Analysing Big Data Complexities with an Effective Data Model
VerifiedAdded on 2023/04/19
|137
|48157
|187
Report
AI Summary
This research report explores solutions for managing big data challenges using Hadoop and MapReduce technologies. It analyzes the complexities and impact of big data, proposing an effective data management model to enhance storage and data availability. The proposed architecture focuses on managing interactions between components, addressing issues from social networking platforms and IoT applications. The model aims to systematically arrange big data in service and infrastructure formats, ensuring confidentiality, reliability, and accuracy. The report details the implementation of the model for inventory management, utilizing Spark streaming and MongoDB to provide real-time reports and alerts on commodity availability, demonstrating its success in optimizing inventory control.

Big Data Modelling
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Big Data Modelling
Executive Summary
In recent years, the researchers are working to provide a solution for managing the problems
related to big data environment in an effective and efficient manner. There are two major
technologies which are used for dealing with big data which are named as Hadoop file system
and Map reduce technologies. The large volume of big data requires special platform for
managing the data effectively in the simplified format so as to increase the level of data
availability and reliability. The purpose of this research program is to analyse the
complexities and impact of big data on the application and propose an effective data
management model for overcoming the problems related to the big data structured format.
The proposed data model helps in increasing the storage capability of the data format. The
designing of the big data architecture depends on the technologies used in developing the
infrastructure. The focus should be given on managing the interaction between the
components.
The aim of the research is to analyse the problems related to the management plan of big data
available due to excessive use of social networking platform and IOT applications. In this
paper, we are going to present the data modelling techniques which systematically arrange
the big data in service and infrastructure formats.
The proposed data model should be capable of handling voluminous data in a systematic
format for securing the information confidentiality, reliability, and accuracy. The
consideration should be given on the diversification of the data available from different
sources such as social networking platform, IOT architecture, and artificial intelligence. The
significance of the research study is to come up with the big data model for easy storage and
secured management of data available in large volume. The proposed architecture is the user
friendly management of inventory data to get effective results for solving the problem of big
data management. The development of the user interface provides suitability to the user to get
interactive with the features and availability of the product in the warehouse to be delivered
on time. The operations related to the inventory help in developing the interface to provide
statistics view of the data organization. It helps in finding the sales ratio to the availability of
the product in the warehouse. The implementation of the big data model proposed
architecture for managing the inventory of the organization helps the user to take proactive
action for managing and synchronizing the availability of the commodity. The danger to the
availability of the inventory can be predicted by comparing the present availability with the
threshold normal value. The Spark streaming process is used for getting the required and
1
Executive Summary
In recent years, the researchers are working to provide a solution for managing the problems
related to big data environment in an effective and efficient manner. There are two major
technologies which are used for dealing with big data which are named as Hadoop file system
and Map reduce technologies. The large volume of big data requires special platform for
managing the data effectively in the simplified format so as to increase the level of data
availability and reliability. The purpose of this research program is to analyse the
complexities and impact of big data on the application and propose an effective data
management model for overcoming the problems related to the big data structured format.
The proposed data model helps in increasing the storage capability of the data format. The
designing of the big data architecture depends on the technologies used in developing the
infrastructure. The focus should be given on managing the interaction between the
components.
The aim of the research is to analyse the problems related to the management plan of big data
available due to excessive use of social networking platform and IOT applications. In this
paper, we are going to present the data modelling techniques which systematically arrange
the big data in service and infrastructure formats.
The proposed data model should be capable of handling voluminous data in a systematic
format for securing the information confidentiality, reliability, and accuracy. The
consideration should be given on the diversification of the data available from different
sources such as social networking platform, IOT architecture, and artificial intelligence. The
significance of the research study is to come up with the big data model for easy storage and
secured management of data available in large volume. The proposed architecture is the user
friendly management of inventory data to get effective results for solving the problem of big
data management. The development of the user interface provides suitability to the user to get
interactive with the features and availability of the product in the warehouse to be delivered
on time. The operations related to the inventory help in developing the interface to provide
statistics view of the data organization. It helps in finding the sales ratio to the availability of
the product in the warehouse. The implementation of the big data model proposed
architecture for managing the inventory of the organization helps the user to take proactive
action for managing and synchronizing the availability of the commodity. The danger to the
availability of the inventory can be predicted by comparing the present availability with the
threshold normal value. The Spark streaming process is used for getting the required and
1

Big Data Modelling
updated information of the data from the data warehouse. The MongoDB is used for reading
the information of the inventory from the batch processing unit. The notification and alert
signals are sent to the user for taking proactive action plan to keep the balance between the
availability of the commodity according to the demand placed by the user.
It can be concluded that the proposed model for managing the big data of inventory control
system is successful in getting the real time report of the commodity availability in the
warehouse. The user is alarmed with the alert signal sent to the mobile phones for informing
about the underflow and overflow condition of the data. The distributed environment is
developed for optimizing the sharing of the object in performing parallel processing.
2
updated information of the data from the data warehouse. The MongoDB is used for reading
the information of the inventory from the batch processing unit. The notification and alert
signals are sent to the user for taking proactive action plan to keep the balance between the
availability of the commodity according to the demand placed by the user.
It can be concluded that the proposed model for managing the big data of inventory control
system is successful in getting the real time report of the commodity availability in the
warehouse. The user is alarmed with the alert signal sent to the mobile phones for informing
about the underflow and overflow condition of the data. The distributed environment is
developed for optimizing the sharing of the object in performing parallel processing.
2
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

Big Data Modelling
Contents
Executive Summary...................................................................................................................1
Chapter 1: Introduction..............................................................................................................4
Research Aim.........................................................................................................................9
Research Problem...................................................................................................................9
Research Questions..............................................................................................................10
Thesis Scope.........................................................................................................................10
Thesis Contribution..............................................................................................................11
Thesis Outline.......................................................................................................................11
Chapter 2: Literature Review...................................................................................................12
Introduction..........................................................................................................................12
Background...........................................................................................................................13
Big Data Modelling..............................................................................................................16
Tools and Technologies in relation to big data:...................................................................17
Big Data Modelling and Challenges and research issues.....................................................21
Big Data modelling progress and research trends................................................................26
Chapter 3: Research Methodology...........................................................................................56
Chapter 4: Proposed Big Data Architecture.............................................................................71
Related work:........................................................................................................................73
Proposed Architecture..........................................................................................................77
Description of the System Architecture...............................................................................84
Pre-Processing functions:.....................................................................................................94
Chapter 5: Implementation and Results.................................................................................101
Chapter 6: Conclusion............................................................................................................124
References..............................................................................................................................126
3
Contents
Executive Summary...................................................................................................................1
Chapter 1: Introduction..............................................................................................................4
Research Aim.........................................................................................................................9
Research Problem...................................................................................................................9
Research Questions..............................................................................................................10
Thesis Scope.........................................................................................................................10
Thesis Contribution..............................................................................................................11
Thesis Outline.......................................................................................................................11
Chapter 2: Literature Review...................................................................................................12
Introduction..........................................................................................................................12
Background...........................................................................................................................13
Big Data Modelling..............................................................................................................16
Tools and Technologies in relation to big data:...................................................................17
Big Data Modelling and Challenges and research issues.....................................................21
Big Data modelling progress and research trends................................................................26
Chapter 3: Research Methodology...........................................................................................56
Chapter 4: Proposed Big Data Architecture.............................................................................71
Related work:........................................................................................................................73
Proposed Architecture..........................................................................................................77
Description of the System Architecture...............................................................................84
Pre-Processing functions:.....................................................................................................94
Chapter 5: Implementation and Results.................................................................................101
Chapter 6: Conclusion............................................................................................................124
References..............................................................................................................................126
3
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Big Data Modelling
Chapter 1: Introduction
The enormous use of internet results in generating terabytes of data. The generation of huge
amount of data results in the critical problem for retrieving the relevant information from the
ocean of information within a fraction of seconds. The birth of technologies based on internet
of things (IOT) and cloud computing architecture requires a significant management schemes
for handling the accuracy and reliability of data (Adam and et.al., 2014 ). The structured
approach is required for managing the big data format for increasing the availability of the
data on the request placed by the user. The evolution of technologies in various domains such
as medical, government, banking, and many more increases the pressure on the management
of the data in structured way. In last few decades, the relational database is used for managing
the data in proper format and efficient in meeting the request and response placed by the user
(Acharjya and Ahmed, 2016). The inclusion of social media and IOT environment generates
the data in terabytes and petabytes which requires an effective system for meeting the
requirement of data availability. In recent years, the researchers are working to provide a
solution for managing the problems related to big data environment in an effective and
efficient manner. There are two major technologies which are used for dealing with big data
which are named as Hadoop file system and Map reduce technologies (Alam and et.al.,
2014). The big data is characterised as 5Vs which are named as velocity, variety, veracity,
volume, and value. The velocity of the data can be judged by analysing the process related to
data generation and collection. The velocity of the data transmission increases the efficiency
of the real time architecture of the system. The large amount of data generated due to the
inclusion of IOT application and social media networking characterise the big data volume.
The accuracy of the data is responsible for application usability which means big data value.
The value of the data can be measured in terms of monetization. The data is available in
variety of formats which has to be synchronized in structured, semi-structured or unstructured
manner (Chebtko, Kashlev, and Lu, 2017). The data analysis and management process is
required for synchronizing the data in the systematic manner for simultaneous retrieval of it
to meet the demand raised by the user. The reliability and trustworthiness is the measure of
the data veracity. The incredibility of the IOT application depends upon the accuracy of the
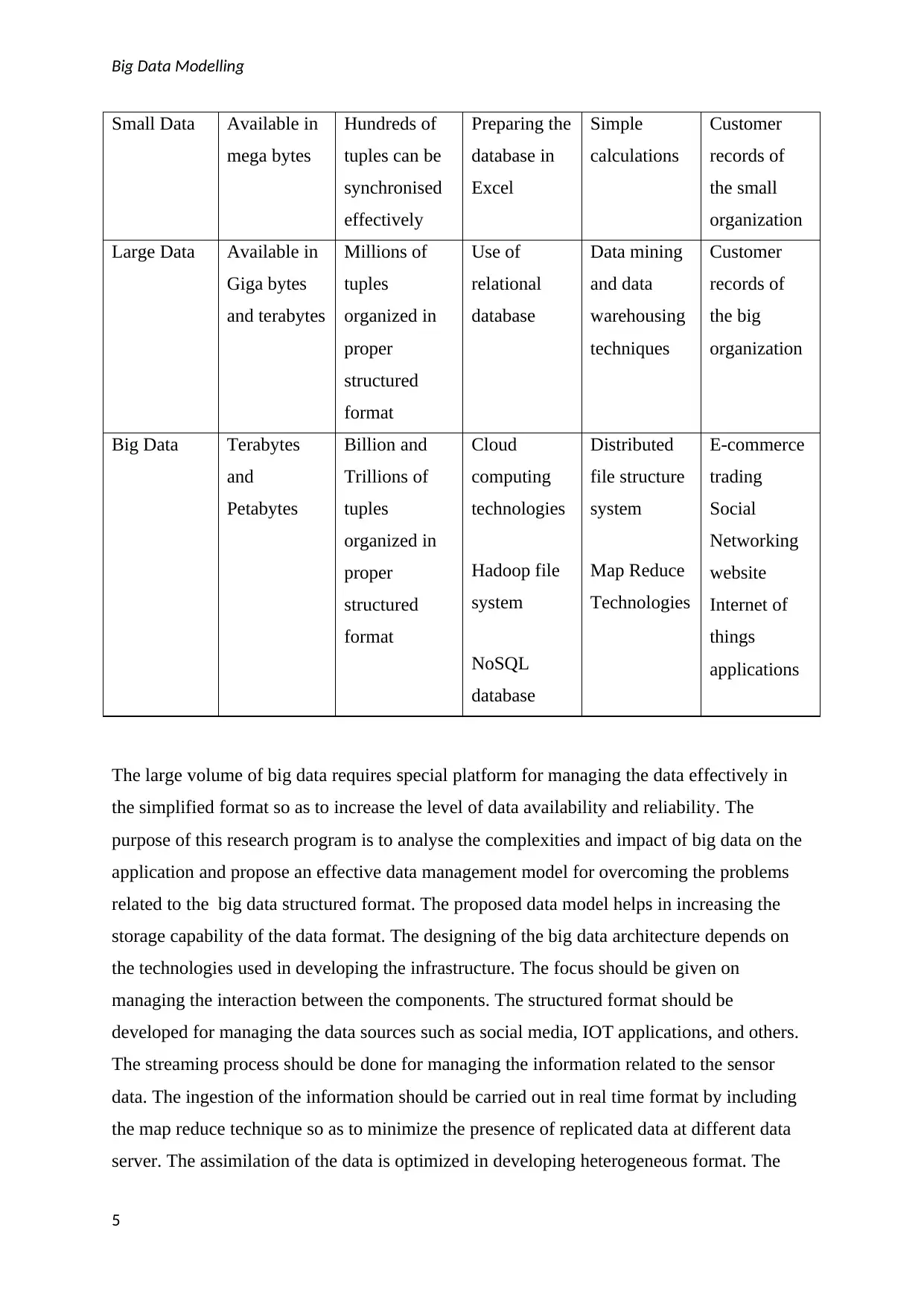
data retrieved in different formats. The data is available in three formats which are classified
in the table below:
Type of data Size of data Characteristics Use of
different tool
Methods
used
For examples
4
Chapter 1: Introduction
The enormous use of internet results in generating terabytes of data. The generation of huge
amount of data results in the critical problem for retrieving the relevant information from the
ocean of information within a fraction of seconds. The birth of technologies based on internet
of things (IOT) and cloud computing architecture requires a significant management schemes
for handling the accuracy and reliability of data (Adam and et.al., 2014 ). The structured
approach is required for managing the big data format for increasing the availability of the
data on the request placed by the user. The evolution of technologies in various domains such
as medical, government, banking, and many more increases the pressure on the management
of the data in structured way. In last few decades, the relational database is used for managing
the data in proper format and efficient in meeting the request and response placed by the user
(Acharjya and Ahmed, 2016). The inclusion of social media and IOT environment generates
the data in terabytes and petabytes which requires an effective system for meeting the
requirement of data availability. In recent years, the researchers are working to provide a
solution for managing the problems related to big data environment in an effective and
efficient manner. There are two major technologies which are used for dealing with big data
which are named as Hadoop file system and Map reduce technologies (Alam and et.al.,
2014). The big data is characterised as 5Vs which are named as velocity, variety, veracity,
volume, and value. The velocity of the data can be judged by analysing the process related to
data generation and collection. The velocity of the data transmission increases the efficiency
of the real time architecture of the system. The large amount of data generated due to the
inclusion of IOT application and social media networking characterise the big data volume.
The accuracy of the data is responsible for application usability which means big data value.
The value of the data can be measured in terms of monetization. The data is available in
variety of formats which has to be synchronized in structured, semi-structured or unstructured
manner (Chebtko, Kashlev, and Lu, 2017). The data analysis and management process is
required for synchronizing the data in the systematic manner for simultaneous retrieval of it
to meet the demand raised by the user. The reliability and trustworthiness is the measure of
the data veracity. The incredibility of the IOT application depends upon the accuracy of the
data retrieved in different formats. The data is available in three formats which are classified
in the table below:
Type of data Size of data Characteristics Use of
different tool
Methods
used
For examples
4
Big Data Modelling
Small Data Available in
mega bytes
Hundreds of
tuples can be
synchronised
effectively
Preparing the
database in
Excel
Simple
calculations
Customer
records of
the small
organization
Large Data Available in
Giga bytes
and terabytes
Millions of
tuples
organized in
proper
structured
format
Use of
relational
database
Data mining
and data
warehousing
techniques
Customer
records of
the big
organization
Big Data Terabytes
and
Petabytes
Billion and
Trillions of
tuples
organized in
proper
structured
format
Cloud
computing
technologies
Hadoop file
system
NoSQL
database
Distributed
file structure
system
Map Reduce
Technologies
E-commerce
trading
Social
Networking
website
Internet of
things
applications
The large volume of big data requires special platform for managing the data effectively in
the simplified format so as to increase the level of data availability and reliability. The
purpose of this research program is to analyse the complexities and impact of big data on the
application and propose an effective data management model for overcoming the problems
related to the big data structured format. The proposed data model helps in increasing the
storage capability of the data format. The designing of the big data architecture depends on
the technologies used in developing the infrastructure. The focus should be given on
managing the interaction between the components. The structured format should be
developed for managing the data sources such as social media, IOT applications, and others.
The streaming process should be done for managing the information related to the sensor
data. The ingestion of the information should be carried out in real time format by including
the map reduce technique so as to minimize the presence of replicated data at different data
server. The assimilation of the data is optimized in developing heterogeneous format. The
5
Small Data Available in
mega bytes
Hundreds of
tuples can be
synchronised
effectively
Preparing the
database in
Excel
Simple
calculations
Customer
records of
the small
organization
Large Data Available in
Giga bytes
and terabytes
Millions of
tuples
organized in
proper
structured
format
Use of
relational
database
Data mining
and data
warehousing
techniques
Customer
records of
the big
organization
Big Data Terabytes
and
Petabytes
Billion and
Trillions of
tuples
organized in
proper
structured
format
Cloud
computing
technologies
Hadoop file
system
NoSQL
database
Distributed
file structure
system
Map Reduce
Technologies
E-commerce
trading
Social
Networking
website
Internet of
things
applications
The large volume of big data requires special platform for managing the data effectively in
the simplified format so as to increase the level of data availability and reliability. The
purpose of this research program is to analyse the complexities and impact of big data on the
application and propose an effective data management model for overcoming the problems
related to the big data structured format. The proposed data model helps in increasing the
storage capability of the data format. The designing of the big data architecture depends on
the technologies used in developing the infrastructure. The focus should be given on
managing the interaction between the components. The structured format should be
developed for managing the data sources such as social media, IOT applications, and others.
The streaming process should be done for managing the information related to the sensor
data. The ingestion of the information should be carried out in real time format by including
the map reduce technique so as to minimize the presence of replicated data at different data
server. The assimilation of the data is optimized in developing heterogeneous format. The
5
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

Big Data Modelling
operational efficiency of the big data architecture can be accelerated by developing the
master data management plan. The real time analysis of the data helps in getting the updated
version of the information. The functional and operational view of the data can be increased
by emerging the landing repositories of the information. The exploration of the data is formed
by organizing the data sets and blocks of information for getting the required information
with minimum period of time. The security and confidentiality of the information are two
major issues related to the data privacy of the heterogeneous data. The big data models results
in increasing the key performance indicators of the developed application. The hierarchical
taxonomy is prepared for developing the structured ontological structured format. The
synchronization of different and hybrid technologies together in a single format help in
developing the effective design model to get required information. The atomicity of the
information can be achieved by implementing the normalization techniques. The data models
designs are influenced by the schema formation and integration of different components. The
Hadoop model is used for storing the sensor data of the IOT application at distributed servers.
The correlation between the components helps in minimizing the latency time for retrieving
the updated information. The aggregation of the information helps in managing the
governance of the data. The database schema should be designed for forming the
visualization of data at distributed server. The information is stored systematically in
RDBMS for implementing the business intelligence operations on the working model of the
warehouse. The interaction between the components helps in preserving the well-structured
format to manage the internal sources data by streamlining the sensor data and devices. The
information is assimilated from various sources to give the real time situation and availability
of the data in the warehouse. The information can be timely retrieve through the streaming
process and inclusion of map reduce technology. The operational efficiency of the big data
can be improved by developing the master data management system. It focuses on managing
the operational data stores for improving the power of computation and procedure. The big
data architecture is developed for synchronizing the data patterns according to the data
collected from real time sensor devices. The information is stored in repositories of large
chunks of memory for systematic approach of real time data from the heterogeneous sources.
The activities are systematically sequenced for exposure of supporting functions and
operational working process. The data is governed by exploration of security architecture and
metadata formation. The advanced technology is defined for developing the structured
architecture of the data sets. The conceptual model should be developed by following the
semantics and symbols of data to prepare the data nodes. The consistency of the data items
6
operational efficiency of the big data architecture can be accelerated by developing the
master data management plan. The real time analysis of the data helps in getting the updated
version of the information. The functional and operational view of the data can be increased
by emerging the landing repositories of the information. The exploration of the data is formed
by organizing the data sets and blocks of information for getting the required information
with minimum period of time. The security and confidentiality of the information are two
major issues related to the data privacy of the heterogeneous data. The big data models results
in increasing the key performance indicators of the developed application. The hierarchical
taxonomy is prepared for developing the structured ontological structured format. The
synchronization of different and hybrid technologies together in a single format help in
developing the effective design model to get required information. The atomicity of the
information can be achieved by implementing the normalization techniques. The data models
designs are influenced by the schema formation and integration of different components. The
Hadoop model is used for storing the sensor data of the IOT application at distributed servers.
The correlation between the components helps in minimizing the latency time for retrieving
the updated information. The aggregation of the information helps in managing the
governance of the data. The database schema should be designed for forming the
visualization of data at distributed server. The information is stored systematically in
RDBMS for implementing the business intelligence operations on the working model of the
warehouse. The interaction between the components helps in preserving the well-structured
format to manage the internal sources data by streamlining the sensor data and devices. The
information is assimilated from various sources to give the real time situation and availability
of the data in the warehouse. The information can be timely retrieve through the streaming
process and inclusion of map reduce technology. The operational efficiency of the big data
can be improved by developing the master data management system. It focuses on managing
the operational data stores for improving the power of computation and procedure. The big
data architecture is developed for synchronizing the data patterns according to the data
collected from real time sensor devices. The information is stored in repositories of large
chunks of memory for systematic approach of real time data from the heterogeneous sources.
The activities are systematically sequenced for exposure of supporting functions and
operational working process. The data is governed by exploration of security architecture and
metadata formation. The advanced technology is defined for developing the structured
architecture of the data sets. The conceptual model should be developed by following the
semantics and symbols of data to prepare the data nodes. The consistency of the data items
6
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Big Data Modelling
should be defined for managing the interaction between the data components. The complexity
of the data is majorly defines according to the availability of the storage units and database.
The pre-processing of the applications helps in developing responses within the minimum
period of query generated by the users to extract the standard information. The integrated sets
of information are managed for accessing the information from multiple heterogeneous data
components. The underpinning of the data governance model helps in developing the
effective data management model. The integrated sets of data are arranged for developing the
data models. The physical models are developed for shaping physical and structured storage
of data items.
The schema of the data structure depends upon the physical arrangement of the database to
manage the flow of information. The SQL language is used for defining the physical
boundaries of the data for storing it in the Hadoop architectural platform. The expectancy of
the user access helps in developing the physical model to represent the concurrency control
on the data retrieval process. The data latency period is calculated for developing the real
time management of data in the warehouse. The latency period is influenced by the de-
normalization and batch processing unit. The correlation between the data items helps in
improving the performance of the processes synchronized into the query queue. The
cleansing operations is performed for calculating the aggregated function to transform the
data into redundant information at different server. The server is authorised for retrieving the
information from the data server where replicated information is stored. The mapping of the
processes should be done for focusing on the dependency between the tables and column data
through the application of the associative rule. The critical condition of the data availability
can be measured by calculating the threshold value of the system. The strong relationship
should be developed between the flow of data packets from sender to the destination. The
central control and authorisation of the business process helps in resolving the artefacts of
figures and semantics. The access control policies are developed for giving the structural
view of the Hadoop database. The consideration should be given on managing the atomicity
of data retrieval process. The unstructured view defines the weak schema and structured view
defines the strong schema for developing the paternal architectural format to resolve the
relevancy between the heterogeneous data sources. The modelling techniques are applied for
taking effective decision to extract the transactional information. The correlation between the
mobile traffic and network congestion helps in accelerating the transmission speed of the data
items. The business intelligence functions are implemented to synchronise the aggregation of
7
should be defined for managing the interaction between the data components. The complexity
of the data is majorly defines according to the availability of the storage units and database.
The pre-processing of the applications helps in developing responses within the minimum
period of query generated by the users to extract the standard information. The integrated sets
of information are managed for accessing the information from multiple heterogeneous data
components. The underpinning of the data governance model helps in developing the
effective data management model. The integrated sets of data are arranged for developing the
data models. The physical models are developed for shaping physical and structured storage
of data items.
The schema of the data structure depends upon the physical arrangement of the database to
manage the flow of information. The SQL language is used for defining the physical
boundaries of the data for storing it in the Hadoop architectural platform. The expectancy of
the user access helps in developing the physical model to represent the concurrency control
on the data retrieval process. The data latency period is calculated for developing the real
time management of data in the warehouse. The latency period is influenced by the de-
normalization and batch processing unit. The correlation between the data items helps in
improving the performance of the processes synchronized into the query queue. The
cleansing operations is performed for calculating the aggregated function to transform the
data into redundant information at different server. The server is authorised for retrieving the
information from the data server where replicated information is stored. The mapping of the
processes should be done for focusing on the dependency between the tables and column data
through the application of the associative rule. The critical condition of the data availability
can be measured by calculating the threshold value of the system. The strong relationship
should be developed between the flow of data packets from sender to the destination. The
central control and authorisation of the business process helps in resolving the artefacts of
figures and semantics. The access control policies are developed for giving the structural
view of the Hadoop database. The consideration should be given on managing the atomicity
of data retrieval process. The unstructured view defines the weak schema and structured view
defines the strong schema for developing the paternal architectural format to resolve the
relevancy between the heterogeneous data sources. The modelling techniques are applied for
taking effective decision to extract the transactional information. The correlation between the
mobile traffic and network congestion helps in accelerating the transmission speed of the data
items. The business intelligence functions are implemented to synchronise the aggregation of
7

Big Data Modelling
the data marts function to defines the use cases. The scaling approach helps in balancing the
level of petabytes of information in sequential approach. The audit control program is
developed for retrieving the information from the historical data managed in hierarchical tree
structure format. The exploration of data is done through the audit control program for
applying the regulatory operations on the data sets. The decision tree is developed for
exploring the requirement and retaining the value of the business processes. The schema
definition helps in retrieving the information from multiple sources to manage the external
control on the data units. The read and write operations are performed by applying the
procedures of late binding program to improve the mapping of the data from various
operational stores of information. The repositories of data are developed to fulfil the access
control need of data. The logical infrastructure of the Hadoop file system is developed by
combining the downstream of data to achieve the accuracy and trust of information. The
schema designs should be developed for managing the operational view of the business
processes. The latency period for obtaining the response of the query can be minimized to
improves the consistency of the data units. The data processing unit helps in resolving the
governance of the functional unit of conceptual model. The text analytical approach should
be designed for fulfilling the data demand of the user and helps in accelerating the data
retrieval process. The auditing program should be defined for identifying the metadata and
extracting information from the transcript data processes. The information is organized in the
hierarchical tree structure format. The data is adjusted and transformed into specific and
relevant information by performing the cleansing operations. The underpinning of the
information helps in resolving the consistency of the data items arranged in the tabular
format. The repositories of the data sets are stored in the form of graphs and pictorial
representation of the information. The remote sensing parameters are used for developing the
networks to arrange the information in static grid format. The data is stored in the image
format to organize sequence of information in mapping the invalid data. The sorting of the
assorted data helps in increasing th operational skills of the database management program.
The large volume of data are divided into smaller valuable chunks of information through the
program of descriptive analytical approach. The assorted data is sequenced through the
measurable value of data mining operations and performing mining operations through the
strategic approach of forecasting relevant information. The verified information helps in
forecasting the strategies of displaying the data in sequential format. The decision making
capability can be improved the quality of data. The pattern matching of the information
increases the fault tolerance capability of the server to manage the data in effective format.
8
the data marts function to defines the use cases. The scaling approach helps in balancing the
level of petabytes of information in sequential approach. The audit control program is
developed for retrieving the information from the historical data managed in hierarchical tree
structure format. The exploration of data is done through the audit control program for
applying the regulatory operations on the data sets. The decision tree is developed for
exploring the requirement and retaining the value of the business processes. The schema
definition helps in retrieving the information from multiple sources to manage the external
control on the data units. The read and write operations are performed by applying the
procedures of late binding program to improve the mapping of the data from various
operational stores of information. The repositories of data are developed to fulfil the access
control need of data. The logical infrastructure of the Hadoop file system is developed by
combining the downstream of data to achieve the accuracy and trust of information. The
schema designs should be developed for managing the operational view of the business
processes. The latency period for obtaining the response of the query can be minimized to
improves the consistency of the data units. The data processing unit helps in resolving the
governance of the functional unit of conceptual model. The text analytical approach should
be designed for fulfilling the data demand of the user and helps in accelerating the data
retrieval process. The auditing program should be defined for identifying the metadata and
extracting information from the transcript data processes. The information is organized in the
hierarchical tree structure format. The data is adjusted and transformed into specific and
relevant information by performing the cleansing operations. The underpinning of the
information helps in resolving the consistency of the data items arranged in the tabular
format. The repositories of the data sets are stored in the form of graphs and pictorial
representation of the information. The remote sensing parameters are used for developing the
networks to arrange the information in static grid format. The data is stored in the image
format to organize sequence of information in mapping the invalid data. The sorting of the
assorted data helps in increasing th operational skills of the database management program.
The large volume of data are divided into smaller valuable chunks of information through the
program of descriptive analytical approach. The assorted data is sequenced through the
measurable value of data mining operations and performing mining operations through the
strategic approach of forecasting relevant information. The verified information helps in
forecasting the strategies of displaying the data in sequential format. The decision making
capability can be improved the quality of data. The pattern matching of the information
increases the fault tolerance capability of the server to manage the data in effective format.
8
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

Big Data Modelling
The large volume of data helps in increasing the visualization of information to fill the gaps
of potential retrieval of information. The privilege should be given to the privacy issues of the
information for demonstrating the big data management system. The topology is defined used
for increasing the accessibility of operational data from the large volume of information. The
Google file system is maintained for developing the large data models on the network. The
speculation of the vulnerabilities associated with the data management system should be
foreseen for improving the data consistency and accuracy of the information. The expansion
of the information helps in accelerating the data retrieval process. The scalability of the data
server can be improved by developing the open source code of information. The
diversification of the data domain increases the solitary association of the data items to run
the program on different platforms. The clustering of the data can be systematically done
through the development of the Hadoop file system. The processing of the information can be
improved by associating the parallel computation system. The record keeping architecture is
developed by initiating the parallel processing unit in cluster and batch system. The Hadoop
architecture is developed by combining the operational efficiency of the distributed file
system and map reduce execution engine. The master slave architecture of the information is
developed for formulating the structural view of information. The flexibility of the database
architecture can be processed by implementing the read and write operations on the data
model. The name node are organised for processing the map reduce function on the data
blocks arranged in sequential format of information. The mapping of the information is done
by arranging the assorted data in sequential and sorted order.
Research Aim
The aim of the research is to analyse the problems related to the management plan of big data
available due to excessive use of social networking platform and IOT applications. In this
paper, we are going to present the data modelling techniques which systematically arrange
the big data in service and infrastructure formats. The focus should be given on overcoming
the inefficiency of the traditional data model by proposing an effective data model for
managing the big data.
Research Problem
The UML technology is basically used in traditional data models for systematically
synchronising the data in structured format. It is difficult to handle the exponential growth of
increasing data from various sectors such as health care centres, business organization,
artificial intelligence, IOT infrastructure, and others. The upcoming model should provide the
9
The large volume of data helps in increasing the visualization of information to fill the gaps
of potential retrieval of information. The privilege should be given to the privacy issues of the
information for demonstrating the big data management system. The topology is defined used
for increasing the accessibility of operational data from the large volume of information. The
Google file system is maintained for developing the large data models on the network. The
speculation of the vulnerabilities associated with the data management system should be
foreseen for improving the data consistency and accuracy of the information. The expansion
of the information helps in accelerating the data retrieval process. The scalability of the data
server can be improved by developing the open source code of information. The
diversification of the data domain increases the solitary association of the data items to run
the program on different platforms. The clustering of the data can be systematically done
through the development of the Hadoop file system. The processing of the information can be
improved by associating the parallel computation system. The record keeping architecture is
developed by initiating the parallel processing unit in cluster and batch system. The Hadoop
architecture is developed by combining the operational efficiency of the distributed file
system and map reduce execution engine. The master slave architecture of the information is
developed for formulating the structural view of information. The flexibility of the database
architecture can be processed by implementing the read and write operations on the data
model. The name node are organised for processing the map reduce function on the data
blocks arranged in sequential format of information. The mapping of the information is done
by arranging the assorted data in sequential and sorted order.
Research Aim
The aim of the research is to analyse the problems related to the management plan of big data
available due to excessive use of social networking platform and IOT applications. In this
paper, we are going to present the data modelling techniques which systematically arrange
the big data in service and infrastructure formats. The focus should be given on overcoming
the inefficiency of the traditional data model by proposing an effective data model for
managing the big data.
Research Problem
The UML technology is basically used in traditional data models for systematically
synchronising the data in structured format. It is difficult to handle the exponential growth of
increasing data from various sectors such as health care centres, business organization,
artificial intelligence, IOT infrastructure, and others. The upcoming model should provide the
9
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Big Data Modelling
elasticity for managing the interfaces between the open data. The invention of NoSQL
databases helps in arranging the data without a relational schema. The security is the major
problems related to big data management system which has to be resolved with the proposed
data model. The available data models are not effective in managing the realm of big data.
The stability of the data depends on the organization of the big data in the systematic format.
The functional approach is used for operating on the big data for easy handling and retrieval
of the data according to the demand raised by the operator. The data should be physically
stored in the structured, unstructured, and semi-structured format. The Software as a service
model, NoSQL database, Mat lab, and Map reduce technology are used for handling big data
in structured format but the limitation of these models is that they generate lots of
intermediate data. The storage and management issues are the major problems related to the
big data. The data qualification, quantization, and validation are processes used for increasing
the accessibility of the data in the specified manner.
Research Questions
1. What is big data modelling? What are the challenges faced in the application of big
data modelling techniques?
2. What are the applications of big data modelling?
3. What progress and recent trends seen in big data modelling?
4. How big data modelling is useful for managing the voluminous data of cloud
computing and IOT architecture?
Thesis Scope
The research study helps in analysing the problems related to the storage and management of
the big data. The systematic arrangement of database is required for storing and managing the
data in the classified format so as to increase the availability of accurate data in the minimal
amount of time. The effective and efficient data model is required for managing the balance
between the request and response model and increases the efficiency of arranging petabytes
of data. The proposed data model should be capable of handling voluminous data in a
systematic format for securing the information confidentiality, reliability, and accuracy. The
consideration should be given on the diversification of the data available from different
sources such as social networking platform, IOT architecture, and artificial intelligence. The
significance of the research study is to come up with the big data model for easy storage and
secured management of data available in large volume.
10
elasticity for managing the interfaces between the open data. The invention of NoSQL
databases helps in arranging the data without a relational schema. The security is the major
problems related to big data management system which has to be resolved with the proposed
data model. The available data models are not effective in managing the realm of big data.
The stability of the data depends on the organization of the big data in the systematic format.
The functional approach is used for operating on the big data for easy handling and retrieval
of the data according to the demand raised by the operator. The data should be physically
stored in the structured, unstructured, and semi-structured format. The Software as a service
model, NoSQL database, Mat lab, and Map reduce technology are used for handling big data
in structured format but the limitation of these models is that they generate lots of
intermediate data. The storage and management issues are the major problems related to the
big data. The data qualification, quantization, and validation are processes used for increasing
the accessibility of the data in the specified manner.
Research Questions
1. What is big data modelling? What are the challenges faced in the application of big
data modelling techniques?
2. What are the applications of big data modelling?
3. What progress and recent trends seen in big data modelling?
4. How big data modelling is useful for managing the voluminous data of cloud
computing and IOT architecture?
Thesis Scope
The research study helps in analysing the problems related to the storage and management of
the big data. The systematic arrangement of database is required for storing and managing the
data in the classified format so as to increase the availability of accurate data in the minimal
amount of time. The effective and efficient data model is required for managing the balance
between the request and response model and increases the efficiency of arranging petabytes
of data. The proposed data model should be capable of handling voluminous data in a
systematic format for securing the information confidentiality, reliability, and accuracy. The
consideration should be given on the diversification of the data available from different
sources such as social networking platform, IOT architecture, and artificial intelligence. The
significance of the research study is to come up with the big data model for easy storage and
secured management of data available in large volume.
10

Big Data Modelling
Thesis Contribution
The research helps in finding out the challenges and issues which come forward in the path of
applying big data modelling techniques for managing the large amount of data generated
from social media platform and IOT infrastructure. The focus should be given on the
application and technology required for keeping track of big data. The identification of recent
trends and progress opens new door for the research to find out the solution and technologies
which are capable for balancing the challenges and issues of big data. The research is taken
out in the direction to develop a model for managing big data which is useful for managing
the voluminous data of cloud computing and IOT architecture. In this paper, we are going to
propose and design the big data modelling technique for managing the stock inventory
system by sending the alarm and message on the mobile phone of the owner about underflow
and overflow condition of the stock available in the organization.
Thesis Outline
The research program is divided into segments so that the facts and figures can be collected
to analyse the big data modelling process. The first chapter focuses on the identifying the
requirement and importance of big data modelling for handling the voluminous data of
various application. The second chapter gives the details of literature and research carried out
in the field of big data modelling. The third chapter presents the challenges faced in the
application of big data modelling techniques. The fourth chapter focuses on the applications
and technologies used in big data modelling. The fifth chapter contributes in the direction of
highlighting progress and recent trends seen in big data modelling. The sixth chapter finds
out the architecture and framework of big data model which is useful for managing the
voluminous data of cloud computing and IOT architecture. The seventh chapter presents the
implementation of big data modelling in real life example. The research program ends with
the conclusion and the future scope of the thesis.
11
Thesis Contribution
The research helps in finding out the challenges and issues which come forward in the path of
applying big data modelling techniques for managing the large amount of data generated
from social media platform and IOT infrastructure. The focus should be given on the
application and technology required for keeping track of big data. The identification of recent
trends and progress opens new door for the research to find out the solution and technologies
which are capable for balancing the challenges and issues of big data. The research is taken
out in the direction to develop a model for managing big data which is useful for managing
the voluminous data of cloud computing and IOT architecture. In this paper, we are going to
propose and design the big data modelling technique for managing the stock inventory
system by sending the alarm and message on the mobile phone of the owner about underflow
and overflow condition of the stock available in the organization.
Thesis Outline
The research program is divided into segments so that the facts and figures can be collected
to analyse the big data modelling process. The first chapter focuses on the identifying the
requirement and importance of big data modelling for handling the voluminous data of
various application. The second chapter gives the details of literature and research carried out
in the field of big data modelling. The third chapter presents the challenges faced in the
application of big data modelling techniques. The fourth chapter focuses on the applications
and technologies used in big data modelling. The fifth chapter contributes in the direction of
highlighting progress and recent trends seen in big data modelling. The sixth chapter finds
out the architecture and framework of big data model which is useful for managing the
voluminous data of cloud computing and IOT architecture. The seventh chapter presents the
implementation of big data modelling in real life example. The research program ends with
the conclusion and the future scope of the thesis.
11
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 137
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.