Automatic Detection of Cyberbullying Using Machine Learning Techniques
VerifiedAdded on 2023/02/06
|12
|2438
|59
Project
AI Summary
This project proposes an automated cyberbullying detection system using machine learning techniques and Python. The project aims to analyze social media data, specifically tweets, to identify instances of cyberbullying. It involves data collection, preprocessing using NLP techniques, feature extraction, and model training using algorithms such as Naive Bayes, Support Vector Machine (SVM), and Deep Neural Networks (DNN). The system utilizes the Flask framework for web application development, MySQL for the database, and HTML, CSS, and JavaScript for the front-end. The project addresses the limitations of manual monitoring and aims to provide a more efficient and timely response to cyberbullying incidents. The project also explores the expansion of cyberbullying detection beyond just identifying bullies and victims by identifying defenders, bystanders, and instigators. Furthermore, it aims to analyze the emotional state of victims and incorporate real-time data streaming for continuous monitoring.

Automatic detection of Cyberbullying
Name:
Student ID:
Course of Study:
Date Proposal Submitted:
Submission Date:
Supervisor:
Name:
Student ID:
Course of Study:
Date Proposal Submitted:
Submission Date:
Supervisor:
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Overview
Web 2.0 is comprised of a substantial impact on the relationship and communication within the
current time. Although many internet use teenagers are harmless, and also the benefits of the
communication in digital form are evident, the anonymity and freedom have experienced the
making online young people highly vulnerable by making using of cyberbullying that has been
one of the biggest threats. The cyber bullying manifested as digital technology has become the
tool of primary communication. Also on the positive aspects, the blogs on social media, sites of
social networking, and platforms of instant messaging create this possible for communicating
with anyone anywhere anytime. So, they are within the place where people might engage in
social interaction, offering the possibility of the establishment of newer relationships and
maintaining the existing links. On negative aspects, the social media enhances the children risk
which has been confronted with the situations threats comprised with sexually or grooming
transgressive behavior, depression signals and thoughts (suicidal), and also cyberbullying.
This report proposes the method of machine learning using Python for the detection of
cyberbullying by creating the usage of linear classifier exploitation of the numerous feature sets.
This has been an initial approach for the annotation of grained finely categories of text associated
with cyberbullying and also signals detection of the events of cyberbullying. This report has been
focused on the experimenting and analysis of extraction of features and detection of the cyber
bullying within social sites by making use of the NLP (Natural Language Processing) tools and
numerous algorithms of machine learning using Python.
Web 2.0 is comprised of a substantial impact on the relationship and communication within the
current time. Although many internet use teenagers are harmless, and also the benefits of the
communication in digital form are evident, the anonymity and freedom have experienced the
making online young people highly vulnerable by making using of cyberbullying that has been
one of the biggest threats. The cyber bullying manifested as digital technology has become the
tool of primary communication. Also on the positive aspects, the blogs on social media, sites of
social networking, and platforms of instant messaging create this possible for communicating
with anyone anywhere anytime. So, they are within the place where people might engage in
social interaction, offering the possibility of the establishment of newer relationships and
maintaining the existing links. On negative aspects, the social media enhances the children risk
which has been confronted with the situations threats comprised with sexually or grooming
transgressive behavior, depression signals and thoughts (suicidal), and also cyberbullying.
This report proposes the method of machine learning using Python for the detection of
cyberbullying by creating the usage of linear classifier exploitation of the numerous feature sets.
This has been an initial approach for the annotation of grained finely categories of text associated
with cyberbullying and also signals detection of the events of cyberbullying. This report has been
focused on the experimenting and analysis of extraction of features and detection of the cyber
bullying within social sites by making use of the NLP (Natural Language Processing) tools and
numerous algorithms of machine learning using Python.

Objectives
The main objective of this report is the detection of the model of cyberbullying would help
within enhancing the manual type of monitoring for cyberbullying through social networks. This
project will help in fetching the tweets from social media and then it will preprocess the images
and tweets and apply the model generated that helps in the detection of cyberbullying (Pawar, et
al., 2019).
The aims of the development of such a system and the management of events are as shown
below:
Collecting the sets of data of the bullying words and then preprocessing it and applying
the NLP (Natural language Processing) and then the algorithm of machine learning using
python generated numerous algorithms of machine learning model.
Fetches the tweets from the social network accounts and then preprocess them.
Applies the generated model to the tweets that have been fetched and carries the final
output that is cyberbullying or not.
Social networks offer us a huge platform for communication and also enhance the vulnerability
of the younger generation in threatening situations online. Cyberbullying on social networks has
been a global phenomenon because of its huge quantity of users (active). Per the trend that shows
that bullying online through social networks has been enhancing frequently each day. So, the
successful prevention has been dependent on the detection of messages that are potentially
harmful and the overloading of data on the web needs an intelligent system within the identity of
the potential type of risk in an automated manner.
The main objective of this report is the detection of the model of cyberbullying would help
within enhancing the manual type of monitoring for cyberbullying through social networks. This
project will help in fetching the tweets from social media and then it will preprocess the images
and tweets and apply the model generated that helps in the detection of cyberbullying (Pawar, et
al., 2019).
The aims of the development of such a system and the management of events are as shown
below:
Collecting the sets of data of the bullying words and then preprocessing it and applying
the NLP (Natural language Processing) and then the algorithm of machine learning using
python generated numerous algorithms of machine learning model.
Fetches the tweets from the social network accounts and then preprocess them.
Applies the generated model to the tweets that have been fetched and carries the final
output that is cyberbullying or not.
Social networks offer us a huge platform for communication and also enhance the vulnerability
of the younger generation in threatening situations online. Cyberbullying on social networks has
been a global phenomenon because of its huge quantity of users (active). Per the trend that shows
that bullying online through social networks has been enhancing frequently each day. So, the
successful prevention has been dependent on the detection of messages that are potentially
harmful and the overloading of data on the web needs an intelligent system within the identity of
the potential type of risk in an automated manner.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

How the Objectives will be achieved
This project has been developed by making use of the Python and technology of the web.
Initially, we would search and then find the sets of data and download them for training the
model generated. After carrying out the downloading it needs to be preprocessed of the data and
then this might be transferred to the Tf-Idf (Technique for quantifying the words in documents).
Then, by making use of the naïve Bayes theorem, Support vector machine (SVM), and also the
algorithm of DNN we will train the sets of data and generate the model in a separate manner.
After that, we need to develop the application on basis of the web by making use of the
framework i.e., FLASK. We would fetch the tweets in real-time from a social network like
Twitter and check the images or text that has been cyberbullying or not. These entire things will
be carried out by using Python as the backend, the database users will be MySQL and for the
frontend JavaScript, CSS, and HTML will be used (Salawu, et al., 2017).
This project has been developed by making use of the Python and technology of the web.
Initially, we would search and then find the sets of data and download them for training the
model generated. After carrying out the downloading it needs to be preprocessed of the data and
then this might be transferred to the Tf-Idf (Technique for quantifying the words in documents).
Then, by making use of the naïve Bayes theorem, Support vector machine (SVM), and also the
algorithm of DNN we will train the sets of data and generate the model in a separate manner.
After that, we need to develop the application on basis of the web by making use of the
framework i.e., FLASK. We would fetch the tweets in real-time from a social network like
Twitter and check the images or text that has been cyberbullying or not. These entire things will
be carried out by using Python as the backend, the database users will be MySQL and for the
frontend JavaScript, CSS, and HTML will be used (Salawu, et al., 2017).
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Legal, Social, Ethical issues
Limitation of the System:
The detection of sarcasm is not within the scope of our generated system.
This system could able to handle the messages only from one language at a specific time.
There is no truth that is publicly availed linked with the sets of data and their tagging.
Limitation of the System:
The detection of sarcasm is not within the scope of our generated system.
This system could able to handle the messages only from one language at a specific time.
There is no truth that is publicly availed linked with the sets of data and their tagging.

Resources
The resources required for geniting the system for detection of cyberbullying are shown below:
Programming Language:
Python: this programming language is used for the backend process of the project
because of its approachable syntax, and also server-side usage creates the python primary
language of programming for the development of the backend for detection of
cyberbullying.
JavaScript: This has been the programing language that carries the front-end development
of the project for the detection of cyberbullying on social networks. This language uses
HTML and CSS for structure and beautification purposes (Ali, et al., 2020).
HTML
CSS
Framework:
FLASK: This has been the Python framework that is light weighted and small web
framework of python which offers several useful tools and also the features which
created the python-based web apps simple to create. This offers the developers flexibility
and also a highly accessible framework for newer developers.
Algorithm:
Naïve Bayes: The family of the Naïve Bayes model of the classifiers is simple
probabilistic conditional classifiers that work by applying the Bayes Theorem with
independent naïve assumptions within the numerous features. Entire features have been
assumed with independent offered label Y:
P ( XI , … , Xn
Y ) =πi=1
n P(Xi /Y )
The simple representation of the document has been used here, usually the words bag.
The essential works for the text meaning, and thus imperative within their classification
have been considered and offered the weight as per the meaning, or within such case,
severity. For an instance, “faggof” might receive a higher weightage than the “bitch”,
because the former is discriminatory and abusive sexually. So, offered with the document
‘d’ and the “c” as a class.
P(c by d) equals to [(P(d/c) + P(c)) upon (P(d))]
The resources required for geniting the system for detection of cyberbullying are shown below:
Programming Language:
Python: this programming language is used for the backend process of the project
because of its approachable syntax, and also server-side usage creates the python primary
language of programming for the development of the backend for detection of
cyberbullying.
JavaScript: This has been the programing language that carries the front-end development
of the project for the detection of cyberbullying on social networks. This language uses
HTML and CSS for structure and beautification purposes (Ali, et al., 2020).
HTML
CSS
Framework:
FLASK: This has been the Python framework that is light weighted and small web
framework of python which offers several useful tools and also the features which
created the python-based web apps simple to create. This offers the developers flexibility
and also a highly accessible framework for newer developers.
Algorithm:
Naïve Bayes: The family of the Naïve Bayes model of the classifiers is simple
probabilistic conditional classifiers that work by applying the Bayes Theorem with
independent naïve assumptions within the numerous features. Entire features have been
assumed with independent offered label Y:
P ( XI , … , Xn
Y ) =πi=1
n P(Xi /Y )
The simple representation of the document has been used here, usually the words bag.
The essential works for the text meaning, and thus imperative within their classification
have been considered and offered the weight as per the meaning, or within such case,
severity. For an instance, “faggof” might receive a higher weightage than the “bitch”,
because the former is discriminatory and abusive sexually. So, offered with the document
‘d’ and the “c” as a class.
P(c by d) equals to [(P(d/c) + P(c)) upon (P(d))]
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

The class of max. posterior, or also most likely type of class, being within the case that is
either by bullying or not, might be:
Cmap equals to argmaxcEC * P(c/d)
= argmaxcEC * P(d/c) * P(c)
The data of corpus obtained for the experiment has been similar to that has been used for
the J48. Within such cases, the rate of true positive of 0.72222, carrying into the social
and textual features of the account has been obtained. Without carrying into the features
of social account, the rate has been 0.58 proving wrong once again, as per the tests
similar has performed with the J48, the features of social help the resulting enhancement
(Reynolds, et al., 2011).
SVM
The support vector machine has been an algorithm for supervised learning and has one of
the essential and universal algorithm classifications. This objective is for finding the
optimal hyper lance of separation that will maximize the training data margin. Firstly, the
training of the classifier takes place with the labeled data before getting used for the
classification of the data for testing the accuracy. Before usage of data for training the
classifiers, this has been imperative to be processed. Thus, it comprised of numerous
steps:
o Data labeling
o Vocabulary Generation
o Matrix of document term creation
When the labeled data has been converted within the matrix data on basis of the values
within the vocabulary, values have been plotted then and the hyperplane in an optimal
manner has selected within such a path which has maximizing the training data margin.
Once the training of the classifier is carried out the data input has passed to such classifier
for segregating them within negative and positive instances of the bullying. Such data
input for the purposes of testing has also been converted within the matrix of data and
such matrix of data has passed within the classifier. The SVMs use the learning of
sophisticated statistical theory for overcoming the dimensionality curse. Specification of
the vector feature and the functions of the kernel could be used for offering the similarity
either by bullying or not, might be:
Cmap equals to argmaxcEC * P(c/d)
= argmaxcEC * P(d/c) * P(c)
The data of corpus obtained for the experiment has been similar to that has been used for
the J48. Within such cases, the rate of true positive of 0.72222, carrying into the social
and textual features of the account has been obtained. Without carrying into the features
of social account, the rate has been 0.58 proving wrong once again, as per the tests
similar has performed with the J48, the features of social help the resulting enhancement
(Reynolds, et al., 2011).
SVM
The support vector machine has been an algorithm for supervised learning and has one of
the essential and universal algorithm classifications. This objective is for finding the
optimal hyper lance of separation that will maximize the training data margin. Firstly, the
training of the classifier takes place with the labeled data before getting used for the
classification of the data for testing the accuracy. Before usage of data for training the
classifiers, this has been imperative to be processed. Thus, it comprised of numerous
steps:
o Data labeling
o Vocabulary Generation
o Matrix of document term creation
When the labeled data has been converted within the matrix data on basis of the values
within the vocabulary, values have been plotted then and the hyperplane in an optimal
manner has selected within such a path which has maximizing the training data margin.
Once the training of the classifier is carried out the data input has passed to such classifier
for segregating them within negative and positive instances of the bullying. Such data
input for the purposes of testing has also been converted within the matrix of data and
such matrix of data has passed within the classifier. The SVMs use the learning of
sophisticated statistical theory for overcoming the dimensionality curse. Specification of
the vector feature and the functions of the kernel could be used for offering the similarity
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

within the points of data. There have been numerous kernels that could be used with the
SVM. They are:
o Radial-based function (RDF) Kernel
o Gaussian Kernel
o Linear Kernel
DNN (Deep Neural Networks)
Deep Neural Networks will compose the computations that are performed by numerous
layers. The denoting of the hidden layers of output by h(1)(x), the network computation
with the layers hidden (L) is:
f ( x)=f [a ( L+ 1)(h(L)(a( L)(...(h(2)(a (2)( h(1)(a(1)(x))))))))]
Each of the function reactivation a (1)( x ) has been typically the linear form of operation
with the W(1) matrix and the bias b(1) that could be combined within the parameter.
In the contrast to the graphical type of model like the networks of Bayesian where the
variables are hidden are some random type of variables, the units that are hidden here are
the intermediate computations of deterministic, that is why they aren’t represented as per
the circles. So, the variable output yk has been drawn as circles because they could be
formulated in a probabilistic manner (Tahmasbi, et al., 2018).
SVM. They are:
o Radial-based function (RDF) Kernel
o Gaussian Kernel
o Linear Kernel
DNN (Deep Neural Networks)
Deep Neural Networks will compose the computations that are performed by numerous
layers. The denoting of the hidden layers of output by h(1)(x), the network computation
with the layers hidden (L) is:
f ( x)=f [a ( L+ 1)(h(L)(a( L)(...(h(2)(a (2)( h(1)(a(1)(x))))))))]
Each of the function reactivation a (1)( x ) has been typically the linear form of operation
with the W(1) matrix and the bias b(1) that could be combined within the parameter.
In the contrast to the graphical type of model like the networks of Bayesian where the
variables are hidden are some random type of variables, the units that are hidden here are
the intermediate computations of deterministic, that is why they aren’t represented as per
the circles. So, the variable output yk has been drawn as circles because they could be
formulated in a probabilistic manner (Tahmasbi, et al., 2018).

Figure 1: DNN Model
Database: MySQL
Critical Success Factor
The success factor of this project is very high and also the primary goal in generating such a
system is to detect the posts related to cyberbullying on social media. Offering the overloaded
information onto the web, and monitoring manually for cyberbullying has highly unfeasible. The
detection of the cyberbullying signals automatically might enhance the moderation and enable to
respond in a frequent manner at the time of requirement. So, such posts might indicate that
cyberbullying has been carried out. The goal of this project that it will present the system in
detecting the cyberbullying signals in an automatic manner on the social networks comprised of
numerous cyberbullying, bullies-covered posts, bystanders, and victims.
Features
The project that has been carried out to develop an application which comprised of images
within the online data and tweets and we would need to fetch such images from the social
network and after the classification of OCR would be carried out by out Naïve Bayes and SVM
model.
Detection of the cyberbullying non-Textual
Database: MySQL
Critical Success Factor
The success factor of this project is very high and also the primary goal in generating such a
system is to detect the posts related to cyberbullying on social media. Offering the overloaded
information onto the web, and monitoring manually for cyberbullying has highly unfeasible. The
detection of the cyberbullying signals automatically might enhance the moderation and enable to
respond in a frequent manner at the time of requirement. So, such posts might indicate that
cyberbullying has been carried out. The goal of this project that it will present the system in
detecting the cyberbullying signals in an automatic manner on the social networks comprised of
numerous cyberbullying, bullies-covered posts, bystanders, and victims.
Features
The project that has been carried out to develop an application which comprised of images
within the online data and tweets and we would need to fetch such images from the social
network and after the classification of OCR would be carried out by out Naïve Bayes and SVM
model.
Detection of the cyberbullying non-Textual
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

We will develop the application that comprises the image within the online data form and tweets
and would able to fetch such type of image from the Twitter and after the classification of OCR
would be done by SVM and Naïve Bayes Model.
Expansion of the cyberbullying detection Role beyond the bullies and victims
Roles in form of defenders, bystanders, and instigators would be identified by the system on
basis of the algorithms generated by labeling and collecting the data.
The emotional state of victim determination after the incident of cyberbullying
the victim might be able to modify the profile details following such type of negative sentiments,
or interactions, or might leave the network in the abrupt form. Such form of interaction could be
highly flagged for review by the humans who might be able to follow up with the proper action.
Learning representation of word for the detection of cyberbullying
The experiments could be performed for generating the embedded words from numerous sets of
data ranging from corpora general to highly specialized types of sets of data for comparison of its
detection of cyberbullying and effectiveness (Van Hee, et al., 2018).
Cyberbullying detection within real-time and data streaming
We need to determine the dataset of Twitter on cyberbullying auth type-token would be
generated on the account of a social network, we will fetch out tweets.
Annotation Judgement evaluation
We would annotate each of the sentences on Twitter and output would be generated.
and would able to fetch such type of image from the Twitter and after the classification of OCR
would be done by SVM and Naïve Bayes Model.
Expansion of the cyberbullying detection Role beyond the bullies and victims
Roles in form of defenders, bystanders, and instigators would be identified by the system on
basis of the algorithms generated by labeling and collecting the data.
The emotional state of victim determination after the incident of cyberbullying
the victim might be able to modify the profile details following such type of negative sentiments,
or interactions, or might leave the network in the abrupt form. Such form of interaction could be
highly flagged for review by the humans who might be able to follow up with the proper action.
Learning representation of word for the detection of cyberbullying
The experiments could be performed for generating the embedded words from numerous sets of
data ranging from corpora general to highly specialized types of sets of data for comparison of its
detection of cyberbullying and effectiveness (Van Hee, et al., 2018).
Cyberbullying detection within real-time and data streaming
We need to determine the dataset of Twitter on cyberbullying auth type-token would be
generated on the account of a social network, we will fetch out tweets.
Annotation Judgement evaluation
We would annotate each of the sentences on Twitter and output would be generated.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
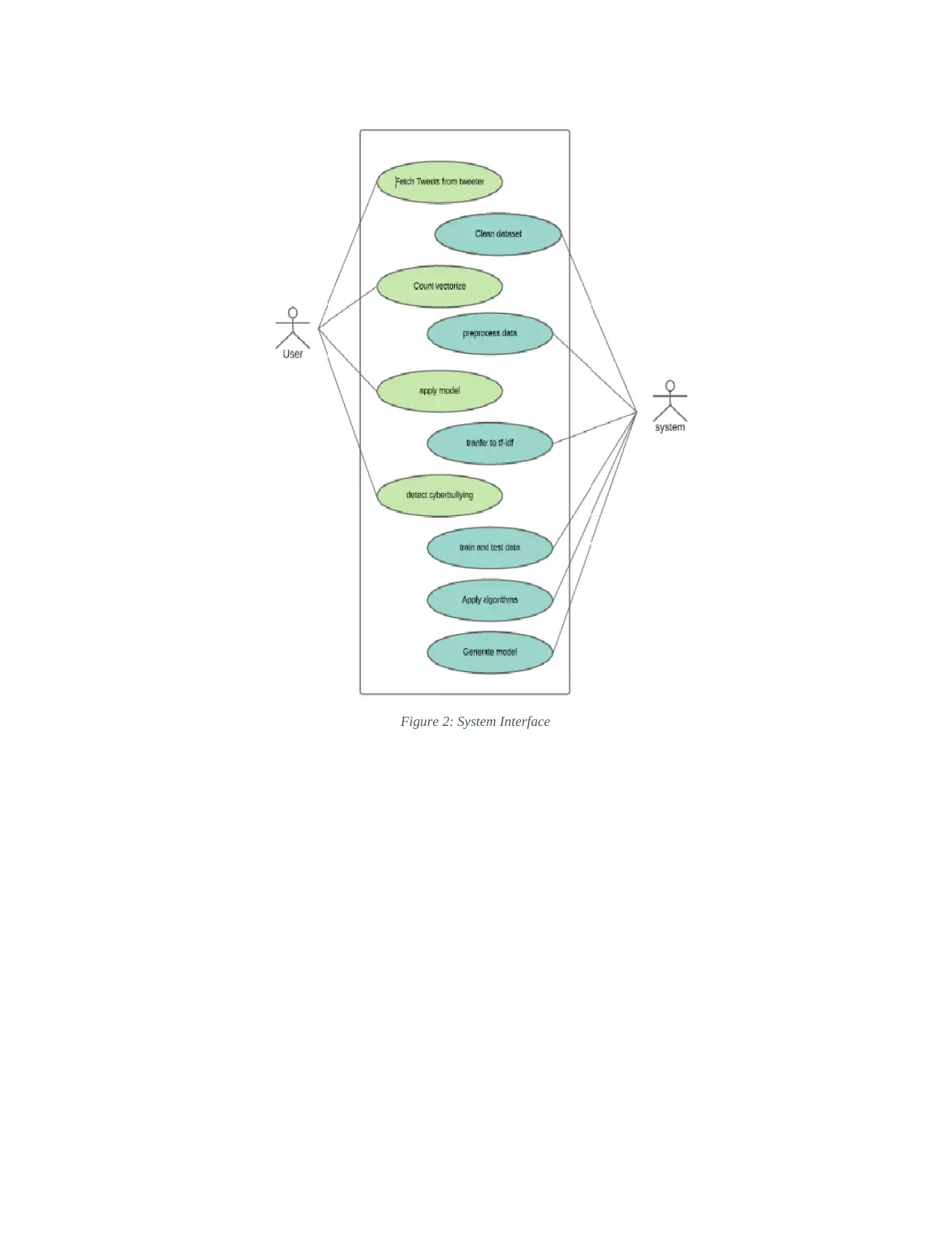
Figure 2: System Interface

References
Pawar, R. and Raje, R.R., 2019, May. Multilingual cyberbullying detection system. In 2019
IEEE international conference on electro information technology (EIT) (pp. 040-044). IEEE.
Salawu, S., He, Y. and Lumsden, J., 2017. Approaches to automated detection of cyberbullying:
A survey. IEEE Transactions on Affective Computing, 11(1), pp.3-24.
Ali, A. and Syed, A.M., 2020. Cyberbullying detection using machine learning. Pakistan
Journal of Engineering and Technology, 3(2), pp.45-50.
Reynolds, K., Kontostathis, A. and Edwards, L., 2011, December. Using machine learning to
detect cyberbullying. In 2011 10th International Conference on Machine learning and
applications and workshops (Vol. 2, pp. 241-244). IEEE.
Tahmasbi, N. and Rastegari, E., 2018. A socio-contextual approach in automated detection of
cyberbullying.
Van Hee, C., Jacobs, G., Emmery, C., Desmet, B., Lefever, E., Verhoeven, B., De Pauw, G.,
Daelemans, W. and Hoste, V., 2018. Automatic detection of cyberbullying in social media text.
PloS one, 13(10), p.e0203794.
Pawar, R. and Raje, R.R., 2019, May. Multilingual cyberbullying detection system. In 2019
IEEE international conference on electro information technology (EIT) (pp. 040-044). IEEE.
Salawu, S., He, Y. and Lumsden, J., 2017. Approaches to automated detection of cyberbullying:
A survey. IEEE Transactions on Affective Computing, 11(1), pp.3-24.
Ali, A. and Syed, A.M., 2020. Cyberbullying detection using machine learning. Pakistan
Journal of Engineering and Technology, 3(2), pp.45-50.
Reynolds, K., Kontostathis, A. and Edwards, L., 2011, December. Using machine learning to
detect cyberbullying. In 2011 10th International Conference on Machine learning and
applications and workshops (Vol. 2, pp. 241-244). IEEE.
Tahmasbi, N. and Rastegari, E., 2018. A socio-contextual approach in automated detection of
cyberbullying.
Van Hee, C., Jacobs, G., Emmery, C., Desmet, B., Lefever, E., Verhoeven, B., De Pauw, G.,
Daelemans, W. and Hoste, V., 2018. Automatic detection of cyberbullying in social media text.
PloS one, 13(10), p.e0203794.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 12
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.