BI2BM45 Key Skills in Biomedicine 2 Statistics Assignment
VerifiedAdded on 2022/09/14
|8
|924
|17
Homework Assignment
AI Summary
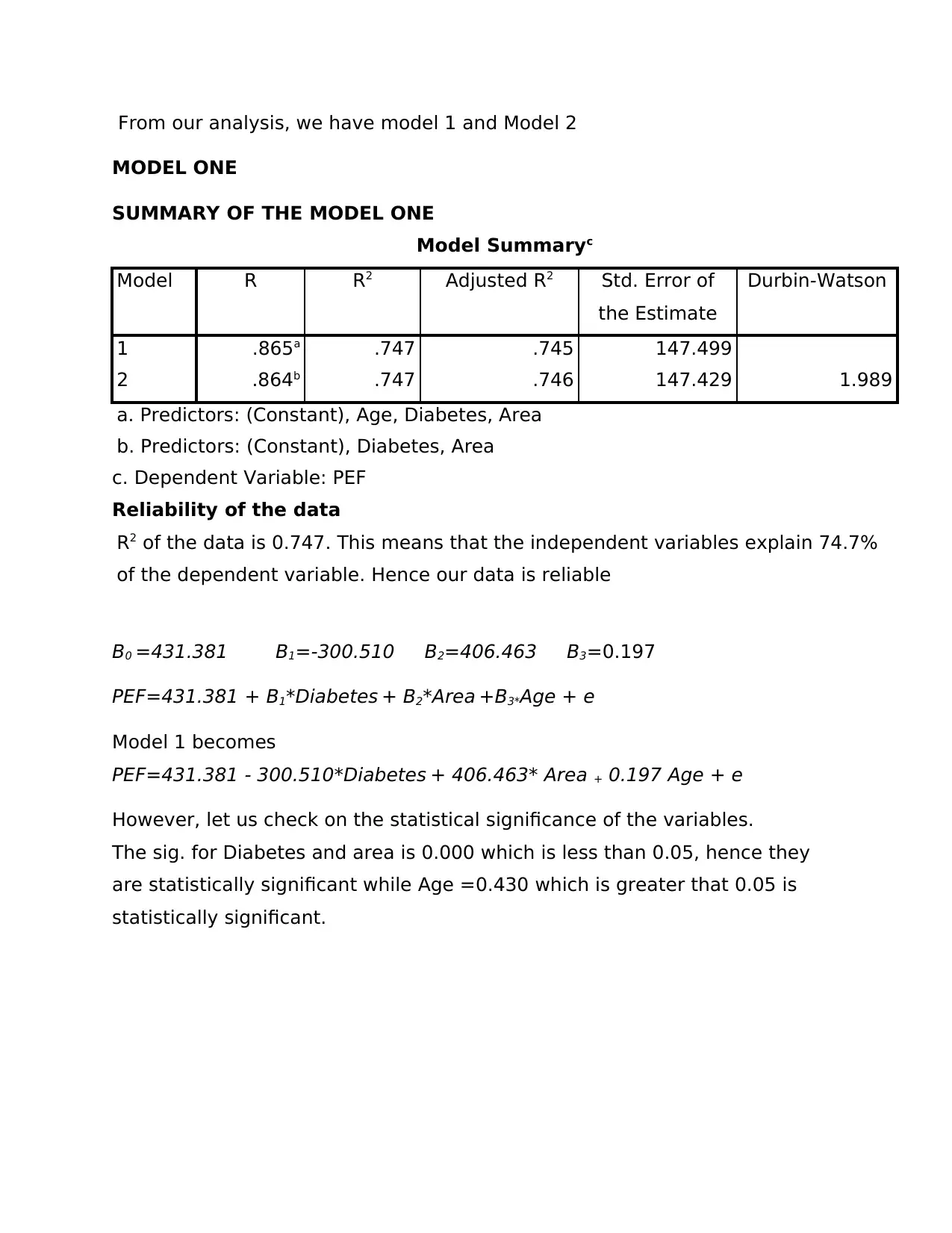
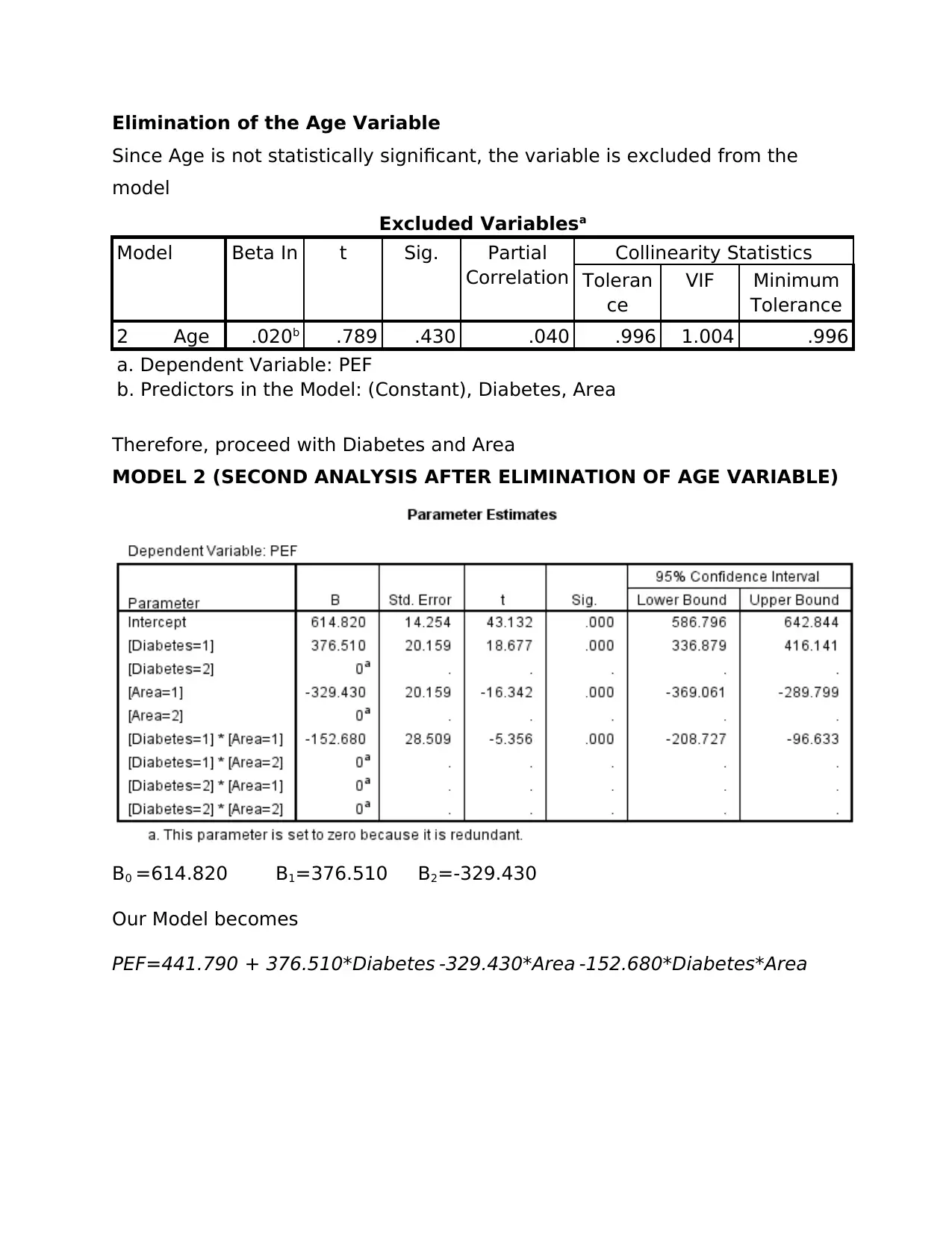
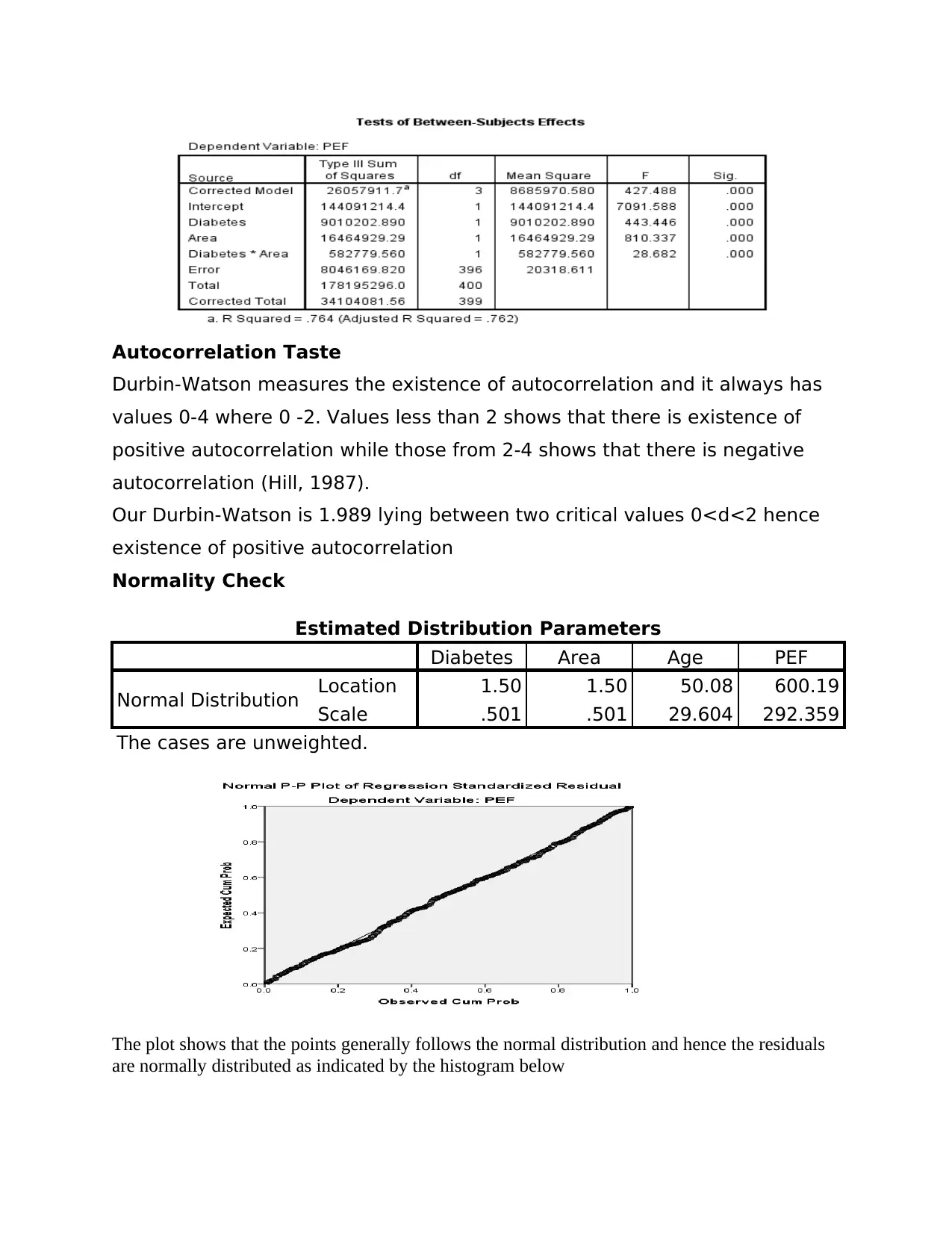
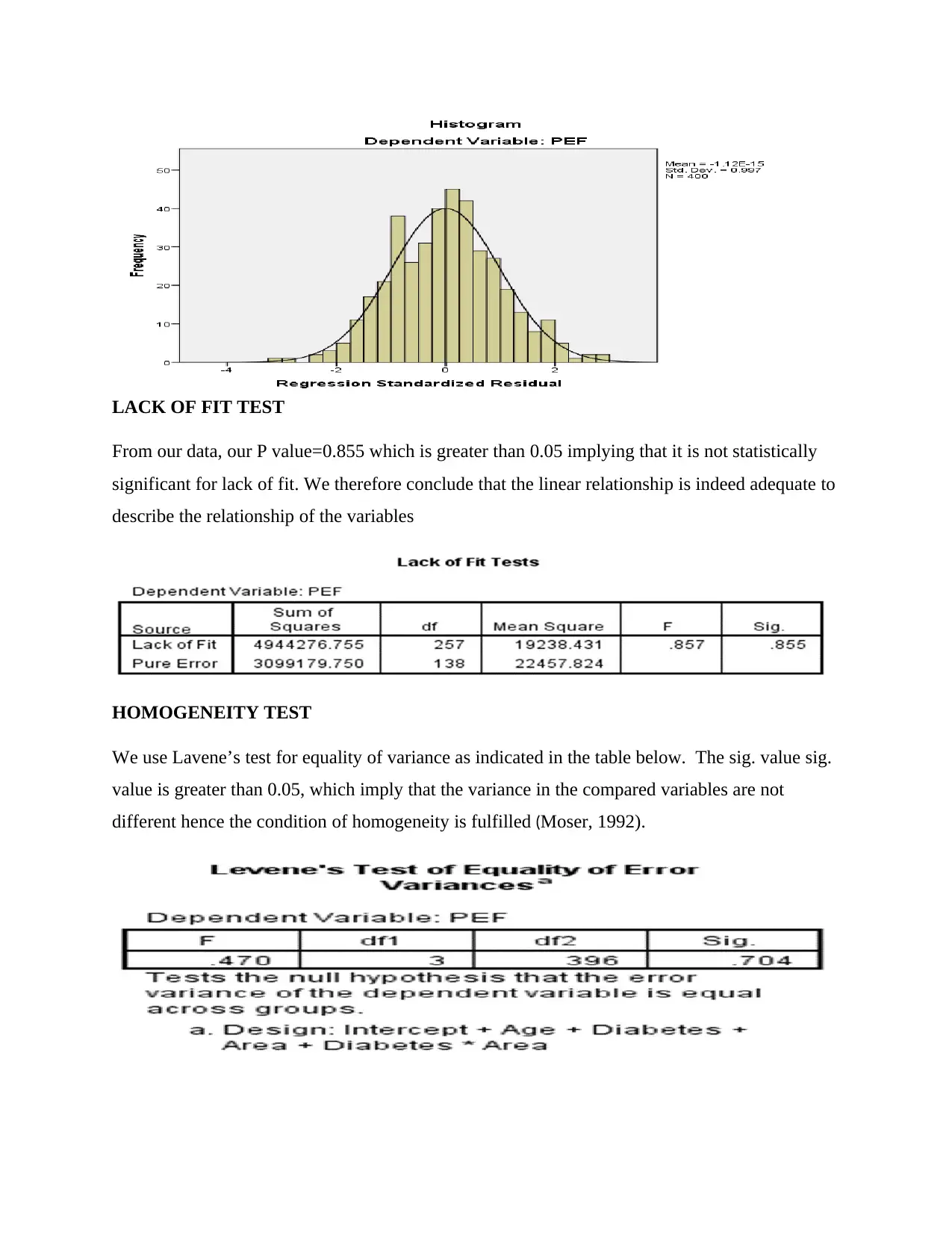
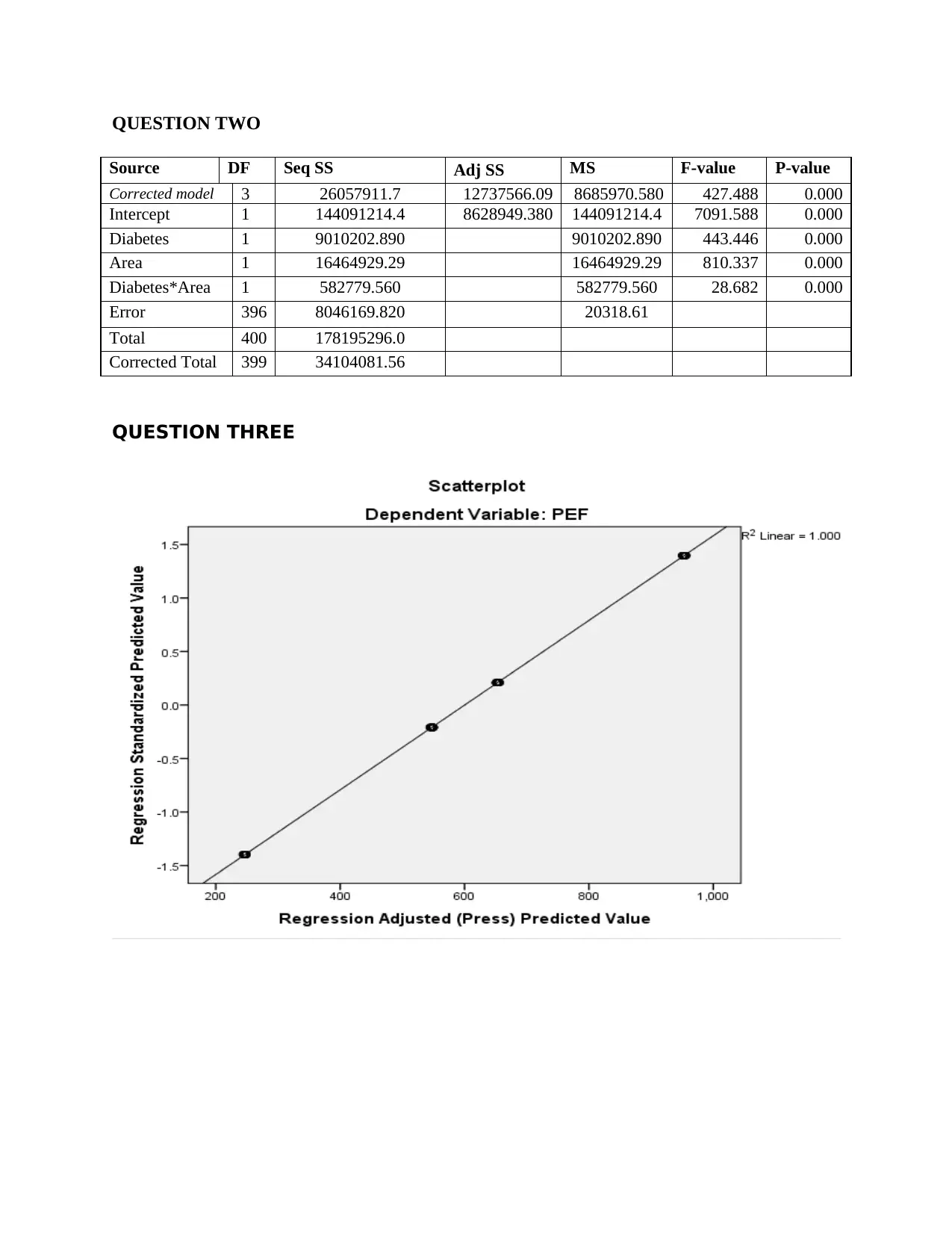
This document presents a detailed solution to a statistics assignment for the BI2BM45 Key Skills in Biomedicine 2 course. The assignment focuses on the application of the general linear model and regression analysis to a dataset concerning Peak Expiratory Flow (PEF), diabetes, area, and age. The analysis includes model building, assessing the statistical significance of variables, and eliminating insignificant variables to refine the model. The solution provides a summary of Model 1 and Model 2, including R-squared values, coefficient interpretations, and checks for multicollinearity, autocorrelation, normality, lack of fit, and homogeneity. The final model is presented, along with the interpretation of coefficients. The document includes a comprehensive analysis of the data, including the statistical significance of variables, the model's reliability, and tests for various assumptions, such as normality and homogeneity of variance. The document concludes with the references used in the analysis.



1 out of 8
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.