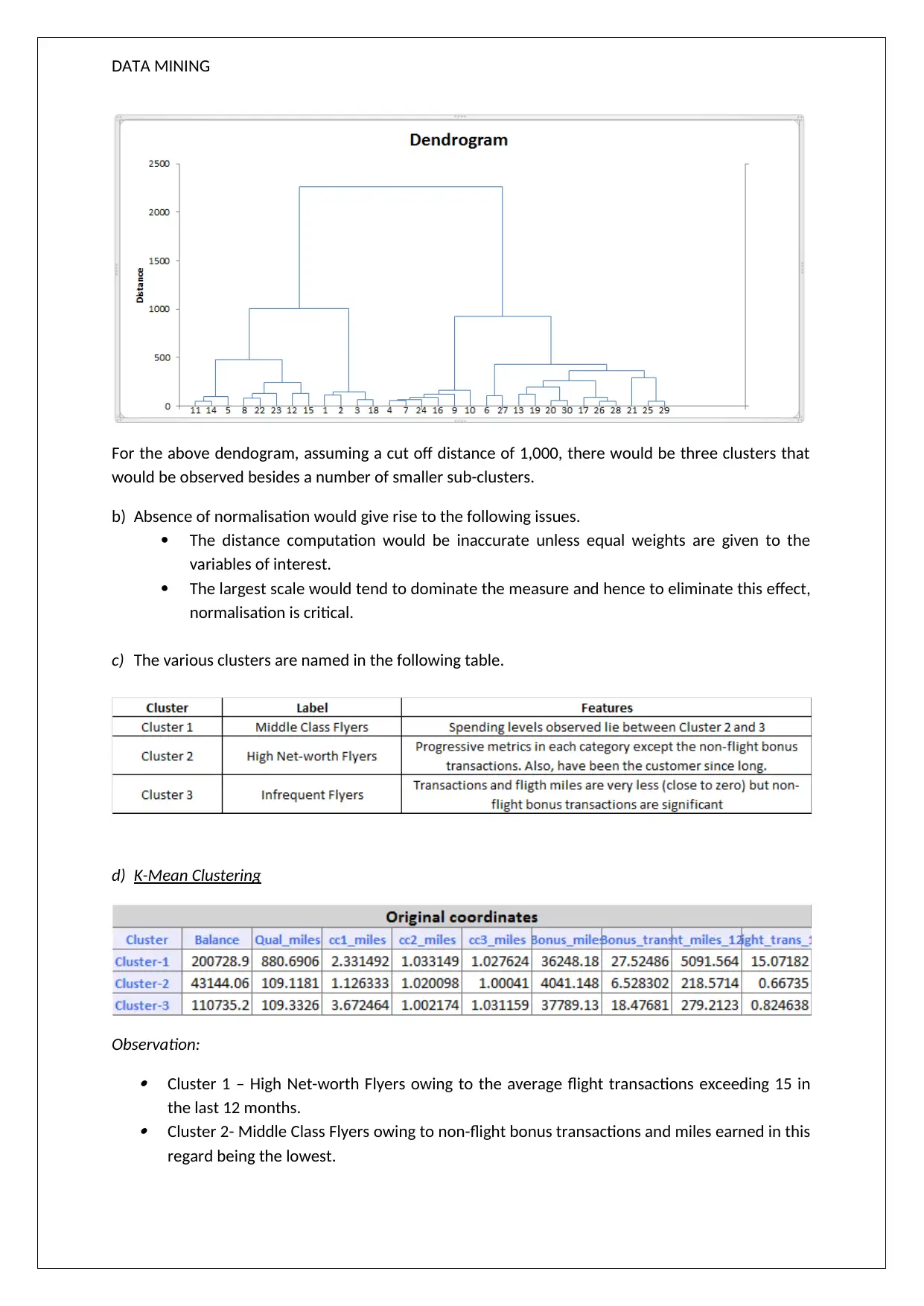
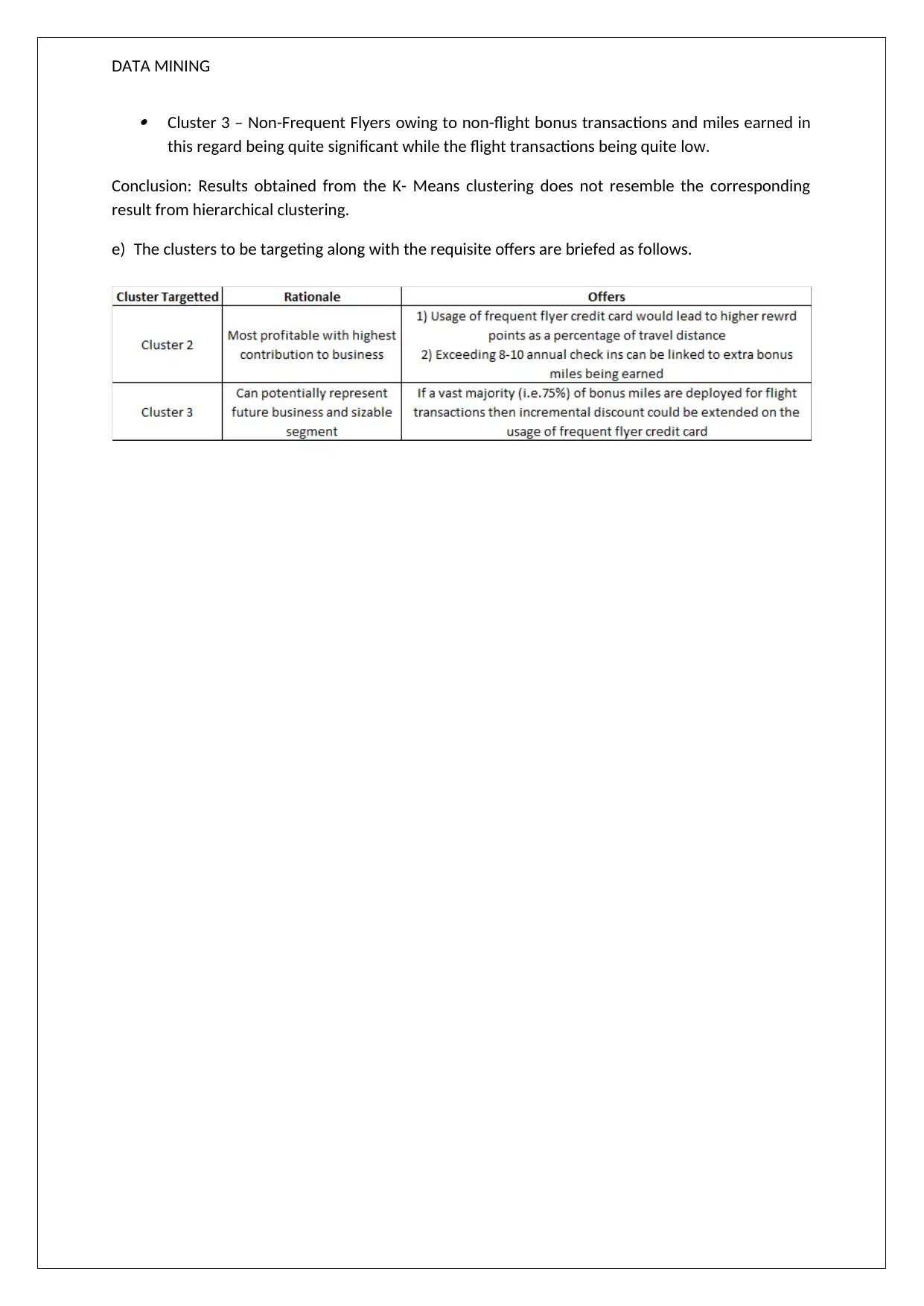
This data mining assignment explores association rules and clustering techniques. The assignment presents an analysis of association rules, highlighting confidence levels and rule redundancy. It also includes a dendrogram analysis, discussing cluster formation and the impact of normalization. Furthermore, the document covers K-Means clustering, comparing the results with hierarchical clustering and identifying clusters based on flight transaction data. The conclusion provides targeted offers based on cluster analysis. This resource, available on Desklib, offers detailed solutions and explanations for students studying data mining and related subjects, providing valuable insights into practical applications and theoretical concepts within the field of data science and big data.

1 out of 4
Related Documents


![Data Mining Assignment for [Course Name] - Analysis and Findings](/_next/image/?url=https%3A%2F%2Fdesklib.com%2Fmedia%2Fimages%2Fml%2F8b9bb9b0c77d435887f2ac7476b3a62f.jpg&w=256&q=75)



Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.