MIT-BDS-02: Big Data and Data Science - Database and ML Report
VerifiedAdded on 2022/12/23
|10
|2698
|1
Report
AI Summary
This report delves into the realm of big data and data science, examining the crucial differences between SQL and NoSQL database management systems within the context of a supermarket chain, Safeway. It emphasizes the advantages of NoSQL, particularly MongoDB, for handling the flexibility and scalability requirements of big data applications. The report then transitions to machine learning, outlining its role in extracting meaningful insights from vast datasets and discussing supervised learning techniques. Furthermore, it explores text mining approaches for analyzing textual data. The report concludes with a practical presentation component, showcasing a MongoDB implementation using a "GameData.xlsx" dataset, illustrating data processing, querying, and analysis to derive valuable insights, highlighting the flexibility of MongoDB in handling complex data structures. The author reflects on the assignment's contribution to their understanding of big data technologies.

Report
Component (a)
Background
The Safeway fresh and whole foods is a supermarket chain that provides its customer with all
types of groceries and other household needs at one place. The company have a vast database
that stores, record of sales, stock details, transactions both online and offline, purchase and sales
of products and so on. The company also maintains a software to sold their products online. As
more and more of the people are now transitioning towards online purchase, the company
collects the information from variety of social media platforms to understand the buying trends
of customers. (Hobbs, 2017).
SQL vs NoSQL
Safeway are upgrading their database and considering the implementation of either SQL or
NoSQL database management system for the same. At first place Safeway should consider this
high level differences between SQL and NoSQL before choosing one of them for storage and
management of their big data.
1. SQL Databases are the Relational Databases RDBMS whereas NoSQL are the distributed
or non-relational databases.
2. In the SQL databases the data is in the form of tables where it is represented in n number
of rows, on the other hand the NoSQL databases are in the form of documents, key-value
pairs, wide-column stores or graph databases, where no standard schema definition is
followed.
3. There is a predefined schema in SQL databases whereas for NoSQL databases there is
dynamic schema and the data is unstructured.
4. SQL databases are scaled vertically whereas NoSQL databases are scaled horizontally.
This means to scale SQL database requires increment in hardware horse-power such as
increasing the RAM, SSD, CPU power on a single server, whereas for NoSQL databases
the number of database servers in the resource pools needs to be increased in order to
reduce load.
5. As the name suggest, structured query language is used in SQL for the definition and
manipulation of data. In NoSQL documents collection is the primary focus of queries, it
is also sometimes called Unstructured Query Language UnQL, and its syntax are
different as per the databases.
6. Oracle, MySQL, Postgres, SQLite and MS-SQL are some examples of SQL databases.
MongoDB, Redis, Cassandra, CouchDB, Hbase and RavenDB are some examples of
NoSQL databases.
7. For processing complex queries in an intensive environment SQL database are best suited
and more powerful as compared to NoSQL which lacks in standard interface to perform
these complex queries.
Component (a)
Background
The Safeway fresh and whole foods is a supermarket chain that provides its customer with all
types of groceries and other household needs at one place. The company have a vast database
that stores, record of sales, stock details, transactions both online and offline, purchase and sales
of products and so on. The company also maintains a software to sold their products online. As
more and more of the people are now transitioning towards online purchase, the company
collects the information from variety of social media platforms to understand the buying trends
of customers. (Hobbs, 2017).
SQL vs NoSQL
Safeway are upgrading their database and considering the implementation of either SQL or
NoSQL database management system for the same. At first place Safeway should consider this
high level differences between SQL and NoSQL before choosing one of them for storage and
management of their big data.
1. SQL Databases are the Relational Databases RDBMS whereas NoSQL are the distributed
or non-relational databases.
2. In the SQL databases the data is in the form of tables where it is represented in n number
of rows, on the other hand the NoSQL databases are in the form of documents, key-value
pairs, wide-column stores or graph databases, where no standard schema definition is
followed.
3. There is a predefined schema in SQL databases whereas for NoSQL databases there is
dynamic schema and the data is unstructured.
4. SQL databases are scaled vertically whereas NoSQL databases are scaled horizontally.
This means to scale SQL database requires increment in hardware horse-power such as
increasing the RAM, SSD, CPU power on a single server, whereas for NoSQL databases
the number of database servers in the resource pools needs to be increased in order to
reduce load.
5. As the name suggest, structured query language is used in SQL for the definition and
manipulation of data. In NoSQL documents collection is the primary focus of queries, it
is also sometimes called Unstructured Query Language UnQL, and its syntax are
different as per the databases.
6. Oracle, MySQL, Postgres, SQLite and MS-SQL are some examples of SQL databases.
MongoDB, Redis, Cassandra, CouchDB, Hbase and RavenDB are some examples of
NoSQL databases.
7. For processing complex queries in an intensive environment SQL database are best suited
and more powerful as compared to NoSQL which lacks in standard interface to perform
these complex queries.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

8. For big data NoSQL database are highly preferred as they fits best to store hierarchical
and large set of data due to its key-value pair storage method just like JSON
9. For complex and high transactional application SQL databases are best suited and are
more stable and reliable in terms of integrity and atomicity of data. While NoSQL
databases are also used for the purpose they are not as stable and comparable as SQL for
complex and high load transactional application.
10. The SQL database vendors provides excellent support to the business clients particularly
in large deployments. For NoSQL database still have dependency on community support
and setup and deployment on large scale are done by experts that are only few available
in the market.
11. SQL databases are known for their ACID properties that is Atomicity, Consistency,
Isolation and Durability. On the other hand NoSQL properties follows Brewers CAP
theorem which stands for Consistency, Availability and Partition tolerance (Raje,
Jagdale, 2017).
From the above difference it can be understood that to choose between SQL and NoSQL for the
storage and management of Big Data, NoSQL can be an optimal choice. Since a variety of data
is associated with the big data application, which is collected from various sources such as
mobile phones, social media etc. This data can vary from personal information of the user to
sensor data and so on. For handling of these data flexibility and scalability plays an important
role. For vertical scalability of SQL system, it requires to spend a huge amount of money on the
single hardware node. For big data applications NoSQL provides horizontal scalability which
can be easily implemented just by adding a server node to the system, allowing sharing of the
loads between nodes. Also NoSQL databases are more flexible as compared to the SQL as it is
not schema restricted as in case of relational database (Pore &. Pawar, 2015).
Implications and outcomes of choosing correct database
management system:
For the Safeway inc. it is important that the system should be friendly for the brand managers as
well as for employees in the company. This means that the system should not only be easy to use
and understand but should provide the organization with maximum benefits. As the selected
database system would be handled by a number of professionals including, IT team, marketing
professionals, database developers and others, they should have enough knowledge regarding
system and its functioning to avoid any issues. It should be ensured that the chosen system
should be scalable and flexible enough so that it can be integrated with their current software and
at the same time should be able to grow with the rapidly growing demands of the organization,
while being cost effective and sustainable at the same time. Overall, while selecting the right
database system the most important criteria is that every team should be able to utilize the system
without much efforts to make the most valuable decisions from the data contained in it.
Machine learning and Big data
In today’s era of technological advancement massive amount of data is generated every
second which needs to be stored and processed with equal intensity as it is generated. While
and large set of data due to its key-value pair storage method just like JSON
9. For complex and high transactional application SQL databases are best suited and are
more stable and reliable in terms of integrity and atomicity of data. While NoSQL
databases are also used for the purpose they are not as stable and comparable as SQL for
complex and high load transactional application.
10. The SQL database vendors provides excellent support to the business clients particularly
in large deployments. For NoSQL database still have dependency on community support
and setup and deployment on large scale are done by experts that are only few available
in the market.
11. SQL databases are known for their ACID properties that is Atomicity, Consistency,
Isolation and Durability. On the other hand NoSQL properties follows Brewers CAP
theorem which stands for Consistency, Availability and Partition tolerance (Raje,
Jagdale, 2017).
From the above difference it can be understood that to choose between SQL and NoSQL for the
storage and management of Big Data, NoSQL can be an optimal choice. Since a variety of data
is associated with the big data application, which is collected from various sources such as
mobile phones, social media etc. This data can vary from personal information of the user to
sensor data and so on. For handling of these data flexibility and scalability plays an important
role. For vertical scalability of SQL system, it requires to spend a huge amount of money on the
single hardware node. For big data applications NoSQL provides horizontal scalability which
can be easily implemented just by adding a server node to the system, allowing sharing of the
loads between nodes. Also NoSQL databases are more flexible as compared to the SQL as it is
not schema restricted as in case of relational database (Pore &. Pawar, 2015).
Implications and outcomes of choosing correct database
management system:
For the Safeway inc. it is important that the system should be friendly for the brand managers as
well as for employees in the company. This means that the system should not only be easy to use
and understand but should provide the organization with maximum benefits. As the selected
database system would be handled by a number of professionals including, IT team, marketing
professionals, database developers and others, they should have enough knowledge regarding
system and its functioning to avoid any issues. It should be ensured that the chosen system
should be scalable and flexible enough so that it can be integrated with their current software and
at the same time should be able to grow with the rapidly growing demands of the organization,
while being cost effective and sustainable at the same time. Overall, while selecting the right
database system the most important criteria is that every team should be able to utilize the system
without much efforts to make the most valuable decisions from the data contained in it.
Machine learning and Big data
In today’s era of technological advancement massive amount of data is generated every
second which needs to be stored and processed with equal intensity as it is generated. While

these massive data has significant potential, new ways of learning and thinking are required
to interpret these data to extract meaningful results and address the challenges that comes
along (Qiu, Wu, Ding, et al. 2016). Over the past decade, the data intensive fields such as
astronomy, medicine and biology has widely adopted machine learning techniques to mine
hidden information within the data. Machine learning is a research field focusing on the
performance, properties and theories of learning algorithms and system. Machine learning is
an interdisciplinary field based on the various disciplines of engineering, science and
mathematics such as optimization theory, artificial intelligence, cognitive science, statistics,
optimal theory, information theory and so on. The main function of Machine Learning is to
utilize past experience to find a good prediction automatically with a good classifier
(Muhammad & Yan, 2015). There are two simple process in which machine learning model
work: training and testing. The machine take the input in the form of samples of training data
and the features of data are learned by the learner or learning algorithm to build the model.
For the testing process, with the use of execution engine the learning model makes the
prediction for the production or test data. The output from the learning model is the tagged
data which provides with the final prediction (Qiu, Wu, Ding, Xu & Feng, 2016). The most
common technique of classification problems is the supervised learning. In this technique,
the input and the desired output are feed and with the help of the algorithm the mapping
function from input to the output is learned. The supervised learning have further two main
categories, Classification and regression. In classification the target class is predicted as
output, while in regression continuous values are predicted as output (Vennapusa &
Bhyrapuneni, 2019). However there are challenges in supervised learning when it comes to
dealing with big data. Currently, there are ubiquitous classification problems with huge scale
data, and the traditional classification algorithm cannot process the big data properly. The
learning methods available today are shallow structured architectures which does not fit for
growing complex structures of input data (Xie et. al, 2018).
Approaches in text mining
Text mining is the process of finding data from textual databases by extracting stimulating and
substantive models. It is a multi-disciplinary field that includes, information retrieval, machine
learning, data mining and computational semantics. There is a growing usage of text-based
techniques in the industry, web application, internet, academia and other fields (Talib, Hanif,
Ayesha & Fatima, 2016). Organizations requires analysis to develop a marketing strategy, such
as their target audience, geographic details of the audience, so on. These information helps them
to gain insights and discover future trends to target their marketing strategies. Text mining can
help in the areas, such as CRM, clean emails, social network analysis and extract features,
visualization, predictive and trend analysis. As these data are stored in the text frames in
databases, the text extraction strategies can be implemented on text files to analyze its data. All
the data that is generated and analyzed can be compiled and reviewed further to ensure more
tailored marketing efforts.
to interpret these data to extract meaningful results and address the challenges that comes
along (Qiu, Wu, Ding, et al. 2016). Over the past decade, the data intensive fields such as
astronomy, medicine and biology has widely adopted machine learning techniques to mine
hidden information within the data. Machine learning is a research field focusing on the
performance, properties and theories of learning algorithms and system. Machine learning is
an interdisciplinary field based on the various disciplines of engineering, science and
mathematics such as optimization theory, artificial intelligence, cognitive science, statistics,
optimal theory, information theory and so on. The main function of Machine Learning is to
utilize past experience to find a good prediction automatically with a good classifier
(Muhammad & Yan, 2015). There are two simple process in which machine learning model
work: training and testing. The machine take the input in the form of samples of training data
and the features of data are learned by the learner or learning algorithm to build the model.
For the testing process, with the use of execution engine the learning model makes the
prediction for the production or test data. The output from the learning model is the tagged
data which provides with the final prediction (Qiu, Wu, Ding, Xu & Feng, 2016). The most
common technique of classification problems is the supervised learning. In this technique,
the input and the desired output are feed and with the help of the algorithm the mapping
function from input to the output is learned. The supervised learning have further two main
categories, Classification and regression. In classification the target class is predicted as
output, while in regression continuous values are predicted as output (Vennapusa &
Bhyrapuneni, 2019). However there are challenges in supervised learning when it comes to
dealing with big data. Currently, there are ubiquitous classification problems with huge scale
data, and the traditional classification algorithm cannot process the big data properly. The
learning methods available today are shallow structured architectures which does not fit for
growing complex structures of input data (Xie et. al, 2018).
Approaches in text mining
Text mining is the process of finding data from textual databases by extracting stimulating and
substantive models. It is a multi-disciplinary field that includes, information retrieval, machine
learning, data mining and computational semantics. There is a growing usage of text-based
techniques in the industry, web application, internet, academia and other fields (Talib, Hanif,
Ayesha & Fatima, 2016). Organizations requires analysis to develop a marketing strategy, such
as their target audience, geographic details of the audience, so on. These information helps them
to gain insights and discover future trends to target their marketing strategies. Text mining can
help in the areas, such as CRM, clean emails, social network analysis and extract features,
visualization, predictive and trend analysis. As these data are stored in the text frames in
databases, the text extraction strategies can be implemented on text files to analyze its data. All
the data that is generated and analyzed can be compiled and reviewed further to ensure more
tailored marketing efforts.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
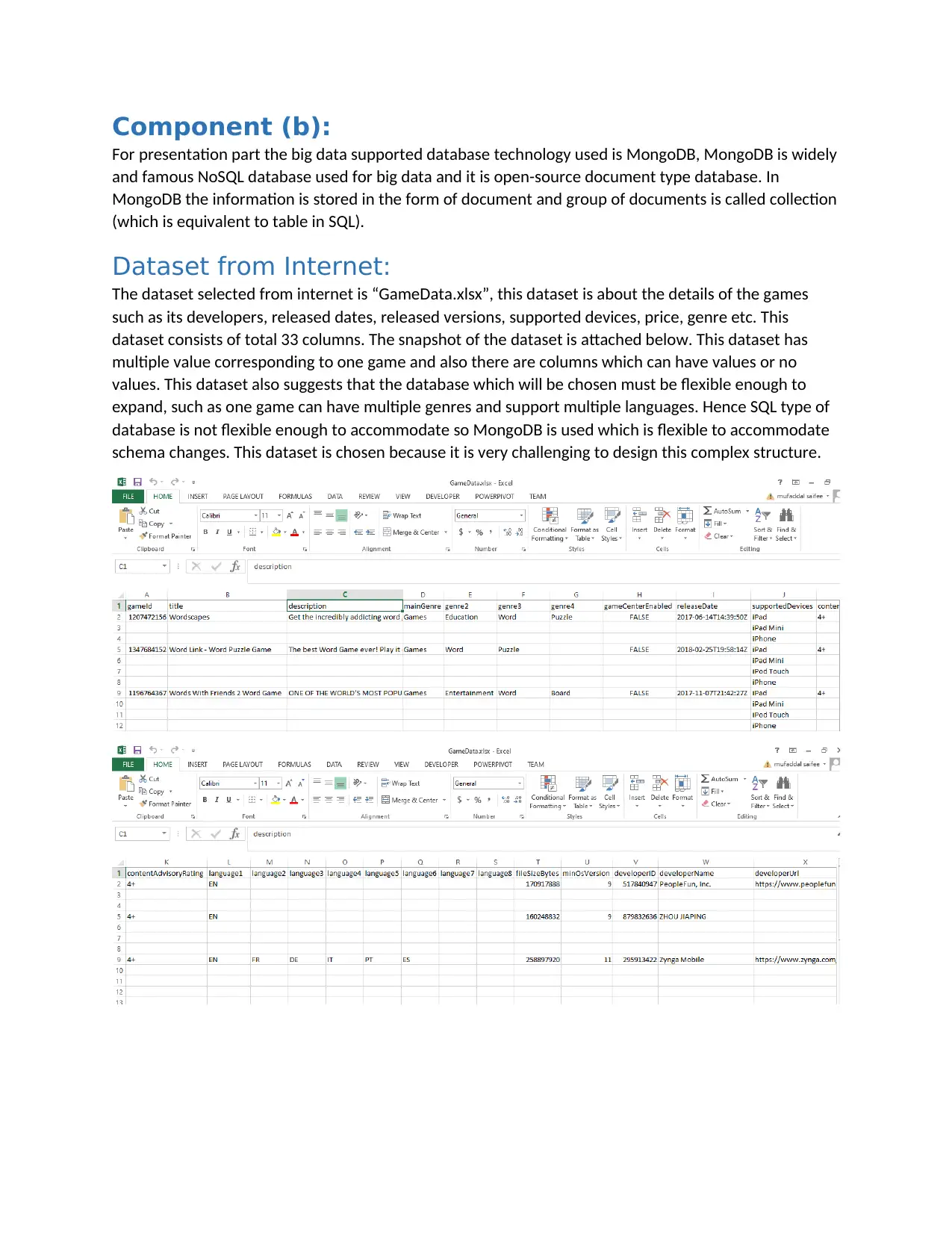
Component (b):
For presentation part the big data supported database technology used is MongoDB, MongoDB is widely
and famous NoSQL database used for big data and it is open-source document type database. In
MongoDB the information is stored in the form of document and group of documents is called collection
(which is equivalent to table in SQL).
Dataset from Internet:
The dataset selected from internet is “GameData.xlsx”, this dataset is about the details of the games
such as its developers, released dates, released versions, supported devices, price, genre etc. This
dataset consists of total 33 columns. The snapshot of the dataset is attached below. This dataset has
multiple value corresponding to one game and also there are columns which can have values or no
values. This dataset also suggests that the database which will be chosen must be flexible enough to
expand, such as one game can have multiple genres and support multiple languages. Hence SQL type of
database is not flexible enough to accommodate so MongoDB is used which is flexible to accommodate
schema changes. This dataset is chosen because it is very challenging to design this complex structure.
For presentation part the big data supported database technology used is MongoDB, MongoDB is widely
and famous NoSQL database used for big data and it is open-source document type database. In
MongoDB the information is stored in the form of document and group of documents is called collection
(which is equivalent to table in SQL).
Dataset from Internet:
The dataset selected from internet is “GameData.xlsx”, this dataset is about the details of the games
such as its developers, released dates, released versions, supported devices, price, genre etc. This
dataset consists of total 33 columns. The snapshot of the dataset is attached below. This dataset has
multiple value corresponding to one game and also there are columns which can have values or no
values. This dataset also suggests that the database which will be chosen must be flexible enough to
expand, such as one game can have multiple genres and support multiple languages. Hence SQL type of
database is not flexible enough to accommodate so MongoDB is used which is flexible to accommodate
schema changes. This dataset is chosen because it is very challenging to design this complex structure.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Processing the dataset:
Processing of this dataset in MongoDB, MongoDB follows JSON like structure. The database is
created with the “dbase_games” Inside it collection is created with the name games and index is
created on Gameid.
Here to insert the record the document structure created is as follow:
Genres is created as array object as it will flexible any number of genres (in dataset there are
separate columns for genres). Similarly Language, SupportedDevices, Developers and
LatestVersion are selected as nested documents.
Processing of this dataset in MongoDB, MongoDB follows JSON like structure. The database is
created with the “dbase_games” Inside it collection is created with the name games and index is
created on Gameid.
Here to insert the record the document structure created is as follow:
Genres is created as array object as it will flexible any number of genres (in dataset there are
separate columns for genres). Similarly Language, SupportedDevices, Developers and
LatestVersion are selected as nested documents.
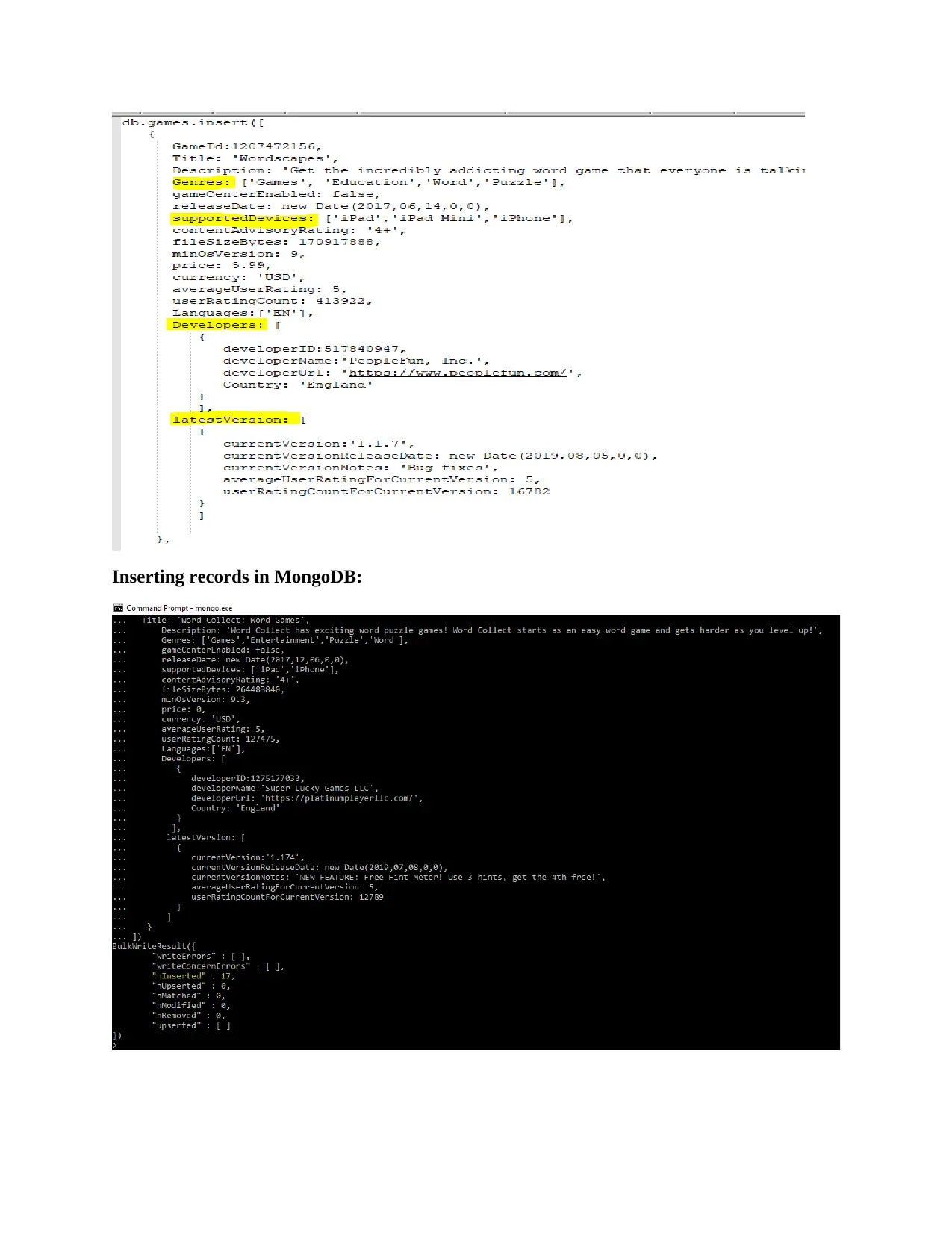
Inserting records in MongoDB:
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

Insight on the dataset:
The first thing to get the insight on the dataset is to check the records in it and select few columns from
it, listing all games and its title from the database. Here the command used is “find” with projection of
Title column as 1 (to display) and 0 for Id to hide.
Searching all games which are free and not chargeable, the query will fetch all those records which has
price equal to 0. There are 8 games which are free. Here filter is applied on column “price” the operator
used is “$eq”
Now select the developer’s names from the database:
The first thing to get the insight on the dataset is to check the records in it and select few columns from
it, listing all games and its title from the database. Here the command used is “find” with projection of
Title column as 1 (to display) and 0 for Id to hide.
Searching all games which are free and not chargeable, the query will fetch all those records which has
price equal to 0. There are 8 games which are free. Here filter is applied on column “price” the operator
used is “$eq”
Now select the developer’s names from the database:
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
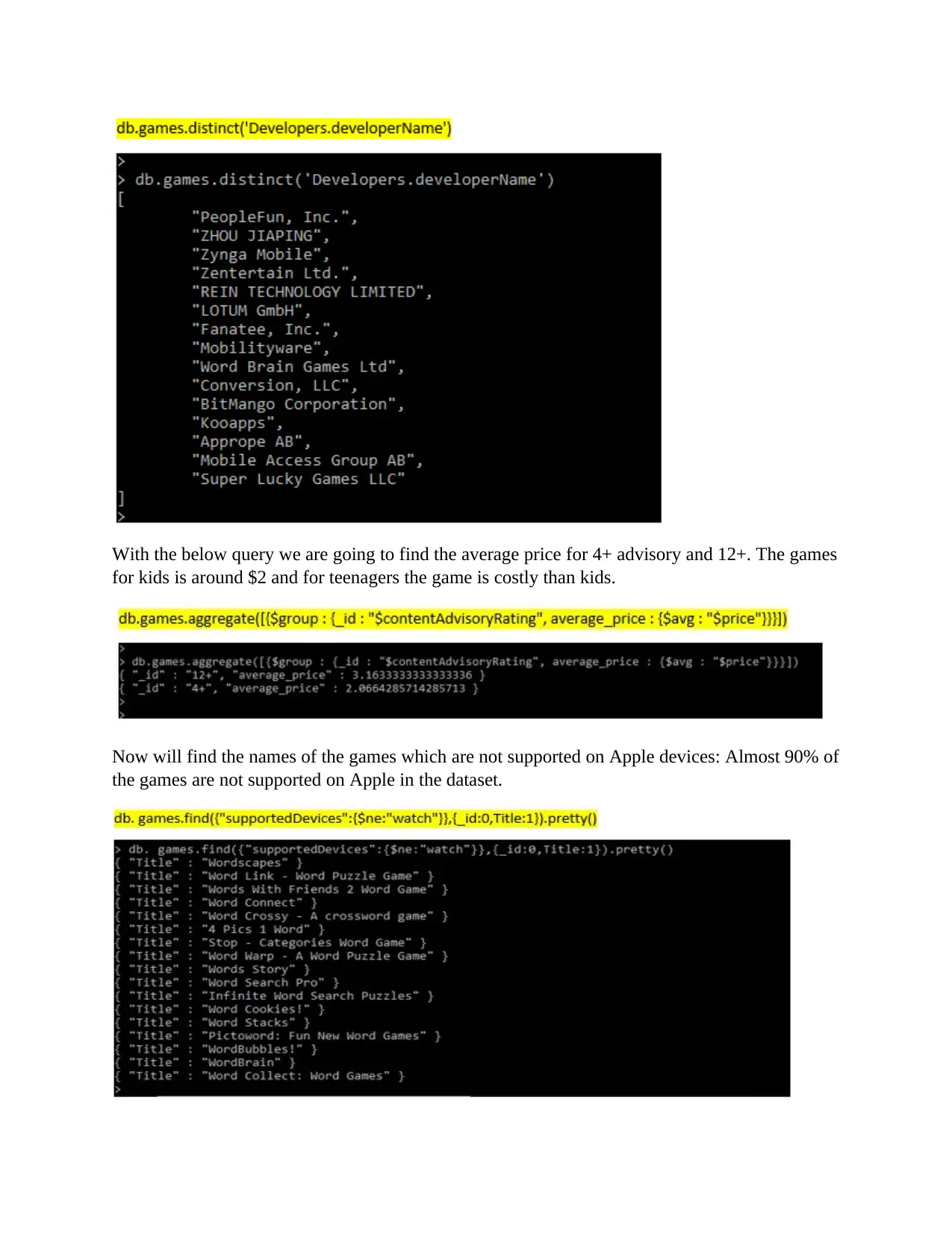
With the below query we are going to find the average price for 4+ advisory and 12+. The games
for kids is around $2 and for teenagers the game is costly than kids.
Now will find the names of the games which are not supported on Apple devices: Almost 90% of
the games are not supported on Apple in the dataset.
for kids is around $2 and for teenagers the game is costly than kids.
Now will find the names of the games which are not supported on Apple devices: Almost 90% of
the games are not supported on Apple in the dataset.

Games which are economical and are below $4.
On Analyzing the dataset with the help of MongoDB we can see that MongoDB is flexible to
accommodate the changes and querying the database is really easy as it has functions which are
utilized for query. The dataset suggest that kids games are less expensive than the teenager
games and also there wide number of games which are below $4 and can be easily purchased.
Additionally this dataset suggest that Games which supports the Apple devices is not freely
available and cannot be downloaded directly from internet.
Reflection:
This assignment helped me to understand the difference between the SQL and NoSQL, closely
understand the issues and implications associated with SQL and features present in NoSQL. In the
second part got the opportunity to work on the Big Data technology “MongoDB” and this practical
helped me to know that how with NoSQL schema can be defined and how to create database having
flexible and can be changed at runtime. Multiple queries are fired on the database and got the insight on
the dataset by performing queries.
References:
Hobbs, T. (2017). Why Morrisons is right to bring back the Safeway brand. Retrieved
from: https://www.marketingweek.com/morrisons-brings-back-safeway-brand/
On Analyzing the dataset with the help of MongoDB we can see that MongoDB is flexible to
accommodate the changes and querying the database is really easy as it has functions which are
utilized for query. The dataset suggest that kids games are less expensive than the teenager
games and also there wide number of games which are below $4 and can be easily purchased.
Additionally this dataset suggest that Games which supports the Apple devices is not freely
available and cannot be downloaded directly from internet.
Reflection:
This assignment helped me to understand the difference between the SQL and NoSQL, closely
understand the issues and implications associated with SQL and features present in NoSQL. In the
second part got the opportunity to work on the Big Data technology “MongoDB” and this practical
helped me to know that how with NoSQL schema can be defined and how to create database having
flexible and can be changed at runtime. Multiple queries are fired on the database and got the insight on
the dataset by performing queries.
References:
Hobbs, T. (2017). Why Morrisons is right to bring back the Safeway brand. Retrieved
from: https://www.marketingweek.com/morrisons-brings-back-safeway-brand/
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

Muhammad, I. & Yan, Z. (2015). Supervised Machine Learning Approaches: A Survey.
International Journal of Soft Computing 5(3), 946-952. Retrieved from:
https://www.researchgate.net/publication/301779181_SUPERVISED_MACHINE_LEA
RNING_APPROACHES_A_SURVEY
Nasteski, V. (2017). An overview of the supervised machine learning methods.
DOI: 10.20544/HORIZONS.B.04.1.17.P05.
Pore, S. &. Pawar, S. B. (2015). Comparative Study of SQL & NoSQL Databases. International
Journal of Advanced Research in Computer Engineering & Technology, 4(5). 2015.
http://ijarcet.org/wp-content/uploads/IJARCET-VOL-4-ISSUE-5-1747-1753.pdf
Qiu, J., Wu, Q., Ding, G., Xu, Y. & Feng, S. (2016). A survey of machine learning for big data
processing. EURASIP Journal of Advances in Signal Processing, 2016(67). DOI:
https://doi.org/10.1186/s13634-016-0355-x
Raje, A, & Jagdale, A. (2017). Sql Vs NoSql: NewSql, The Solution For Big Data. IOSR
Journal of Computer Engineering, 45-51. Retrieved from:
http://www.iosrjournals.org/iosr-jce/papers/Conf.17025-2017/Volume-2/8.%2045-
51.pdf?id=7557
Talib, R., Hanif, M. K., Ayesha, S. & Fatima, F. (2016). Text Mining: Techniques, Applications
and Issues. International Journal of Advanced Computer Science and Applications,
7(11). Retrieved from: https://thesai.org/Downloads/Volume7No11/Paper_53-
Text_Mining_Techniques_Applications_and_Issues.pdf
Vennapusa, M. & Bhyrapuneni, S. (2019). A Comprehensive Study of Machine Learning
Mechanisms on Big data. International Journal of Recent Technology and Engineering,
7(6S2). Retrieved from:
https://www.ijrte.org/wp-content/uploads/papers/v7i6s2/F10990476S219.pdf
Xie, J. et. al, (2018). A Survey on Machine Learning-Based Mobile Big Data Analysis:
Challenges and Applications. Wireless Communication and Mobile computing,
2018, 8738613, 1-19. DOI: https://doi.org/10.1155/2018/8738613
International Journal of Soft Computing 5(3), 946-952. Retrieved from:
https://www.researchgate.net/publication/301779181_SUPERVISED_MACHINE_LEA
RNING_APPROACHES_A_SURVEY
Nasteski, V. (2017). An overview of the supervised machine learning methods.
DOI: 10.20544/HORIZONS.B.04.1.17.P05.
Pore, S. &. Pawar, S. B. (2015). Comparative Study of SQL & NoSQL Databases. International
Journal of Advanced Research in Computer Engineering & Technology, 4(5). 2015.
http://ijarcet.org/wp-content/uploads/IJARCET-VOL-4-ISSUE-5-1747-1753.pdf
Qiu, J., Wu, Q., Ding, G., Xu, Y. & Feng, S. (2016). A survey of machine learning for big data
processing. EURASIP Journal of Advances in Signal Processing, 2016(67). DOI:
https://doi.org/10.1186/s13634-016-0355-x
Raje, A, & Jagdale, A. (2017). Sql Vs NoSql: NewSql, The Solution For Big Data. IOSR
Journal of Computer Engineering, 45-51. Retrieved from:
http://www.iosrjournals.org/iosr-jce/papers/Conf.17025-2017/Volume-2/8.%2045-
51.pdf?id=7557
Talib, R., Hanif, M. K., Ayesha, S. & Fatima, F. (2016). Text Mining: Techniques, Applications
and Issues. International Journal of Advanced Computer Science and Applications,
7(11). Retrieved from: https://thesai.org/Downloads/Volume7No11/Paper_53-
Text_Mining_Techniques_Applications_and_Issues.pdf
Vennapusa, M. & Bhyrapuneni, S. (2019). A Comprehensive Study of Machine Learning
Mechanisms on Big data. International Journal of Recent Technology and Engineering,
7(6S2). Retrieved from:
https://www.ijrte.org/wp-content/uploads/papers/v7i6s2/F10990476S219.pdf
Xie, J. et. al, (2018). A Survey on Machine Learning-Based Mobile Big Data Analysis:
Challenges and Applications. Wireless Communication and Mobile computing,
2018, 8738613, 1-19. DOI: https://doi.org/10.1155/2018/8738613
1 out of 10
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.