Increasing B2B Sales: A Big Data Strategy and Technology Analysis
VerifiedAdded on 2021/06/17
|19
|5373
|76
Project
AI Summary
This project analyzes a Big Data use case focused on increasing business-to-business (B2B) sales. The assignment begins with an introduction to the use case, exploring how a Big Data strategy can be applied. It then delves into defining Big Data, discussing its four V's (Volume, Velocity, Variety, and Veracity), and analyzing how data is used. The project examines the business strategy, required technology stack, and the roles of Data Analytics (DA) and Master Data Management (MDM) in supporting Data Science and Business Intelligence (DS&BI). Various types of NoSQL databases and their applications in Big Data are explored, along with the role of social media and human elements in organizational decision-making. The value creation process of Big Data is discussed, followed by an analysis of cloud computing, data security, and privacy in this context. The project also investigates Data Centers. The analysis provides insights into strategic considerations and technological solutions for leveraging Big Data to enhance sales and decision-making processes. The assignment references several figures and statistics related to cloud usage and mobile data traffic.

Big Data
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Table of Contents
1. Introduction.......................................................................................................................................2
2. Discussion on Business Strategy for a Big Data Use Case..............................................................2
3. Discussion on Business Strategy of Big Data...................................................................................9
4. Discussion on the required Technology Stack...............................................................................10
5. Discussion on Data Analytics and MDM framework to support DS&BI....................................12
6. Investigation the Support of NoSQL Database to the Analytics of Big Data..............................13
7. Discussion on Various types of NoSQL Databases and its usage in Big Data............................14
8. Analyzing the Role of Social Media &Human Elements in Organizationsprocess of Decision
Making.....................................................................................................................................................15
9. Discussion on Value creation Process of Big Data.........................................................................16
10. Conclusion....................................................................................................................................17
References................................................................................................................................................17
1
1. Introduction.......................................................................................................................................2
2. Discussion on Business Strategy for a Big Data Use Case..............................................................2
3. Discussion on Business Strategy of Big Data...................................................................................9
4. Discussion on the required Technology Stack...............................................................................10
5. Discussion on Data Analytics and MDM framework to support DS&BI....................................12
6. Investigation the Support of NoSQL Database to the Analytics of Big Data..............................13
7. Discussion on Various types of NoSQL Databases and its usage in Big Data............................14
8. Analyzing the Role of Social Media &Human Elements in Organizationsprocess of Decision
Making.....................................................................................................................................................15
9. Discussion on Value creation Process of Big Data.........................................................................16
10. Conclusion....................................................................................................................................17
References................................................................................................................................................17
1

1. Introduction
The objective is to analyze a use case on Big Data and carry out discussion on various
dimensions of chosen case. The chosen case is that how to increase sales for business to business
using Big Data Strategy. The evolution and strategy will be applied on this case study. Then the
business initiatives, main objectives will be determined. By conducting in-depth look on the
case, tasks involved in the developed Business strategy will be analyzed. A discussion over
required technology stack of Big Data will be conducted. The DA (Data Analytics) and MDM
(Master Data Management) that support to DS and Business Intelligence will be discussed.
Various types of NoSQL Databases will be studied and its usage in Big Data will be determined.
The decision making process of the business organization will be discussed with the help of role
of the social media and human. The Big Data will be discussed with the help of value creation
process.
2. Discussion on Business Strategy for a Big Data Use Case
Identifying the Big Data Use Case:
The chosen case is that how to increase sales for business to business using Big Data
Strategy
Big Data Definition
The term Big Data is tied in with developing test of the new age innovation which is
composed by concerning monetarily low venture and can extricate substantial volume of an
enormous assortment of information catching, investigation and handling. The meaning of "Huge
Data" changes with the circumstances. Huge Data is a blending of organized, semi-organized and
unstructured information that breaks the boundaries of customary database.
McKinsey and Company characterizes the Big Data as
"Datasets whose size is past the capacity of run of the mill database programming devices
to catch, store, oversee, and break down"
As per the Teradata magazine article, the Big information can be characterized as
"Enormous information surpasses the range of ordinarily utilized equipment conditions and
programming apparatuses to catch, control, oversee and process it inside a middle of the road
slipped by time for its client populace"
2
The objective is to analyze a use case on Big Data and carry out discussion on various
dimensions of chosen case. The chosen case is that how to increase sales for business to business
using Big Data Strategy. The evolution and strategy will be applied on this case study. Then the
business initiatives, main objectives will be determined. By conducting in-depth look on the
case, tasks involved in the developed Business strategy will be analyzed. A discussion over
required technology stack of Big Data will be conducted. The DA (Data Analytics) and MDM
(Master Data Management) that support to DS and Business Intelligence will be discussed.
Various types of NoSQL Databases will be studied and its usage in Big Data will be determined.
The decision making process of the business organization will be discussed with the help of role
of the social media and human. The Big Data will be discussed with the help of value creation
process.
2. Discussion on Business Strategy for a Big Data Use Case
Identifying the Big Data Use Case:
The chosen case is that how to increase sales for business to business using Big Data
Strategy
Big Data Definition
The term Big Data is tied in with developing test of the new age innovation which is
composed by concerning monetarily low venture and can extricate substantial volume of an
enormous assortment of information catching, investigation and handling. The meaning of "Huge
Data" changes with the circumstances. Huge Data is a blending of organized, semi-organized and
unstructured information that breaks the boundaries of customary database.
McKinsey and Company characterizes the Big Data as
"Datasets whose size is past the capacity of run of the mill database programming devices
to catch, store, oversee, and break down"
As per the Teradata magazine article, the Big information can be characterized as
"Enormous information surpasses the range of ordinarily utilized equipment conditions and
programming apparatuses to catch, control, oversee and process it inside a middle of the road
slipped by time for its client populace"
2
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

As per the Jon Kleinberg, a PC researcher at Cornell University, the Big information is
itself dubious yet something is genuine in it. It can be characterized as
"Enormous Data is a slogan for a procedure that can possibly change everything. It is
extremely about new uses and new experiences, less the information itself."
Four V’s of Big Data
Volume: The advantage picked up from the capacity to process huge volume of data is
the primary fascination of huge information examination. Aside from Facebook insights said
above, we keep on generating 294 billion messages each day, in which numerous consider
messages are an obsolete type of correspondence.
Velocity: Data Velocity is the speed at which information is developing and this
outrageous speed is saddling our present data innovation abilities.
Variety: The Big Data can be ordered into organized, semi organized and unstructured
frame.
The organized frame is the most customary method for putting away the information.
Monetary exchanges including motion picture ticket deals, online bill installment, eatery deals,
and so on are for the most part organized and it impacts in a little portion of the information
circling the worldwide systems today. Unstructured information is an essential wellspring of
development in assortment of video or sound information. In a day almost 19 million hours of
music is transferred or downloaded in the free music benefit. There are more than 864,000 hours
of video transferred to YouTube every day. The semi-organized enormous information can be
achieving from numerous sources as content records, XML documents and so forth.
Validity: Validity is a solitary term intended to describe the quality, extraction,
determination, esteem, dependability, setting, and setting for the information. Organized and
unstructured information requires substantial information from the trusted sources and it ought to
take after the information from acquirement to retirement in light of the fact that the trusted
sources are very esteemed than information from another or easygoing sources. After some time,
the new source might be additionally tried and legitimacy of earlier information from that source
may increment or decline.
How analysis done on Big Data
Big Data is generally created from web-based social networking sites, sensors, gadgets,
video/sound, systems, log documents and web, and a lot of it is produced continuously and on an
3
itself dubious yet something is genuine in it. It can be characterized as
"Enormous Data is a slogan for a procedure that can possibly change everything. It is
extremely about new uses and new experiences, less the information itself."
Four V’s of Big Data
Volume: The advantage picked up from the capacity to process huge volume of data is
the primary fascination of huge information examination. Aside from Facebook insights said
above, we keep on generating 294 billion messages each day, in which numerous consider
messages are an obsolete type of correspondence.
Velocity: Data Velocity is the speed at which information is developing and this
outrageous speed is saddling our present data innovation abilities.
Variety: The Big Data can be ordered into organized, semi organized and unstructured
frame.
The organized frame is the most customary method for putting away the information.
Monetary exchanges including motion picture ticket deals, online bill installment, eatery deals,
and so on are for the most part organized and it impacts in a little portion of the information
circling the worldwide systems today. Unstructured information is an essential wellspring of
development in assortment of video or sound information. In a day almost 19 million hours of
music is transferred or downloaded in the free music benefit. There are more than 864,000 hours
of video transferred to YouTube every day. The semi-organized enormous information can be
achieving from numerous sources as content records, XML documents and so forth.
Validity: Validity is a solitary term intended to describe the quality, extraction,
determination, esteem, dependability, setting, and setting for the information. Organized and
unstructured information requires substantial information from the trusted sources and it ought to
take after the information from acquirement to retirement in light of the fact that the trusted
sources are very esteemed than information from another or easygoing sources. After some time,
the new source might be additionally tried and legitimacy of earlier information from that source
may increment or decline.
How analysis done on Big Data
Big Data is generally created from web-based social networking sites, sensors, gadgets,
video/sound, systems, log documents and web, and a lot of it is produced continuously and on an
3
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

expansive scale. Huge information investigation is the way toward inspecting this substantial
measure of various information writes, or huge information, with an end goal to reveal concealed
examples, obscure connections and other valuable data.
In view of the accessible example dataset, it is having following properties:
Information is having organized organization
It would expect joins to ascertain Stock Covariance
It could be sorted out into construction
In genuine condition, information size would be excessively
In view of these criteria and contrasting and the above examination of highlights of these
advances, we can finish up:
In the event that we utilize MapReduce, at that point complex business rationale should
be composed to deal with the joins. We would need to think from delineate diminish point of
view and which specific code scrap will go into guide and which one will go into decrease side.
A considerable measure of advancement exertion needs to go into choosing how delineate
decrease joins will occur. We would not have the capacity to delineate information into mapping
configuration and all endeavors should be taken care of automatically.
In the event that we will utilize Pig, at that point we would not have the capacity to
segment the information, which can be utilized for test preparing from a subset of information by
a specific stock image or specific date or month. Notwithstanding that Pig is more similar to a
scripting dialect which is more appropriate for prototyping and quickly creating MapReduce
based employments. It likewise doesn't give the office to outline information into an unequivocal
composition arrange that appears to be more reasonable for this contextual investigation.
Hive not just gives a recognizable programming model to individuals who know SQL, it
likewise disposes of heaps of standard and here and there precarious coding that we would need
to do in MapReduce programming. On the off chance that we apply Hive to investigate the stock
information, at that point we would have the capacity to use the SQL abilities of Hive-QL and
additionally information can be overseen in a specific outline. It will diminish the improvement
time too and can oversee joins between stock information additionally utilizing Hive-QL which
is obviously really troublesome in MapReduce.
Hive additionally has its thrift servers, by which we can present our Hive questions from
anyplace to the Hive server, which thusly executes them. Hive SQL inquiries are being changed
4
measure of various information writes, or huge information, with an end goal to reveal concealed
examples, obscure connections and other valuable data.
In view of the accessible example dataset, it is having following properties:
Information is having organized organization
It would expect joins to ascertain Stock Covariance
It could be sorted out into construction
In genuine condition, information size would be excessively
In view of these criteria and contrasting and the above examination of highlights of these
advances, we can finish up:
In the event that we utilize MapReduce, at that point complex business rationale should
be composed to deal with the joins. We would need to think from delineate diminish point of
view and which specific code scrap will go into guide and which one will go into decrease side.
A considerable measure of advancement exertion needs to go into choosing how delineate
decrease joins will occur. We would not have the capacity to delineate information into mapping
configuration and all endeavors should be taken care of automatically.
In the event that we will utilize Pig, at that point we would not have the capacity to
segment the information, which can be utilized for test preparing from a subset of information by
a specific stock image or specific date or month. Notwithstanding that Pig is more similar to a
scripting dialect which is more appropriate for prototyping and quickly creating MapReduce
based employments. It likewise doesn't give the office to outline information into an unequivocal
composition arrange that appears to be more reasonable for this contextual investigation.
Hive not just gives a recognizable programming model to individuals who know SQL, it
likewise disposes of heaps of standard and here and there precarious coding that we would need
to do in MapReduce programming. On the off chance that we apply Hive to investigate the stock
information, at that point we would have the capacity to use the SQL abilities of Hive-QL and
additionally information can be overseen in a specific outline. It will diminish the improvement
time too and can oversee joins between stock information additionally utilizing Hive-QL which
is obviously really troublesome in MapReduce.
Hive additionally has its thrift servers, by which we can present our Hive questions from
anyplace to the Hive server, which thusly executes them. Hive SQL inquiries are being changed
4
over into outline occupations by Hive compiler, leaving developers to think past complex
programming and gives chance to center around business issue.
Security and protection
Data sets comprising of so much, perhaps delicate information, and the tools to
concentrate and influence utilization of this data to offer ascent to numerous conceivable
outcomes for unapproved access and utilize. Quite a bit of our conservation of security in the
public eye depends on current wasteful aspects. For instance, individuals are checked by
camcorders in numerous areas – ATMs, accommodation stores, air terminal security lines, and
urban crossing points. Once these sources are organized together, and advanced processing
innovation makes it conceivable to connect and break down these information streams, the
prospect for mishandle winds up noteworthy. Likewise, cloud offices turn into a savvy stage for
vindictive specialists, e.g., to dispatch a hat or to apply gigantic parallelism to break a
cryptosystem. Alongside building up this innovation to empower valuable capacities, we should
make shields to avoid manhandle.
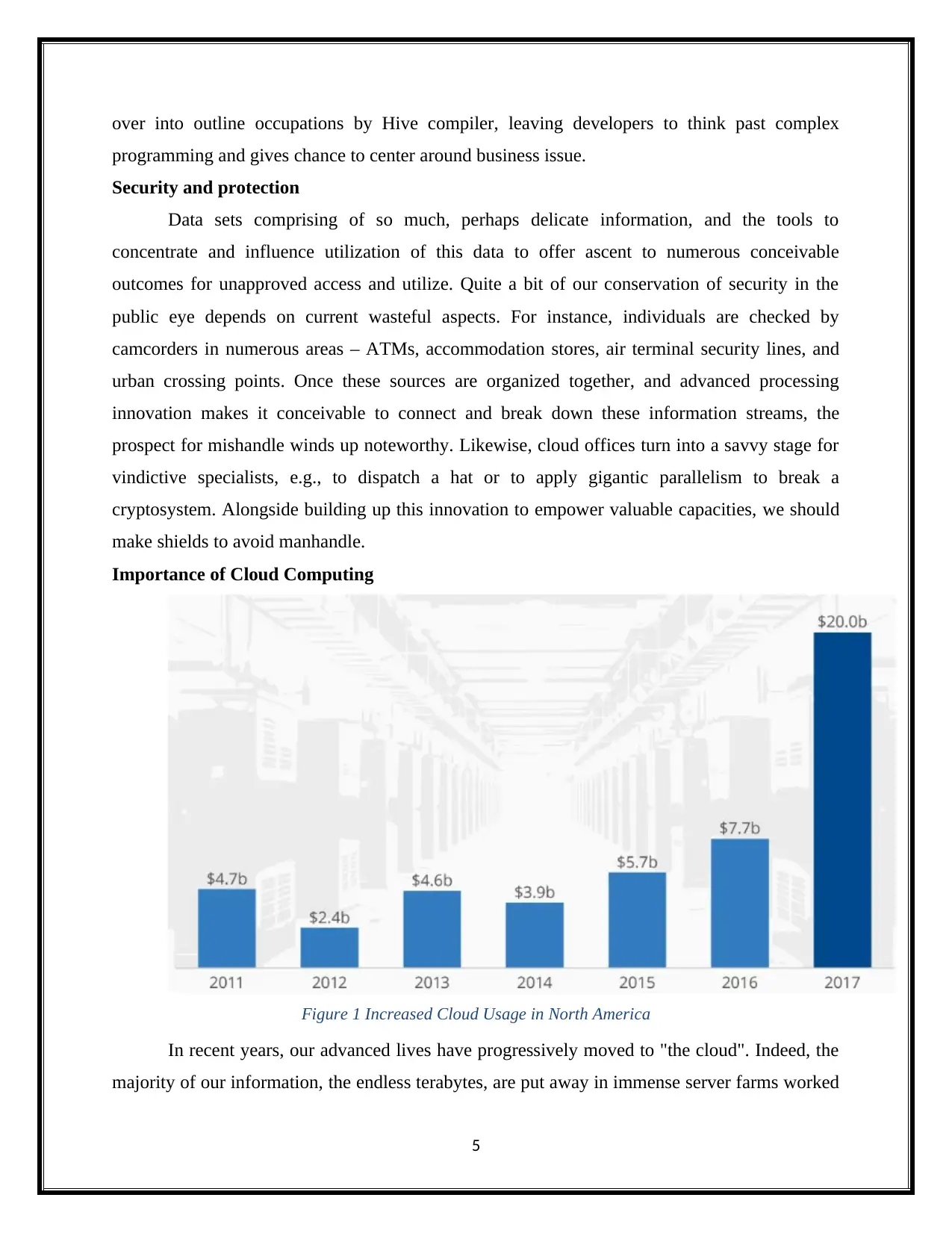
Importance of Cloud Computing
Figure 1 Increased Cloud Usage in North America
In recent years, our advanced lives have progressively moved to "the cloud". Indeed, the
majority of our information, the endless terabytes, are put away in immense server farms worked
5
programming and gives chance to center around business issue.
Security and protection
Data sets comprising of so much, perhaps delicate information, and the tools to
concentrate and influence utilization of this data to offer ascent to numerous conceivable
outcomes for unapproved access and utilize. Quite a bit of our conservation of security in the
public eye depends on current wasteful aspects. For instance, individuals are checked by
camcorders in numerous areas – ATMs, accommodation stores, air terminal security lines, and
urban crossing points. Once these sources are organized together, and advanced processing
innovation makes it conceivable to connect and break down these information streams, the
prospect for mishandle winds up noteworthy. Likewise, cloud offices turn into a savvy stage for
vindictive specialists, e.g., to dispatch a hat or to apply gigantic parallelism to break a
cryptosystem. Alongside building up this innovation to empower valuable capacities, we should
make shields to avoid manhandle.
Importance of Cloud Computing
Figure 1 Increased Cloud Usage in North America
In recent years, our advanced lives have progressively moved to "the cloud". Indeed, the
majority of our information, the endless terabytes, are put away in immense server farms worked
5
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
by our preferred organizations behind the cloud administrations. The current exploration in
distributed computing has prompted a surge sought after for server farms, as the accompanying
diagram outlines.
As indicated by estimates from land look into firm CBRE announced by Recode, North
American server farm venture about tripled in 2017. At $20 billion, a year ago venture surpassed
that of the past three years joined and there's little sign for this upward pattern to end at any point
in the near future.
Figure 2 Share of global cloud and non-cloud mobile data traffic from the year of2014 to 2019
The above shown statistics measurement displays the offer of portable cloud movement
from 2014 to 2019. In 2014, versatile cloud activity represented 81 percent of all worldwide
portable information movement. This offer is anticipated to develop to 90 percent in 2019 at a
CAGR of 60 percent. Portable cloud activity incorporates video spilling, sound gushing, web
based gaming, person to person communication, web perusing and online stockpiling.
6
distributed computing has prompted a surge sought after for server farms, as the accompanying
diagram outlines.
As indicated by estimates from land look into firm CBRE announced by Recode, North
American server farm venture about tripled in 2017. At $20 billion, a year ago venture surpassed
that of the past three years joined and there's little sign for this upward pattern to end at any point
in the near future.
Figure 2 Share of global cloud and non-cloud mobile data traffic from the year of2014 to 2019
The above shown statistics measurement displays the offer of portable cloud movement
from 2014 to 2019. In 2014, versatile cloud activity represented 81 percent of all worldwide
portable information movement. This offer is anticipated to develop to 90 percent in 2019 at a
CAGR of 60 percent. Portable cloud activity incorporates video spilling, sound gushing, web
based gaming, person to person communication, web perusing and online stockpiling.
6
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
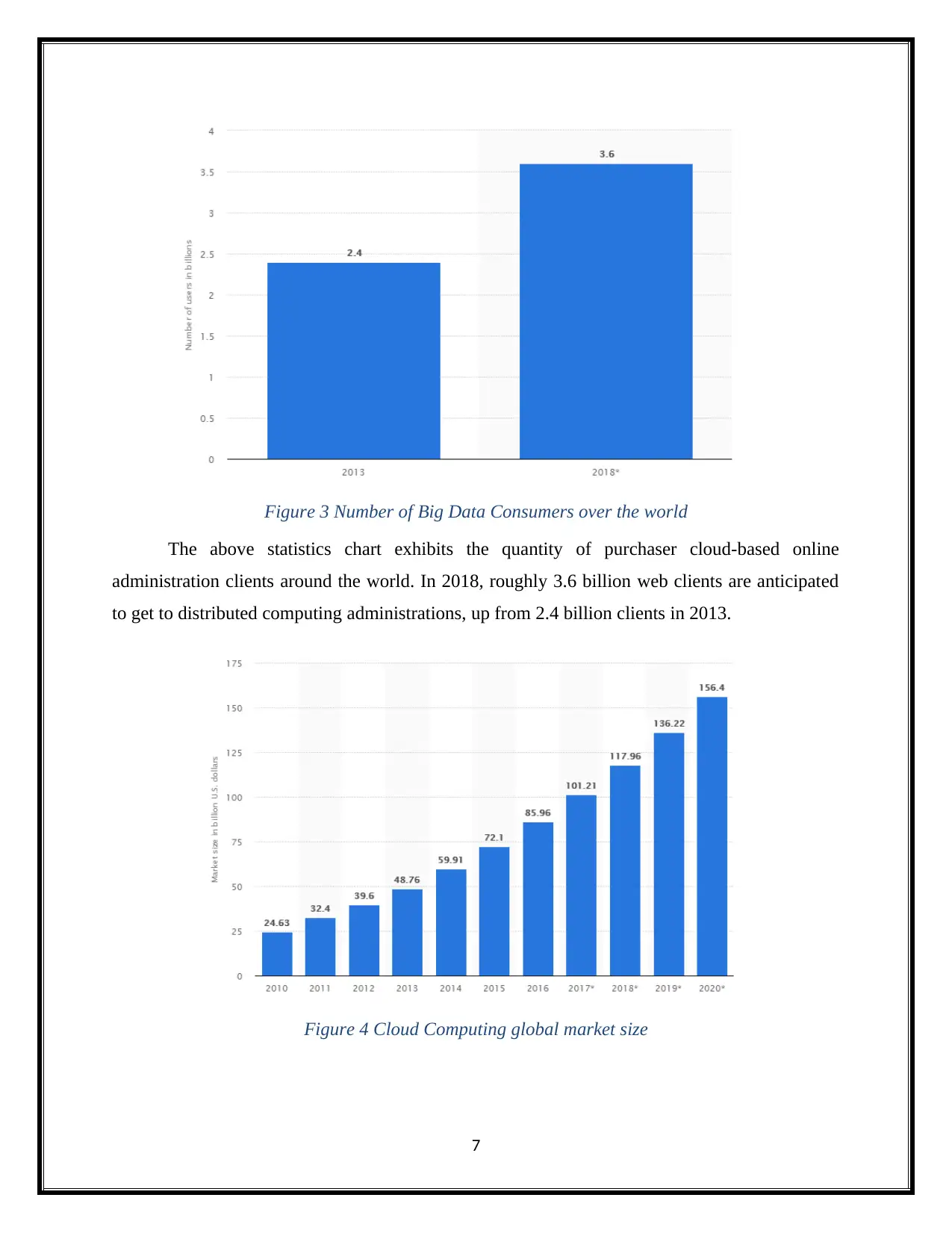
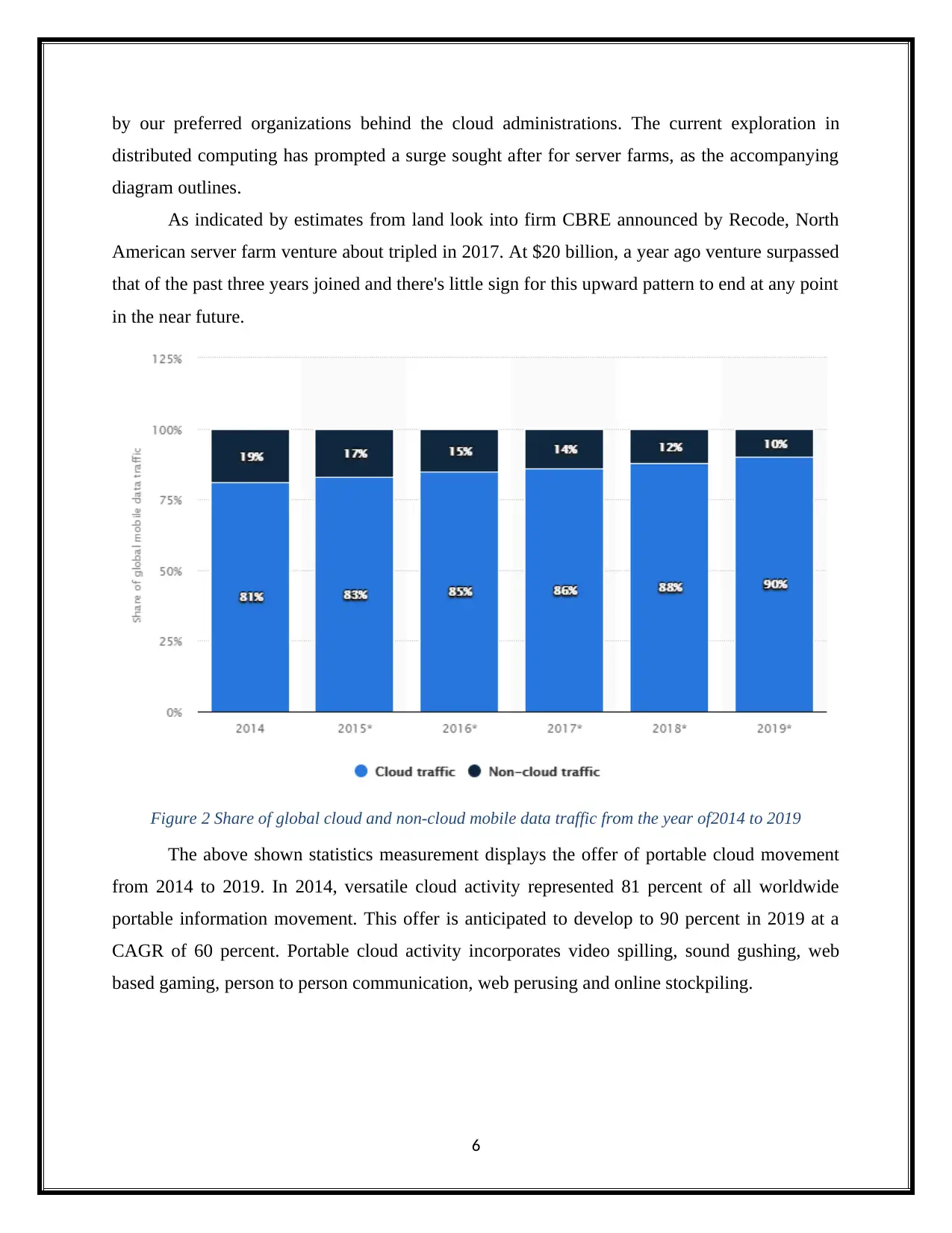
Figure 3 Number of Big Data Consumers over the world
The above statistics chart exhibits the quantity of purchaser cloud-based online
administration clients around the world. In 2018, roughly 3.6 billion web clients are anticipated
to get to distributed computing administrations, up from 2.4 billion clients in 2013.
Figure 4 Cloud Computing global market size
7
The above statistics chart exhibits the quantity of purchaser cloud-based online
administration clients around the world. In 2018, roughly 3.6 billion web clients are anticipated
to get to distributed computing administrations, up from 2.4 billion clients in 2013.
Figure 4 Cloud Computing global market size
7

The above shown chat demonstrates the span of the facilitating and distributed computing
market from 2010 to 2020. In 2018, the market for distributed computing and facilitating
administrations is anticipated to be worth 118 billion U.S. dollars around the world.
Data Security and Privacy in Cloud Computing
Figure 5 Architecture of Data security and Privacy in Cloud
A cryptographic calculation named Diffie-Hellman is proposed for secure
correspondence, which is very unlike the key appropriation administration instrument.
For greater adaptability and improved security, a mixture procedure that joins different
encryption calculations, for example, RSA, 3DES, and arbitrary number generator has been
connected. RSA is helpful for setting up secure correspondence association through advanced
mark based validation while 3DES is especially valuable for encryption of square information. In
addition, a few encryption calculations for guaranteeing the security of client information in the
cloud computing.
Data Centers
Data Centers are progressively executing private cloud programming, which expands on
virtualization to include a level of computerization, client self-administration and
charging/chargeback to server farm organization. The objective is to enable individual clients to
arrangement workloads and other processing assets on-request, without IT regulatory
intercession.
8
market from 2010 to 2020. In 2018, the market for distributed computing and facilitating
administrations is anticipated to be worth 118 billion U.S. dollars around the world.
Data Security and Privacy in Cloud Computing
Figure 5 Architecture of Data security and Privacy in Cloud
A cryptographic calculation named Diffie-Hellman is proposed for secure
correspondence, which is very unlike the key appropriation administration instrument.
For greater adaptability and improved security, a mixture procedure that joins different
encryption calculations, for example, RSA, 3DES, and arbitrary number generator has been
connected. RSA is helpful for setting up secure correspondence association through advanced
mark based validation while 3DES is especially valuable for encryption of square information. In
addition, a few encryption calculations for guaranteeing the security of client information in the
cloud computing.
Data Centers
Data Centers are progressively executing private cloud programming, which expands on
virtualization to include a level of computerization, client self-administration and
charging/chargeback to server farm organization. The objective is to enable individual clients to
arrangement workloads and other processing assets on-request, without IT regulatory
intercession.
8
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

Data Centre outlines should likewise actualize sound wellbeing and security hones. For
instance, security is frequently reflected in the design of entryways and access passageways,
which must suit the development of vast, inconvenient IT hardware, and allow workers to access
and repair the foundation. Fire concealment is another key wellbeing territory, and the broad
utilization of delicate, high-vitality electrical and electronic hardware blocks basic sprinklers.
Rather, server farms frequently utilize earth well-disposed concoction fire concealment
frameworks, which adequately keep a fire from oxygen while moderating inadvertent blow-back
to the hardware. Since the server farm is additionally a center business resource, far reaching
safety efforts, similar to identification access and video reconnaissance, help to recognize and
anticipate impropriety by workers, temporary workers and gatecrashers.
3. Discussion on Business Strategy of Big Data
Organizations have since quite a while ago utilized information investigation to help
guide their system to expand benefits. In a perfect world information investigation wipes out a
significant part of the mystery associated with attempting to comprehend customers, rather
fundamentally following information examples to best build business strategies and tasks to limit
vulnerability. Not exclusively does investigation figure out what may draw in new clients,
regularly examination perceives existing examples in information to help better serve existing
clients, which is ordinarily more financially savvy than setting up new business.
In a consistently changing business world subject to innumerable variations, examination
gives organizations the edge in perceiving changing atmospheres so they can take start proper
activity to remain focused. Close by investigation, distributed computing is additionally helping
make business more viable and the union of the two mists and examination could enable
organizations to store, decipher, and process their huge information to better address their
customers' issues.
A significant part of the advantage from information examination originates from its
capacity to perceive designs in a set and make expectations in regards to past encounters.
Normally the procedure is alluded to as information mining, which basically implies finding
designs in informational collections to better comprehend patterns. With every one of the
advantages information investigation and huge information offer, quite a bit of their potential is
9
instance, security is frequently reflected in the design of entryways and access passageways,
which must suit the development of vast, inconvenient IT hardware, and allow workers to access
and repair the foundation. Fire concealment is another key wellbeing territory, and the broad
utilization of delicate, high-vitality electrical and electronic hardware blocks basic sprinklers.
Rather, server farms frequently utilize earth well-disposed concoction fire concealment
frameworks, which adequately keep a fire from oxygen while moderating inadvertent blow-back
to the hardware. Since the server farm is additionally a center business resource, far reaching
safety efforts, similar to identification access and video reconnaissance, help to recognize and
anticipate impropriety by workers, temporary workers and gatecrashers.
3. Discussion on Business Strategy of Big Data
Organizations have since quite a while ago utilized information investigation to help
guide their system to expand benefits. In a perfect world information investigation wipes out a
significant part of the mystery associated with attempting to comprehend customers, rather
fundamentally following information examples to best build business strategies and tasks to limit
vulnerability. Not exclusively does investigation figure out what may draw in new clients,
regularly examination perceives existing examples in information to help better serve existing
clients, which is ordinarily more financially savvy than setting up new business.
In a consistently changing business world subject to innumerable variations, examination
gives organizations the edge in perceiving changing atmospheres so they can take start proper
activity to remain focused. Close by investigation, distributed computing is additionally helping
make business more viable and the union of the two mists and examination could enable
organizations to store, decipher, and process their huge information to better address their
customers' issues.
A significant part of the advantage from information examination originates from its
capacity to perceive designs in a set and make expectations in regards to past encounters.
Normally the procedure is alluded to as information mining, which basically implies finding
designs in informational collections to better comprehend patterns. With every one of the
advantages information investigation and huge information offer, quite a bit of their potential is
9
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

missed in light of the fact that workers need fast, dependable access to said data. Gartner gauges
85% of Fortune 500 organizations don't receive the full reward of their enormous information
investigation on account of absence of availability to information, making them miss potential
chances to better associate with and address customers' issues.
As investigation moves towards cloud drives, information examination picks up openness
as organization workers can get to organization data remotely from any area, liberating them
from being tied to neighborhood systems and accordingly making information more available.
As of late, Time Warner divulged its information examination cloud framework, which enables
their 4,000 workers to better use deals information with expectations of preparing them to build
net revenues.
4. Discussion on the required Technology Stack
Choosing the privilege Big Data technology stack is an unquestionable requirement for
organizations to deal with their information legitimately. Along these lines, organizations will
profit by awesome Customer Relationship Management (CRM) and better basic leadership
aptitudes. This will prompt productive turnovers for wander.
Depending upon our requirements and accessibility, choose the innovation stack that best
fits our application. In the event that we have a place with advanced promoting, we may need to
spend more bucks on the ongoing choice, showcase mechanization, and CRM. Along these lines,
design as per how we utilize.
Utilize devices like SAS and SPSS for in-house factual examination and better
demonstrating abilities. These apparatuses are known for giving better information change
offices. Since there is a tremendous volume of information, this procedure won't not be basic.
The parallelism of information won't not be effortlessly conceivable. There are numerous
complexities included which requests group aptitude and high necessities on the innovation
stack.
These statistics-centric workloads have unique traits in the following regions:
Reaction time requirements — consisting of actual-time versus non-actual-time.
Data types:
Dependent records that fits in well with traditional RDBMS schemas.
10
85% of Fortune 500 organizations don't receive the full reward of their enormous information
investigation on account of absence of availability to information, making them miss potential
chances to better associate with and address customers' issues.
As investigation moves towards cloud drives, information examination picks up openness
as organization workers can get to organization data remotely from any area, liberating them
from being tied to neighborhood systems and accordingly making information more available.
As of late, Time Warner divulged its information examination cloud framework, which enables
their 4,000 workers to better use deals information with expectations of preparing them to build
net revenues.
4. Discussion on the required Technology Stack
Choosing the privilege Big Data technology stack is an unquestionable requirement for
organizations to deal with their information legitimately. Along these lines, organizations will
profit by awesome Customer Relationship Management (CRM) and better basic leadership
aptitudes. This will prompt productive turnovers for wander.
Depending upon our requirements and accessibility, choose the innovation stack that best
fits our application. In the event that we have a place with advanced promoting, we may need to
spend more bucks on the ongoing choice, showcase mechanization, and CRM. Along these lines,
design as per how we utilize.
Utilize devices like SAS and SPSS for in-house factual examination and better
demonstrating abilities. These apparatuses are known for giving better information change
offices. Since there is a tremendous volume of information, this procedure won't not be basic.
The parallelism of information won't not be effortlessly conceivable. There are numerous
complexities included which requests group aptitude and high necessities on the innovation
stack.
These statistics-centric workloads have unique traits in the following regions:
Reaction time requirements — consisting of actual-time versus non-actual-time.
Data types:
Dependent records that fits in well with traditional RDBMS schemas.
10

Semi-structured records, like XML or e mail.
Completely unstructured information, such as binary or sensor statistics.
Processing complexity:
Simple statistics operations, which include combination, kind or upload/download, with a
low compute-to-records-get admission to ratio.
Medium compute complexity operations on records, inclusive of sample matching, seek
or encryption.
Complicated processing, inclusive of video encoding/decoding, analytics, prediction, and
so on.
Massive statistics has added forth the difficulty of “database as the bottleneck” for a lot
of those data-centric workloads, because of their widely varying requirements.
Some of strategies had been proposed to address the changing desires of information
management driven by means of massive records and the Cloud. Those include:
Information replication, which creates more than one copies of the databases. The copies
may be examine-handiest, with one master replica wherein updates occur, after which are
propagated to the copies — or the copies can be study-write, which imposes the complexity of
making sure the consistency of the more than one copies.
Reminiscence caching of regularly accessed records, as popularized by means of the memory
cached architecture.
From the traditional “Shared everything Scale-up” structure, the focal point shifted to
“Shared nothing Scale-out” architectures. The shared-not anything structure allows independent
nodes as the constructing blocks, with facts replicated, maintained and accessed. Database
sharing is a way of horizontal partitioning in a database, which typically walls its information
amongst many nodes on different databases, with replication of the application’s information via
synchronization. Shared-disk clustered databases, including Oracle RAC, use a distinctive model
to attain scalability, based on a “shared-the whole lot” structure that is predicated upon high-pace
connections among servers. The dynamic scalability required for cloud database offerings
nevertheless stays elusive in both these methods. “Shared-nothing” architectures require time-
ingesting and annoying facts rebalancing when nodes are delivered/deleted. While node
addition/deletion is quicker in the “Shared-everything” architecture, they have got scaling
troubles with growing node counts.
11
Completely unstructured information, such as binary or sensor statistics.
Processing complexity:
Simple statistics operations, which include combination, kind or upload/download, with a
low compute-to-records-get admission to ratio.
Medium compute complexity operations on records, inclusive of sample matching, seek
or encryption.
Complicated processing, inclusive of video encoding/decoding, analytics, prediction, and
so on.
Massive statistics has added forth the difficulty of “database as the bottleneck” for a lot
of those data-centric workloads, because of their widely varying requirements.
Some of strategies had been proposed to address the changing desires of information
management driven by means of massive records and the Cloud. Those include:
Information replication, which creates more than one copies of the databases. The copies
may be examine-handiest, with one master replica wherein updates occur, after which are
propagated to the copies — or the copies can be study-write, which imposes the complexity of
making sure the consistency of the more than one copies.
Reminiscence caching of regularly accessed records, as popularized by means of the memory
cached architecture.
From the traditional “Shared everything Scale-up” structure, the focal point shifted to
“Shared nothing Scale-out” architectures. The shared-not anything structure allows independent
nodes as the constructing blocks, with facts replicated, maintained and accessed. Database
sharing is a way of horizontal partitioning in a database, which typically walls its information
amongst many nodes on different databases, with replication of the application’s information via
synchronization. Shared-disk clustered databases, including Oracle RAC, use a distinctive model
to attain scalability, based on a “shared-the whole lot” structure that is predicated upon high-pace
connections among servers. The dynamic scalability required for cloud database offerings
nevertheless stays elusive in both these methods. “Shared-nothing” architectures require time-
ingesting and annoying facts rebalancing when nodes are delivered/deleted. While node
addition/deletion is quicker in the “Shared-everything” architecture, they have got scaling
troubles with growing node counts.
11
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 19
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.