Big Data Opportunities, Architectures, and Technologies in Detail
VerifiedAdded on 2022/09/07
|16
|3484
|18
Essay
AI Summary
This essay provides a detailed exploration of big data, encompassing its characteristics, opportunities, architectures, and underlying technologies. It begins by defining big data and categorizing it into structured, semi-structured, and unstructured data, further elaborating on the key characteristics of big data: volume, velocity, variety, veracity, and value. The essay then transitions into the opportunities presented by big data, emphasizing its role in enhancing information management, improving operational efficiency, increasing supply chain visibility, enabling responsiveness to market changes, and refining product and market strategies. Example architectures like Hadoop, InfoSleuth, and TSIMMIS are discussed in detail, highlighting their components and functionalities in data storage, processing, and retrieval. The essay concludes with a call to action, encouraging readers to delve deeper into the subject and explore the vast resources available on Desklib.

Running head: BIG DATA
Big data opportunities, architectures and technologies
Name of the Student
Name of the University
Author’s Note
Big data opportunities, architectures and technologies
Name of the Student
Name of the University
Author’s Note
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

1
BIG DATA
Table of Contents
Big data characteristics..............................................................................................................2
Opportunities of big data............................................................................................................3
Examples of Big data architecture.............................................................................................5
Hadoop...................................................................................................................................5
InfoSleuth...............................................................................................................................6
TSIMMIS...............................................................................................................................8
Basic architecture of Big data..................................................................................................10
References................................................................................................................................12
BIG DATA
Table of Contents
Big data characteristics..............................................................................................................2
Opportunities of big data............................................................................................................3
Examples of Big data architecture.............................................................................................5
Hadoop...................................................................................................................................5
InfoSleuth...............................................................................................................................6
TSIMMIS...............................................................................................................................8
Basic architecture of Big data..................................................................................................10
References................................................................................................................................12

2
BIG DATA
Big data characteristics
The term of “Big data” is referred as a large volume of data in which the data storing
processing does not follow any traditional data storing processes or any processing units
(Chen, Mao and Liu 2014). This big data is produced at a huge quantity and normally utilized
in multinational companies for processing or analysing the exposure of the insights and also
improvement of the business of the organizations. By analysing the Big data, there are mainly
three diverse categorised big data available for the utilization of organizations and the
categories mention as structured, semi-structured and also unstructured data.
The structured data produces a devoted data model in which the data can stored in
consistent order so that the user can easily find the data and the example of this data is
database management system (Marz and Warren 2015). On other hand, the semi-structured
data is the alternative form of the structured data that means some part of this data can be
taken from structured data but most of the parts does not follow the proper structure of the
data models and the example is Comma separated values. Apart from these, as comparing
with the term, the unstructured data does not follow the official structure of the data models
and within this, the data are not stored in consistent order varying on the time. The example
of this kind of data is audio files or images etc.
After analysing the classification of big data, now it comes to the point of
characteristics of Big data. The characteristics depends on the volume, velocity as well as
value or variety of data (Gandomi and Haider 2015). The characteristics of Big data are as
follows:
Volume – The volume measures as the amount of data that is generated from the
social media or cell phones or images, credit cards or video etc. By using the Big data,
most of the companies utilize the distribution system by which the data can be stored
BIG DATA
Big data characteristics
The term of “Big data” is referred as a large volume of data in which the data storing
processing does not follow any traditional data storing processes or any processing units
(Chen, Mao and Liu 2014). This big data is produced at a huge quantity and normally utilized
in multinational companies for processing or analysing the exposure of the insights and also
improvement of the business of the organizations. By analysing the Big data, there are mainly
three diverse categorised big data available for the utilization of organizations and the
categories mention as structured, semi-structured and also unstructured data.
The structured data produces a devoted data model in which the data can stored in
consistent order so that the user can easily find the data and the example of this data is
database management system (Marz and Warren 2015). On other hand, the semi-structured
data is the alternative form of the structured data that means some part of this data can be
taken from structured data but most of the parts does not follow the proper structure of the
data models and the example is Comma separated values. Apart from these, as comparing
with the term, the unstructured data does not follow the official structure of the data models
and within this, the data are not stored in consistent order varying on the time. The example
of this kind of data is audio files or images etc.
After analysing the classification of big data, now it comes to the point of
characteristics of Big data. The characteristics depends on the volume, velocity as well as
value or variety of data (Gandomi and Haider 2015). The characteristics of Big data are as
follows:
Volume – The volume measures as the amount of data that is generated from the
social media or cell phones or images, credit cards or video etc. By using the Big data,
most of the companies utilize the distribution system by which the data can be stored
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

3
BIG DATA
in various locations and also bring the data into the data model framework. With the
help of this system, the multinational companies generate huge quantity of data in a
single day and for storing that data, they utilize the Big data enabled technology.
Velocity – The velocity is mentioned as another important characteristic of Big data
because during the processing time, if the storing process of data takes lots of time
therefore it may reflect a negative impact on the organizations (Chen and Zhang 014).
For that, there arrives a delay issue in the operational actions of the organizations.
Thus, the velocity acts as a primary role for storing the data faster in the data model
framework.
Variety – In the Big data technologies, there happens a variety of data storing in the
framework. Because in case of traditional data storing technique, only he traditional
data are stored within the data model including phone numbers or addresses etc. But
within the Big data, there can be stored a variety of data including images or videos as
well as audios or others.
Veracity – Veracity is another characteristics of Big data which provides the
authenticity of the offerings of the data (Raghupathi and Raghupathi 2014). Though,
most of the parts of the Big data considers as unstructured as well as irrelevant,
therefore Big data requires to search the alternative way by which they can be able to
filter or translate the data which is essential for the business developments.
Value – Value is also a significant characteristics for the Big data which focuses on
the reliability of the data. The big data based technologies are not only utilize for
storing the amount of the information but also it has to provide the equivalent value or
reliability of the data for finding the insights.
BIG DATA
in various locations and also bring the data into the data model framework. With the
help of this system, the multinational companies generate huge quantity of data in a
single day and for storing that data, they utilize the Big data enabled technology.
Velocity – The velocity is mentioned as another important characteristic of Big data
because during the processing time, if the storing process of data takes lots of time
therefore it may reflect a negative impact on the organizations (Chen and Zhang 014).
For that, there arrives a delay issue in the operational actions of the organizations.
Thus, the velocity acts as a primary role for storing the data faster in the data model
framework.
Variety – In the Big data technologies, there happens a variety of data storing in the
framework. Because in case of traditional data storing technique, only he traditional
data are stored within the data model including phone numbers or addresses etc. But
within the Big data, there can be stored a variety of data including images or videos as
well as audios or others.
Veracity – Veracity is another characteristics of Big data which provides the
authenticity of the offerings of the data (Raghupathi and Raghupathi 2014). Though,
most of the parts of the Big data considers as unstructured as well as irrelevant,
therefore Big data requires to search the alternative way by which they can be able to
filter or translate the data which is essential for the business developments.
Value – Value is also a significant characteristics for the Big data which focuses on
the reliability of the data. The big data based technologies are not only utilize for
storing the amount of the information but also it has to provide the equivalent value or
reliability of the data for finding the insights.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

4
BIG DATA
Opportunities of big data
The information acts as the driver of making business strategies for most of the
companies (George, Haas and Pentland 2014). It is necessary for storing the information in a
data model framework securely and to store the data safely, it requires to utilize the Big data
frameworks. This Big data has son many opportunities for multinational companies and it
provides a huge amount of effort in supply chain management (Kitchin 2014). The
opportunities are as follows:
[1] Enhancement of information management – This Big data helps to enable the
discoveries as well as accessibilities or availabilities of data within the organizations
and also supply chain (Lazer et al. 2014). This technology helps to discover the new
sets of the information which are not being utilize for driving the values.
[2] Increment of operational efficiency or maintenance – This big data helps to allow of
taking accurate decisions as well as continuous improvement on the productivity by
using the process of automation or optimizing services.
[3] Increment of supply chain based visibility and transparency – This technology a-helps
to grow the visibility or transparency of the supply chain by using the real time
controlling or multi-tier processing of the data locations.
[4] Great responsive – With the help of this technology, most of the bug companies can
easily provide the reaction on the changing of the market conditions and in this way,
they can quickly respond in the customers’ needs or market condition changing (Jin et
al. 2015).
[5] Enhancement of product as well as market strategy – This Bug data technology helps
to enhance the market customers segmentation by allowing the better scalability.
Thus, the companies can make the improvement in the customers’ service levels for
enhancing the customers’ acquisition and also sales strategies.
BIG DATA
Opportunities of big data
The information acts as the driver of making business strategies for most of the
companies (George, Haas and Pentland 2014). It is necessary for storing the information in a
data model framework securely and to store the data safely, it requires to utilize the Big data
frameworks. This Big data has son many opportunities for multinational companies and it
provides a huge amount of effort in supply chain management (Kitchin 2014). The
opportunities are as follows:
[1] Enhancement of information management – This Big data helps to enable the
discoveries as well as accessibilities or availabilities of data within the organizations
and also supply chain (Lazer et al. 2014). This technology helps to discover the new
sets of the information which are not being utilize for driving the values.
[2] Increment of operational efficiency or maintenance – This big data helps to allow of
taking accurate decisions as well as continuous improvement on the productivity by
using the process of automation or optimizing services.
[3] Increment of supply chain based visibility and transparency – This technology a-helps
to grow the visibility or transparency of the supply chain by using the real time
controlling or multi-tier processing of the data locations.
[4] Great responsive – With the help of this technology, most of the bug companies can
easily provide the reaction on the changing of the market conditions and in this way,
they can quickly respond in the customers’ needs or market condition changing (Jin et
al. 2015).
[5] Enhancement of product as well as market strategy – This Bug data technology helps
to enhance the market customers segmentation by allowing the better scalability.
Thus, the companies can make the improvement in the customers’ service levels for
enhancing the customers’ acquisition and also sales strategies.

5
BIG DATA
[6] Innovative product designs benefits – This technology also aids to make various
innovation in product designing. This process leads to increase the point of the sales
iof the company and also suppliers suggestions.
[7] Improvement of risk management – This Big data helps to enhance the risk evaluation
by involving in the continuity management at the organizations or supply chain for
decreasing the disruptions.
Examples of Big data architecture
Hadoop
The Hadoop distributed file system is considered as the block designed file system in
which each of the files are segmented into a number of blocks. These blocks can be stored
within the cluster of the one or more than one machine (Kambatla et al. 2014). According to
architecture of Hadoop, each of the cluster consists of one NameNode and several
DataNodes.
NameNode is referred as master node in this architecture of Hadoop which helps in
maintaining or managing the blocks presenting in the DataNodes. Here, the DataNode acts as
the slave node (Varian 2014). It requires to available for NameNode all the time within the
File system so that the clients can access the files (Hu et al. 2014). This node is accountable
for recording the metadata of the files storing within the cluster depending on the files as well
as permissions or hierarchy etc.
BIG DATA
[6] Innovative product designs benefits – This technology also aids to make various
innovation in product designing. This process leads to increase the point of the sales
iof the company and also suppliers suggestions.
[7] Improvement of risk management – This Big data helps to enhance the risk evaluation
by involving in the continuity management at the organizations or supply chain for
decreasing the disruptions.
Examples of Big data architecture
Hadoop
The Hadoop distributed file system is considered as the block designed file system in
which each of the files are segmented into a number of blocks. These blocks can be stored
within the cluster of the one or more than one machine (Kambatla et al. 2014). According to
architecture of Hadoop, each of the cluster consists of one NameNode and several
DataNodes.
NameNode is referred as master node in this architecture of Hadoop which helps in
maintaining or managing the blocks presenting in the DataNodes. Here, the DataNode acts as
the slave node (Varian 2014). It requires to available for NameNode all the time within the
File system so that the clients can access the files (Hu et al. 2014). This node is accountable
for recording the metadata of the files storing within the cluster depending on the files as well
as permissions or hierarchy etc.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
6
BIG DATA
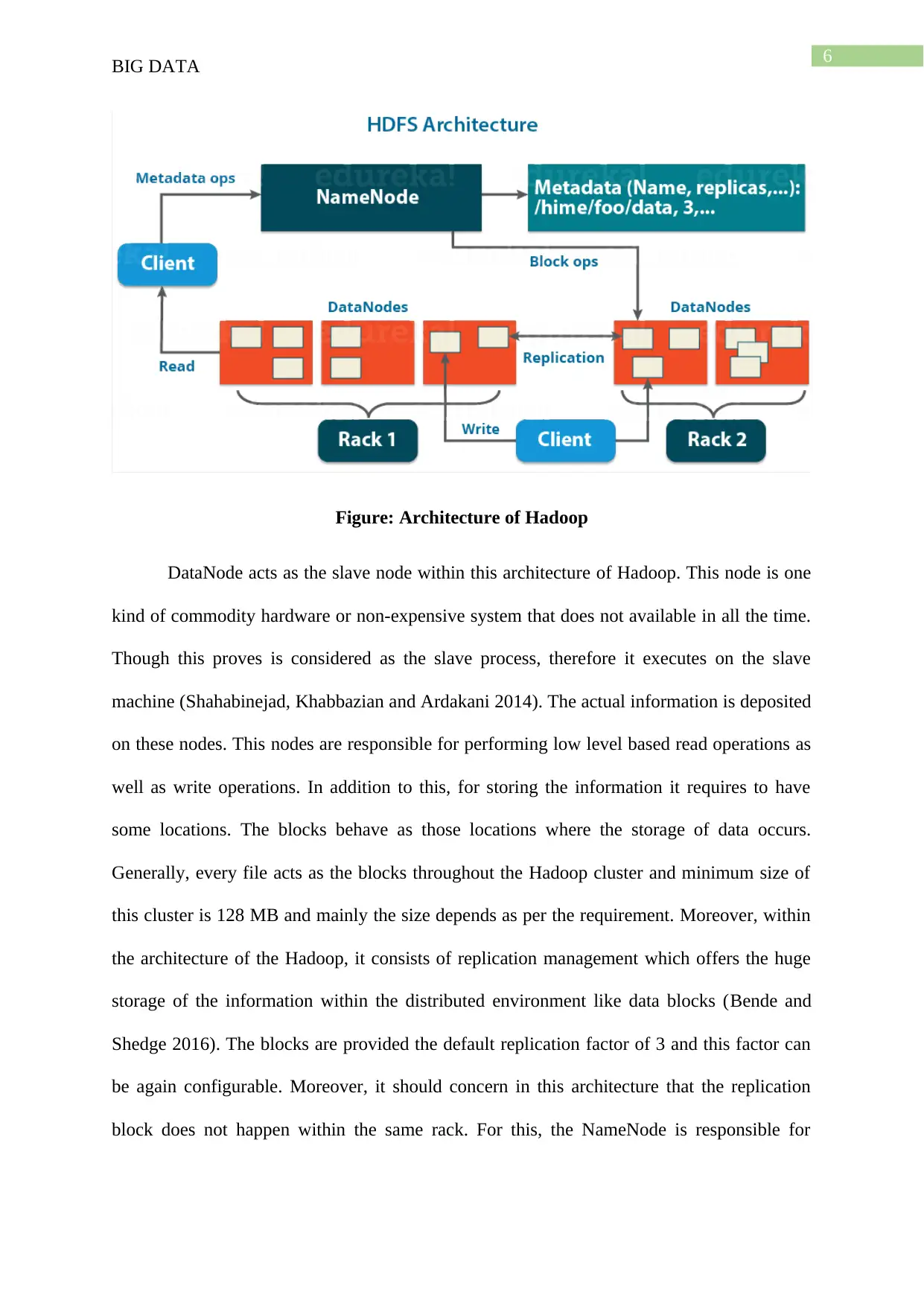
Figure: Architecture of Hadoop
DataNode acts as the slave node within this architecture of Hadoop. This node is one
kind of commodity hardware or non-expensive system that does not available in all the time.
Though this proves is considered as the slave process, therefore it executes on the slave
machine (Shahabinejad, Khabbazian and Ardakani 2014). The actual information is deposited
on these nodes. This nodes are responsible for performing low level based read operations as
well as write operations. In addition to this, for storing the information it requires to have
some locations. The blocks behave as those locations where the storage of data occurs.
Generally, every file acts as the blocks throughout the Hadoop cluster and minimum size of
this cluster is 128 MB and mainly the size depends as per the requirement. Moreover, within
the architecture of the Hadoop, it consists of replication management which offers the huge
storage of the information within the distributed environment like data blocks (Bende and
Shedge 2016). The blocks are provided the default replication factor of 3 and this factor can
be again configurable. Moreover, it should concern in this architecture that the replication
block does not happen within the same rack. For this, the NameNode is responsible for
BIG DATA
Figure: Architecture of Hadoop
DataNode acts as the slave node within this architecture of Hadoop. This node is one
kind of commodity hardware or non-expensive system that does not available in all the time.
Though this proves is considered as the slave process, therefore it executes on the slave
machine (Shahabinejad, Khabbazian and Ardakani 2014). The actual information is deposited
on these nodes. This nodes are responsible for performing low level based read operations as
well as write operations. In addition to this, for storing the information it requires to have
some locations. The blocks behave as those locations where the storage of data occurs.
Generally, every file acts as the blocks throughout the Hadoop cluster and minimum size of
this cluster is 128 MB and mainly the size depends as per the requirement. Moreover, within
the architecture of the Hadoop, it consists of replication management which offers the huge
storage of the information within the distributed environment like data blocks (Bende and
Shedge 2016). The blocks are provided the default replication factor of 3 and this factor can
be again configurable. Moreover, it should concern in this architecture that the replication
block does not happen within the same rack. For this, the NameNode is responsible for
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

7
BIG DATA
checking whether the replication of blocks occurs in same racks or not (Hua et al. 2014). In
this case, the rack awareness algorithm helps for providing the fault tolerance.
InfoSleuth
The InfoSleuth is the Micro-electronics and Computer technology based system that
involves in the performing of the collection of information and also analyse them across the
networks of the independent information sources (Yu et al. 2017). This architecture has some
distinguishable features including:
Domain based particular metadata enabled expressions are produced from the rich
domain based ontologies which helps to capture the information within the huge range
of domains.
Mapping which relates with the metadata terms from the domain ontologies to
fundamental information are explicitly deposited. These mappings are merged
together or retrieving the information relating with metadata expressions by the
particular query contexts (Ouamer-Ali et al. 2014). Various styles of mapping are
utilized for mapping various domain based ontologies. In this way, it provide the
proper supports to the views of the related information across the world.
Agent technology is utilized for implementing the functionality in order to support the
data brokering, the various pieces of the information can be found within various
agents along with having narrow as well as focused abilities.
BIG DATA
checking whether the replication of blocks occurs in same racks or not (Hua et al. 2014). In
this case, the rack awareness algorithm helps for providing the fault tolerance.
InfoSleuth
The InfoSleuth is the Micro-electronics and Computer technology based system that
involves in the performing of the collection of information and also analyse them across the
networks of the independent information sources (Yu et al. 2017). This architecture has some
distinguishable features including:
Domain based particular metadata enabled expressions are produced from the rich
domain based ontologies which helps to capture the information within the huge range
of domains.
Mapping which relates with the metadata terms from the domain ontologies to
fundamental information are explicitly deposited. These mappings are merged
together or retrieving the information relating with metadata expressions by the
particular query contexts (Ouamer-Ali et al. 2014). Various styles of mapping are
utilized for mapping various domain based ontologies. In this way, it provide the
proper supports to the views of the related information across the world.
Agent technology is utilized for implementing the functionality in order to support the
data brokering, the various pieces of the information can be found within various
agents along with having narrow as well as focused abilities.

8
BIG DATA
According to the architecture of Infosleuth framework, there consists of various
components including:
User agent – The user agent acts as the user’s intelligent pathway to networks of the
Infosleuth agents. This agent involves for handling the requests from the end of the users
through Java applets as well as routing and passes the responses back to users (Devi et al.
2014). This agent is accountable for storing the data for users and also has the responsibility
for maintenance as the user model. Though it is agent based, therefore it may be called as
consumer agent.
Broker agent – The broke agent works as the matchmaker who is accountable for matching
the requests from the user agent to the resource agent so that it can fulfil the request. This
agent takes the requests from the user agent and sent them to the particular ontology
department as per the selection of the location. This agent also takes the requests from the
multi-resource based agent and sent them to the particular agents to obtain the information
based with the specific query of the user.
BIG DATA
According to the architecture of Infosleuth framework, there consists of various
components including:
User agent – The user agent acts as the user’s intelligent pathway to networks of the
Infosleuth agents. This agent involves for handling the requests from the end of the users
through Java applets as well as routing and passes the responses back to users (Devi et al.
2014). This agent is accountable for storing the data for users and also has the responsibility
for maintenance as the user model. Though it is agent based, therefore it may be called as
consumer agent.
Broker agent – The broke agent works as the matchmaker who is accountable for matching
the requests from the user agent to the resource agent so that it can fulfil the request. This
agent takes the requests from the user agent and sent them to the particular ontology
department as per the selection of the location. This agent also takes the requests from the
multi-resource based agent and sent them to the particular agents to obtain the information
based with the specific query of the user.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
9
BIG DATA
Ontology agent – This agent is accountable for managing the formation as well as update and
also query of the ontologies relating with the multiple data domains.
Multi-resource agent – The multi-resource based agents have the responsibility for executing
the ontology oriented queries. It helps to divide the queries within the sub queries depending
on the knowledge of the particular resource agents which can involve for satisfying the query.
Resource agent – This kind of agents act as the intelligent based front-end interface to
information repositories which involves to accept the huge level of the ontology oriented
queries from network and also translate them to the local repository based query language.
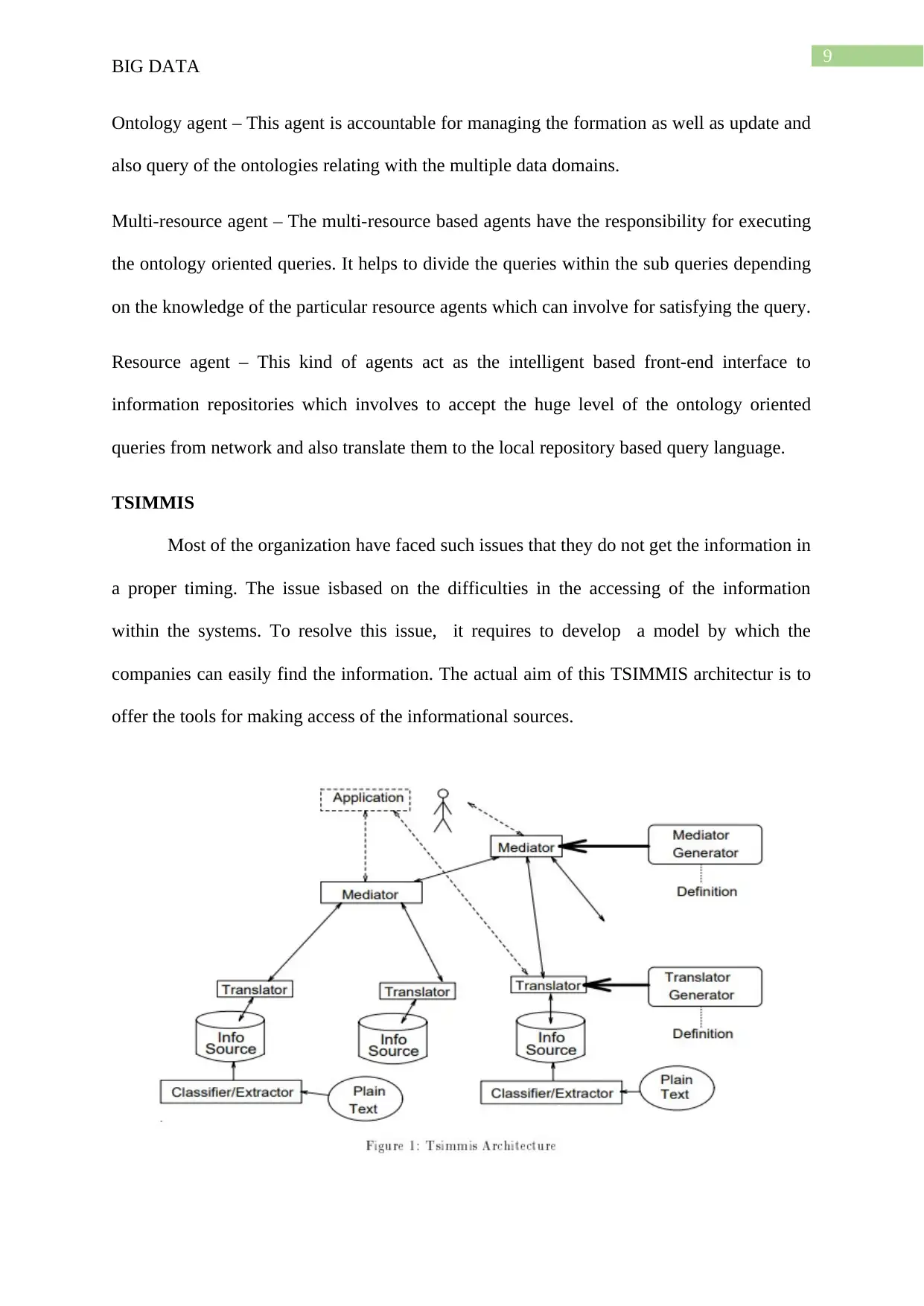
TSIMMIS
Most of the organization have faced such issues that they do not get the information in
a proper timing. The issue isbased on the difficulties in the accessing of the information
within the systems. To resolve this issue, it requires to develop a model by which the
companies can easily find the information. The actual aim of this TSIMMIS architectur is to
offer the tools for making access of the informational sources.
BIG DATA
Ontology agent – This agent is accountable for managing the formation as well as update and
also query of the ontologies relating with the multiple data domains.
Multi-resource agent – The multi-resource based agents have the responsibility for executing
the ontology oriented queries. It helps to divide the queries within the sub queries depending
on the knowledge of the particular resource agents which can involve for satisfying the query.
Resource agent – This kind of agents act as the intelligent based front-end interface to
information repositories which involves to accept the huge level of the ontology oriented
queries from network and also translate them to the local repository based query language.
TSIMMIS
Most of the organization have faced such issues that they do not get the information in
a proper timing. The issue isbased on the difficulties in the accessing of the information
within the systems. To resolve this issue, it requires to develop a model by which the
companies can easily find the information. The actual aim of this TSIMMIS architectur is to
offer the tools for making access of the informational sources.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

10
BIG DATA
According to this figure, there are a vaeiry of components available within this
archirecture. The components are such as:
Translator and common model – This translator helps to convert the underlying data to the
common information source. This translator is often called as wrapper. This component helps
to convert the queries over the inforamtion in common model into the requests so that the
source can perform and also converts the infornation in termsof the common model through
the data source.
Mediators – The mediator acts as the software by which the information can be refined in
such a wat from the multiple of sources. This mediator helps to represent the knowledge that
is mandotory for porocessing of the particular kind of information. This software presents the
knowledge after receiving the inforamtion so that the user can convert the information into
the common model.
System and user interface – Mediators can distribute an interface to the users which is equal
to the translators. Both of the translator as well as mediators help to take the input of the
OEM QL based queries and get back to the output of OEM objects. Thus, the users as well as
nmediators both can obtain the information from the translators. This system allows to te
mediators for accessing of the new sources and refine them to relevant information.
Basic architecture of Big data
The conceptual structure for the Big data is almost equivalent with the traditional
analytics project. But the key difference of these two framework occurs in the area of
execution processing (Dai, Ibrahim and Bassiouni 2016). In case of traditional analytics
project, the analysis of the data can be proceed through the business intelligence tool
installing at the computer and also laptops. But in the case of big data analytics, the
BIG DATA
According to this figure, there are a vaeiry of components available within this
archirecture. The components are such as:
Translator and common model – This translator helps to convert the underlying data to the
common information source. This translator is often called as wrapper. This component helps
to convert the queries over the inforamtion in common model into the requests so that the
source can perform and also converts the infornation in termsof the common model through
the data source.
Mediators – The mediator acts as the software by which the information can be refined in
such a wat from the multiple of sources. This mediator helps to represent the knowledge that
is mandotory for porocessing of the particular kind of information. This software presents the
knowledge after receiving the inforamtion so that the user can convert the information into
the common model.
System and user interface – Mediators can distribute an interface to the users which is equal
to the translators. Both of the translator as well as mediators help to take the input of the
OEM QL based queries and get back to the output of OEM objects. Thus, the users as well as
nmediators both can obtain the information from the translators. This system allows to te
mediators for accessing of the new sources and refine them to relevant information.
Basic architecture of Big data
The conceptual structure for the Big data is almost equivalent with the traditional
analytics project. But the key difference of these two framework occurs in the area of
execution processing (Dai, Ibrahim and Bassiouni 2016). In case of traditional analytics
project, the analysis of the data can be proceed through the business intelligence tool
installing at the computer and also laptops. But in the case of big data analytics, the

11
BIG DATA
processing of information can be distributed through several nodes. This figure depicts the
processing of raw information through big data technologies.
Figure: Architecture of Big data Technology
As discussing in this figure, the primary component is the information itself. The Big
data information can be derived from multiple sources including internal, external as well as
multiple formats or multiple locations and also multiple applications. At the initial timing, the
data behaves as the raw data and to pass this information through this technology it requires
to transform. There are multiple mediums available in the Big data transformation section.
The data can be taken from the middle ware which recommends as web services and in this
case, it requires to call as well as retrieve or process the information. In the transformation
timing, the data is extracted from the sources and after that it requires to transform as well as
load the data. After completion of the transformation of the data it requires to pass the data
through various Big data platform including Hadoop as well as Map reduce or Zookeeper etc.
The execution of the transformed data depends on the characteristics of the Big data whether
it is structured or else unstructured. After applying the information in the Big data platform, it
requires to apply in various platforms like queries, reports as well as OLAP and also Data
BIG DATA
processing of information can be distributed through several nodes. This figure depicts the
processing of raw information through big data technologies.
Figure: Architecture of Big data Technology
As discussing in this figure, the primary component is the information itself. The Big
data information can be derived from multiple sources including internal, external as well as
multiple formats or multiple locations and also multiple applications. At the initial timing, the
data behaves as the raw data and to pass this information through this technology it requires
to transform. There are multiple mediums available in the Big data transformation section.
The data can be taken from the middle ware which recommends as web services and in this
case, it requires to call as well as retrieve or process the information. In the transformation
timing, the data is extracted from the sources and after that it requires to transform as well as
load the data. After completion of the transformation of the data it requires to pass the data
through various Big data platform including Hadoop as well as Map reduce or Zookeeper etc.
The execution of the transformed data depends on the characteristics of the Big data whether
it is structured or else unstructured. After applying the information in the Big data platform, it
requires to apply in various platforms like queries, reports as well as OLAP and also Data
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 16
Related Documents



Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.