Bayesian Statistics Homework: Posterior Distributions and R Analysis
VerifiedAdded on 2023/05/31
|7
|1033
|353
Homework Assignment
AI Summary
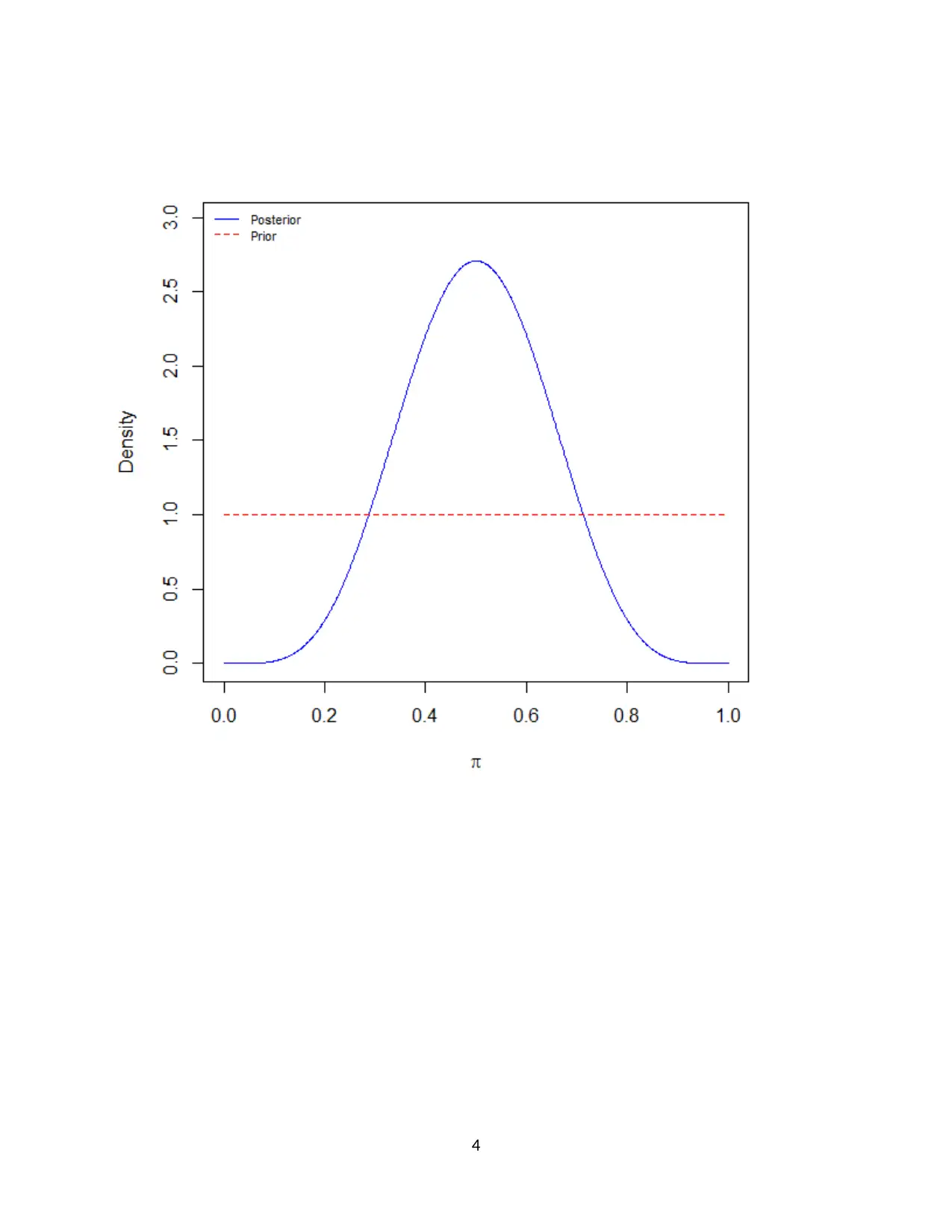
This document provides a comprehensive solution to a Bayesian statistics homework assignment. The assignment focuses on calculating and analyzing posterior distributions under different prior assumptions. Part 1 addresses a binomial distribution with a uniform prior, calculating the posterior distribution and using R to determine the mean, median, standard deviation, and confidence intervals, with a plot demonstrating the results. Part 2 explores a normal distribution with a semi-conjugate prior, calculating the full conditional posterior distributions for both the mean and the variance. The solution includes detailed mathematical derivations and the R code used for the analysis, offering a complete understanding of the concepts and methods involved in Bayesian statistical inference. The assignment references key statistical concepts and provides a practical application of Bayesian methods.






1 out of 7
Related Documents




Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.