CSE3BDC Assignment: Cloudera, Hive, Impala, and Data Processing
VerifiedAdded on 2022/11/13
|25
|2909
|245
Practical Assignment
AI Summary
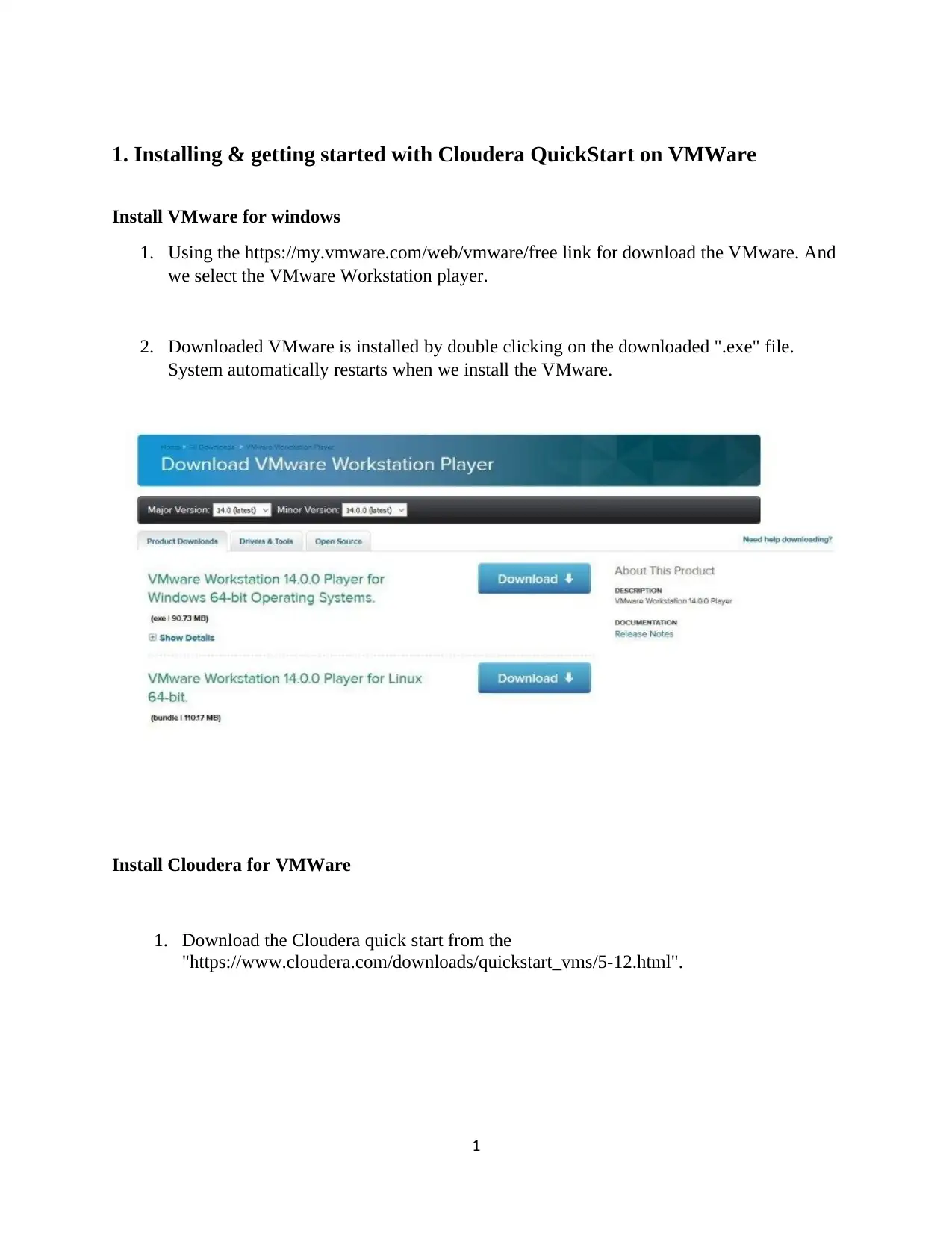
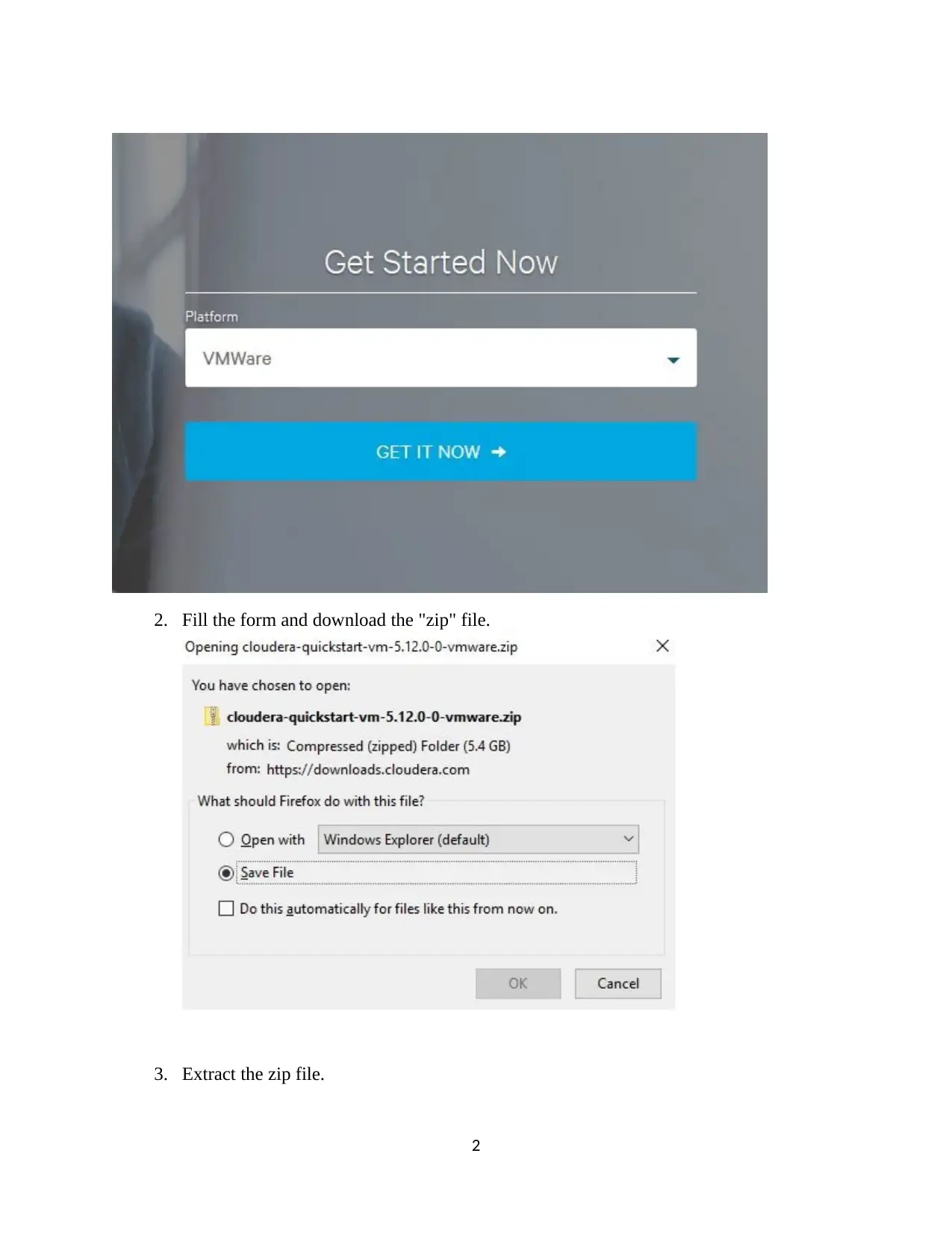
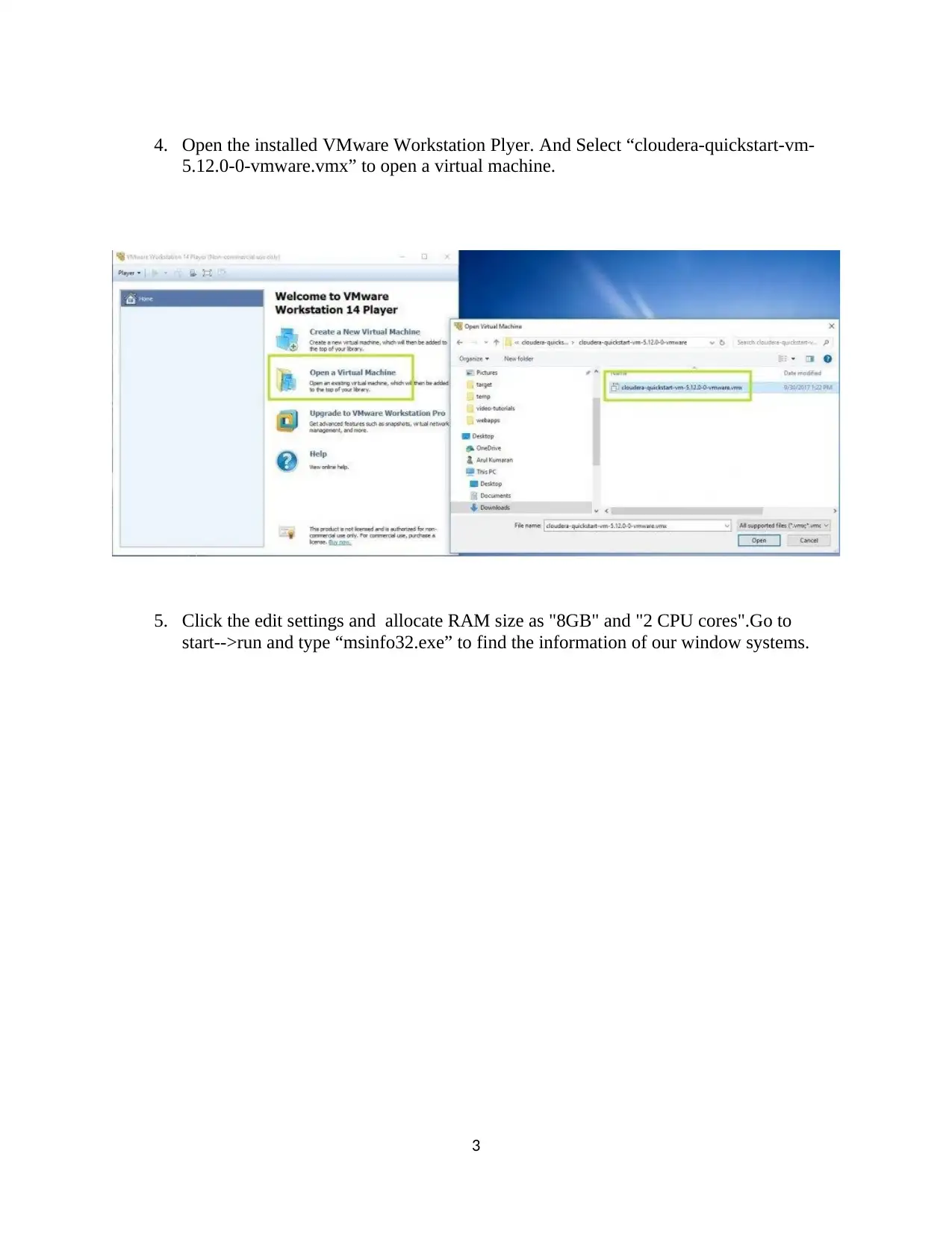
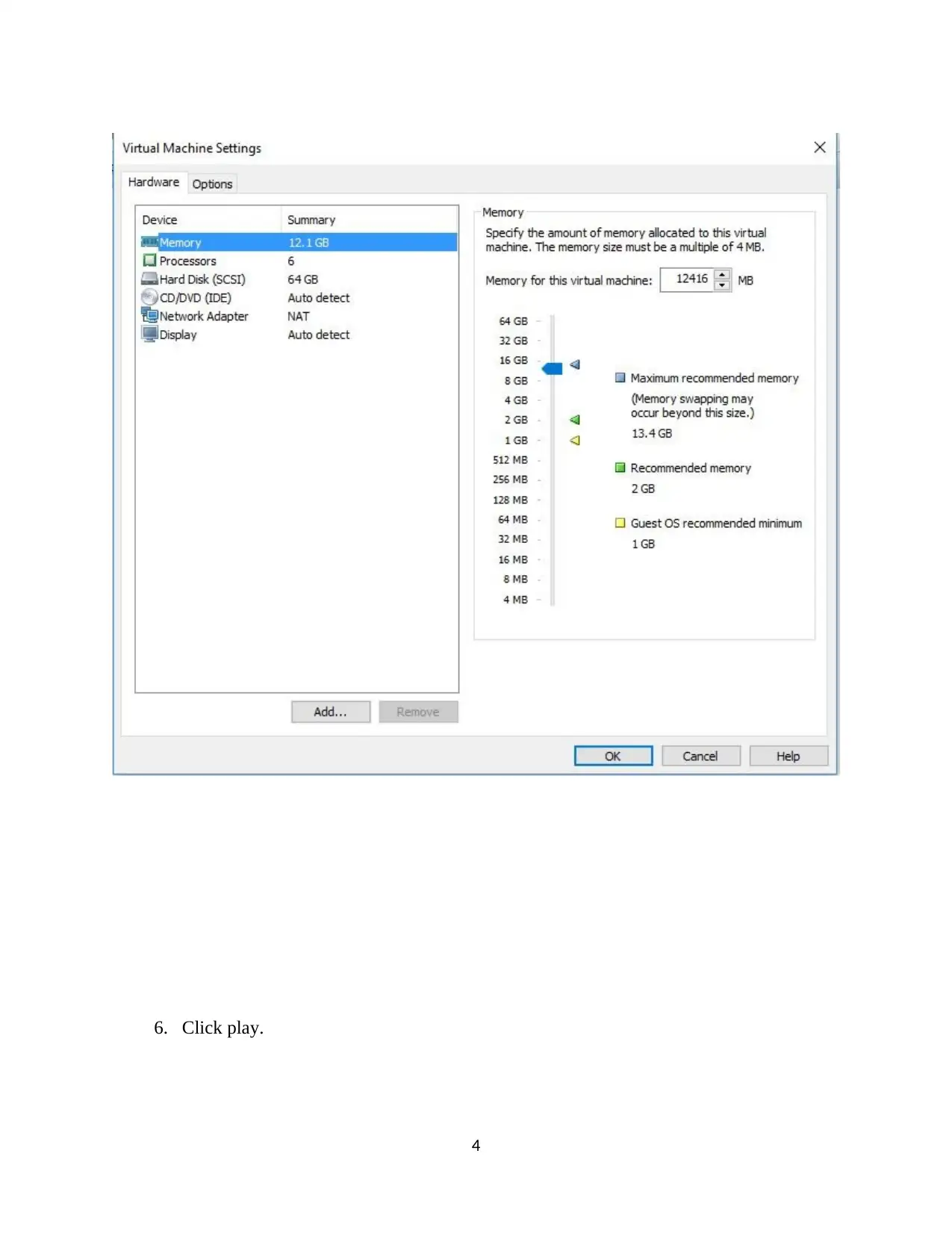
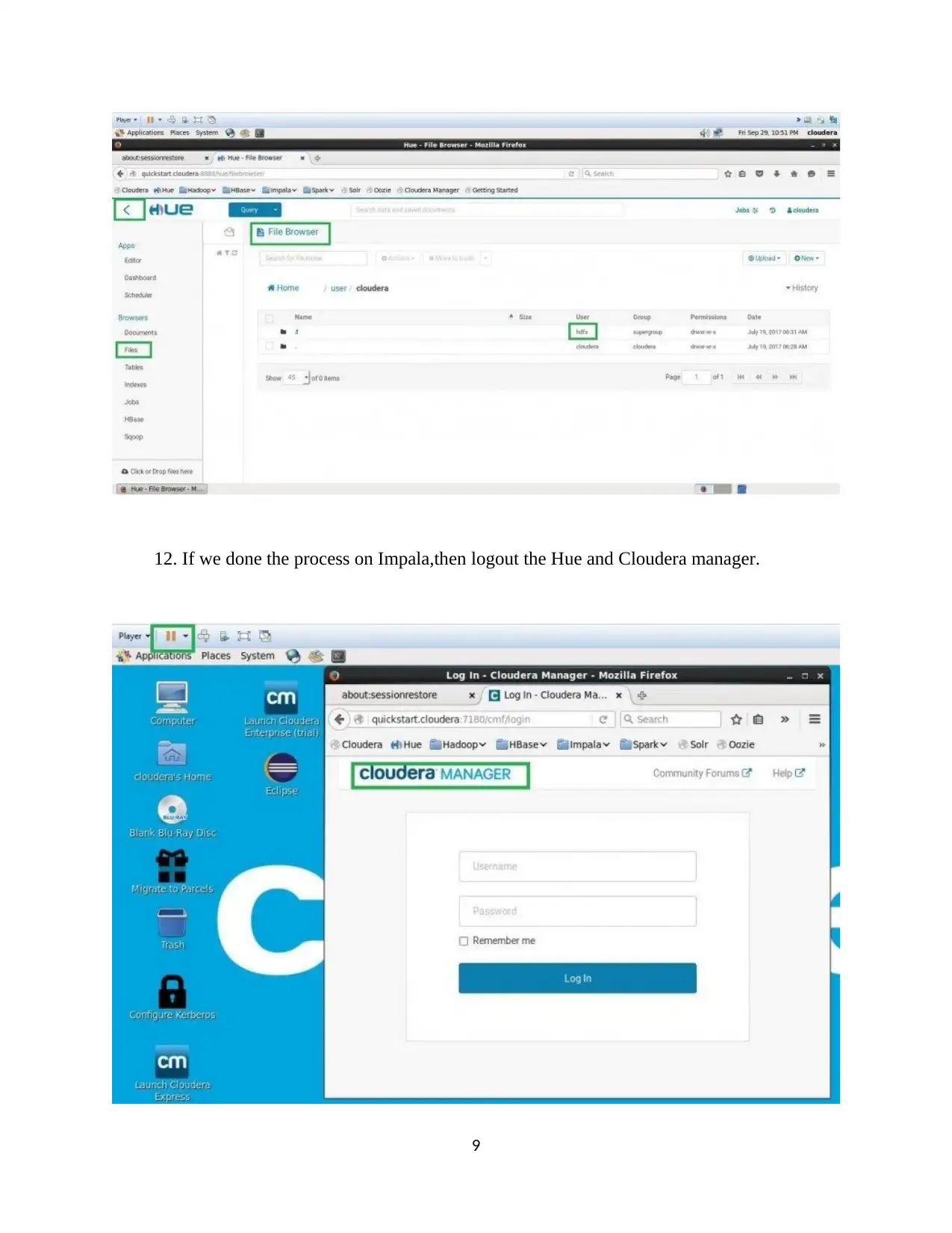
This assignment provides a comprehensive guide to installing and utilizing Cloudera QuickStart on VMware, followed by detailed instructions on processing data using Impala and Hive. The process includes downloading and setting up Cloudera, configuring VMware, and launching the Cloudera Manager. The assignment then dives into Impala, demonstrating how to analyze an instance, browse and load HDFS data, mark Impala tables, specify tables, and execute queries. The document provides code snippets for common Impala operations, including inserting, selecting, and aggregating data. Furthermore, it covers the creation of databases and tables in Hive, along with the loading of CSV data and querying using HiveQL. The document also includes a section on data loading and querying, including examples of inserting data, examining table contents, and performing aggregate and join operations. Finally, the assignment concludes with references to relevant research papers and resources for further study.



1 out of 25


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.