COIT20253 - Big Data Analysis Report: Healthcare Data Management
VerifiedAdded on 2023/03/17
|20
|4463
|58
Report
AI Summary
This report provides a comprehensive analysis of big data technologies and their application in healthcare data management. It begins with an executive summary and an introduction to big data, characterizing it by volume, velocity, and variety. The report then presents a use case of big data in healthcare and critically analyzes various big data technologies, including Hadoop, Spark, Data Lakes, and R technology. It explores the advantages and disadvantages of each technology. Furthermore, the report proposes a big data architecture solution tailored for healthcare data management. The report details the technology stack and processing architecture needed to support specific use cases, including the user experiences designed to aid decision-making. The report concludes with a summary of findings and recommendations for implementing big data solutions within healthcare organizations. The assignment is based on the previous assessment and the student is required to produce a report based on the Big Data strategy document developed for Assessment 2. The target audience is executive.

Running head: BIG DATA ANALYSIS
Big Data Analysis
Name of the Student
Name of the University
Author Note
Big Data Analysis
Name of the Student
Name of the University
Author Note
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

1BIG DATA ANALYSIS
Executive summary
This report aims to provide the discussion of the big data technologies and then provide the
appropriate architecture solution for the management of health data records. The brief use cases
are provided for illustrating the users of the big data in healthcare. The discussion of big data
technologies has been provided for determining the advantages and the disadvantages that are
provided by the big data technologies. The big data architecture solution has been recommended
for the healthcare data management that could be implemented by the healthcare organizations.
The characterization of the big data is done dividing it into three categories which are velocity of
the data processing, varieties of data and extreme volume of data. Many others also treat the big
data as some typical way of analyzing and systematic extraction of some particular information
or it can be considered as some unique way of dealing with some large number of datasets. Here
this large amount of data is handled with by some traditional type of data processing software.
Lastly this report concludes with the appropriate conclusion for the report.
Executive summary
This report aims to provide the discussion of the big data technologies and then provide the
appropriate architecture solution for the management of health data records. The brief use cases
are provided for illustrating the users of the big data in healthcare. The discussion of big data
technologies has been provided for determining the advantages and the disadvantages that are
provided by the big data technologies. The big data architecture solution has been recommended
for the healthcare data management that could be implemented by the healthcare organizations.
The characterization of the big data is done dividing it into three categories which are velocity of
the data processing, varieties of data and extreme volume of data. Many others also treat the big
data as some typical way of analyzing and systematic extraction of some particular information
or it can be considered as some unique way of dealing with some large number of datasets. Here
this large amount of data is handled with by some traditional type of data processing software.
Lastly this report concludes with the appropriate conclusion for the report.

2BIG DATA ANALYSIS
Table of Contents
Introduction:....................................................................................................................................3
Big data use case..............................................................................................................................4
Critical Analysis of Big Data Technology:.....................................................................................4
Different types of Big Data Technology:....................................................................................4
Hadoop.....................................................................................................................................4
Spark........................................................................................................................................7
Data Lakes.............................................................................................................................10
R technology..........................................................................................................................11
Big data architecture solution........................................................................................................13
Conclusion.....................................................................................................................................14
References......................................................................................................................................16
Table of Contents
Introduction:....................................................................................................................................3
Big data use case..............................................................................................................................4
Critical Analysis of Big Data Technology:.....................................................................................4
Different types of Big Data Technology:....................................................................................4
Hadoop.....................................................................................................................................4
Spark........................................................................................................................................7
Data Lakes.............................................................................................................................10
R technology..........................................................................................................................11
Big data architecture solution........................................................................................................13
Conclusion.....................................................................................................................................14
References......................................................................................................................................16
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

3BIG DATA ANALYSIS
Introduction:
The term “Big Data” is actually describes that is some large set or volume of data which
can be in form of unstructured, semi-structured and structured data. Big data mainly mines some
of the important information which are mainly utilized for some advanced projects or can be
used for some analytics operations. The characterization of the big data is done dividing it into
three categories which are velocity of the data processing, varieties of data and extreme volume
of data. Many others also treat the big data as some typical way of analyzing and systematic
extraction of some particular information or it can be considered as some unique way of dealing
with some large number of datasets. Here this large amount of data is handled with by some
traditional type of data processing software. The concept of big data is quite important as it
provides some great advantages to the statistical type of power, but in this case another
disadvantage is that data with some high complexity can lead to higher rate of false discovery.
As the big data technology is having both the positive and negative aspects regarding the
processing of the data an extended study will be done regarding the Big Data Technology. Here a
critical analysis of the big data technology will be done and some solution regarding the
architecture of the big data will be discussed.
Introduction:
The term “Big Data” is actually describes that is some large set or volume of data which
can be in form of unstructured, semi-structured and structured data. Big data mainly mines some
of the important information which are mainly utilized for some advanced projects or can be
used for some analytics operations. The characterization of the big data is done dividing it into
three categories which are velocity of the data processing, varieties of data and extreme volume
of data. Many others also treat the big data as some typical way of analyzing and systematic
extraction of some particular information or it can be considered as some unique way of dealing
with some large number of datasets. Here this large amount of data is handled with by some
traditional type of data processing software. The concept of big data is quite important as it
provides some great advantages to the statistical type of power, but in this case another
disadvantage is that data with some high complexity can lead to higher rate of false discovery.
As the big data technology is having both the positive and negative aspects regarding the
processing of the data an extended study will be done regarding the Big Data Technology. Here a
critical analysis of the big data technology will be done and some solution regarding the
architecture of the big data will be discussed.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
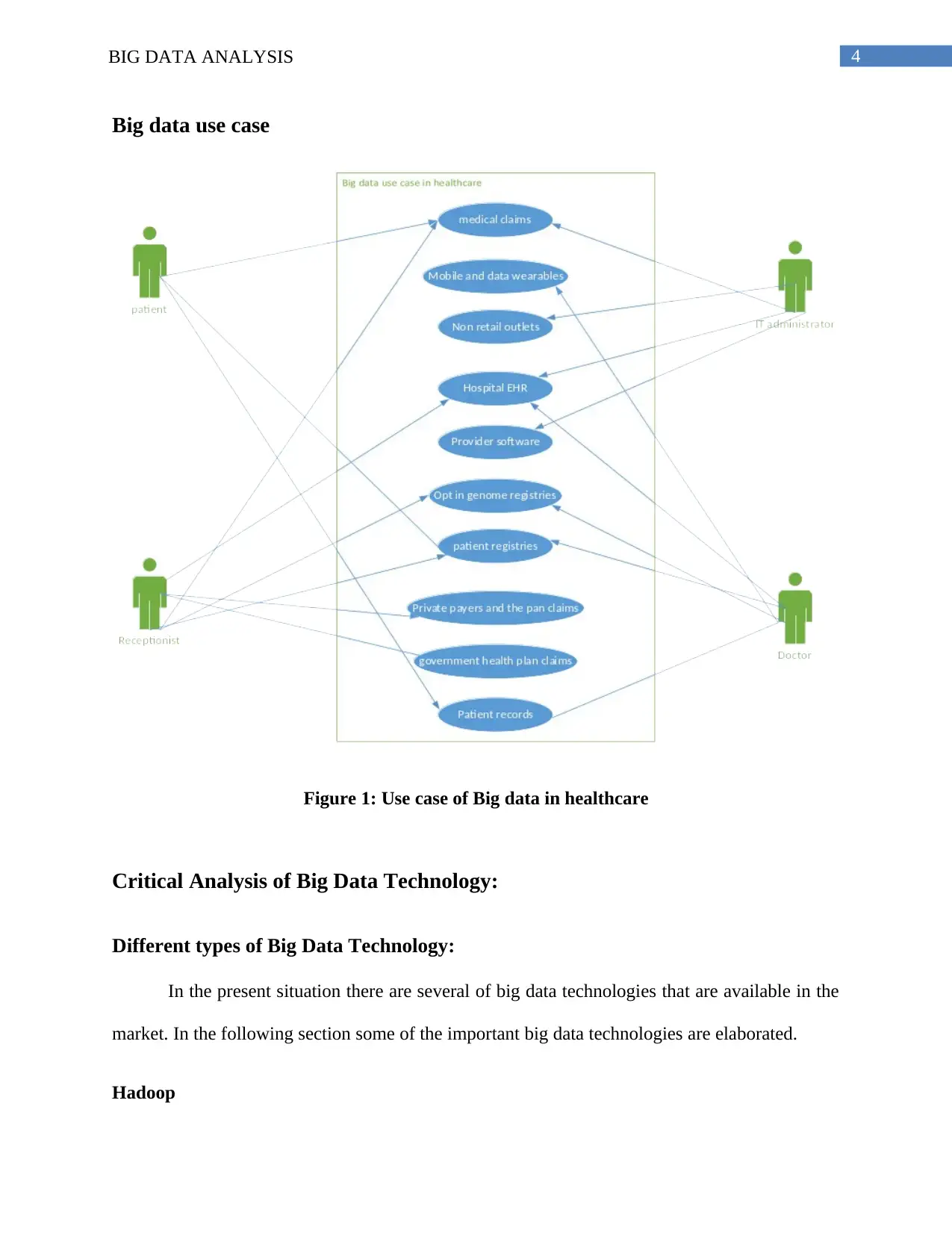
4BIG DATA ANALYSIS
Big data use case
Figure 1: Use case of Big data in healthcare
Critical Analysis of Big Data Technology:
Different types of Big Data Technology:
In the present situation there are several of big data technologies that are available in the
market. In the following section some of the important big data technologies are elaborated.
Hadoop
Big data use case
Figure 1: Use case of Big data in healthcare
Critical Analysis of Big Data Technology:
Different types of Big Data Technology:
In the present situation there are several of big data technologies that are available in the
market. In the following section some of the important big data technologies are elaborated.
Hadoop

5BIG DATA ANALYSIS
Hadoop is commonly referred as the open source software framework that is used for storing any
data and then executing the application on the clusters of commodity hardware (Chen and Zhang
2014). It offers the vast storage for all kind of data, huge processing power along with the ability
of handling the virtually limitless concurrent jobs or the tasks. The ecosystem of the Hadoop is
might not be dominant like the other Big Data technologies but this technology is one of the
most important open source framework for perfect distributed processing of some large sets of
data. Hadoop has also developed itself so that it becomes capable of working as commercial type
of big data solutions which are currently depending on the Hadoop related big data solution
(Gandomi and Haider 2015). The important vendors for the Hadoop ecosystem are the
Hortonworks, Cloudera and MapR. Some of the important public cloud system is also providing
this Hadoop technology. Some of the benefits of Hadoop technology are:
The benefits of using Hadoop could be significant as it provides the ability of storing
and processing vast amount of any type of data easily, immense computing power,
quick fault tolerance, flexibility, low cost, and scalability (Oussous et al. 2018). With
the huge data volumes along with the varieties that are consistently increasing,
specifically from the social media and the Internet of Things, it is required to have the
significant processing power and computing capability.
The data of the healthcare are required to be analyzed in the real time and provide
quick results for synthesis that could help the doctors and the management to take
quick, informed decisions (Khan et al. 2014). The distributed computing power of
Hadoop helps in processing the big data quickly and the easily.
The more computing nodes that are used, the more processing power the organization
could have. The processing of the data and the application are significantly protected
Hadoop is commonly referred as the open source software framework that is used for storing any
data and then executing the application on the clusters of commodity hardware (Chen and Zhang
2014). It offers the vast storage for all kind of data, huge processing power along with the ability
of handling the virtually limitless concurrent jobs or the tasks. The ecosystem of the Hadoop is
might not be dominant like the other Big Data technologies but this technology is one of the
most important open source framework for perfect distributed processing of some large sets of
data. Hadoop has also developed itself so that it becomes capable of working as commercial type
of big data solutions which are currently depending on the Hadoop related big data solution
(Gandomi and Haider 2015). The important vendors for the Hadoop ecosystem are the
Hortonworks, Cloudera and MapR. Some of the important public cloud system is also providing
this Hadoop technology. Some of the benefits of Hadoop technology are:
The benefits of using Hadoop could be significant as it provides the ability of storing
and processing vast amount of any type of data easily, immense computing power,
quick fault tolerance, flexibility, low cost, and scalability (Oussous et al. 2018). With
the huge data volumes along with the varieties that are consistently increasing,
specifically from the social media and the Internet of Things, it is required to have the
significant processing power and computing capability.
The data of the healthcare are required to be analyzed in the real time and provide
quick results for synthesis that could help the doctors and the management to take
quick, informed decisions (Khan et al. 2014). The distributed computing power of
Hadoop helps in processing the big data quickly and the easily.
The more computing nodes that are used, the more processing power the organization
could have. The processing of the data and the application are significantly protected
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

6BIG DATA ANALYSIS
against the hardware failure. In the situation when any of the node is not working
properly, the jobs would be automatically redirected to the other nodes for ensuring
that the distributed computing does not fail (Chen et al. 2014).
The multiple copies of all the data are managed automatically. The Hadoop provides
significant flexibility to the organization for storing and managing data easily. Unlike
the conventional relational databases, there is no requirement of preprocessing the
data prior storing it (Kim, Trimi and Chung 2014). With the implementation of
Hadoop, the organizations could store as much data as it is required and then take the
decision about what to do with the data later.
It includes the unstructured data like the text, videos or any image. This open source
structure of Hadoop is free and it utilizes the commodity hardware for storing
significantly large amount of data (Watson 2014). With the help of Hadoop, the
organisations could gain the ability of growing the systems for the improved handling
of data by the simple addition of the nodes. Due to this features, there is a major
benefit of minimal administration that is required (Vitolo et al. 2015).
Some of the issues that are observed within Hadoop are:
MapReduce programming might not work efficiently for all problems: It might be
appropriate for the information requests as well as the problems that could be divided into
the independent units but it has not been used for the iterative and the interactive tasks of
analytics. The MapReduce is significantly file intensive (Jin et al.2015). As the nodes do
not perform the intercommunication except using the shuffles and the sorts, the iterative
algorithms need several map shuffle phases for the efficient completion. It creates
against the hardware failure. In the situation when any of the node is not working
properly, the jobs would be automatically redirected to the other nodes for ensuring
that the distributed computing does not fail (Chen et al. 2014).
The multiple copies of all the data are managed automatically. The Hadoop provides
significant flexibility to the organization for storing and managing data easily. Unlike
the conventional relational databases, there is no requirement of preprocessing the
data prior storing it (Kim, Trimi and Chung 2014). With the implementation of
Hadoop, the organizations could store as much data as it is required and then take the
decision about what to do with the data later.
It includes the unstructured data like the text, videos or any image. This open source
structure of Hadoop is free and it utilizes the commodity hardware for storing
significantly large amount of data (Watson 2014). With the help of Hadoop, the
organisations could gain the ability of growing the systems for the improved handling
of data by the simple addition of the nodes. Due to this features, there is a major
benefit of minimal administration that is required (Vitolo et al. 2015).
Some of the issues that are observed within Hadoop are:
MapReduce programming might not work efficiently for all problems: It might be
appropriate for the information requests as well as the problems that could be divided into
the independent units but it has not been used for the iterative and the interactive tasks of
analytics. The MapReduce is significantly file intensive (Jin et al.2015). As the nodes do
not perform the intercommunication except using the shuffles and the sorts, the iterative
algorithms need several map shuffle phases for the efficient completion. It creates
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

7BIG DATA ANALYSIS
multiple files among the MapReduce phases and it is inefficient for the advanced analytic
computing (Hashem et al. 2015).
Knowledge gap: It could be significantly difficult to discover the entry-level
programmers who possess the adequate Java skills in being significantly productive with
the MapReduce.
Data security: The major challenge that is associated with Hadoop is the challenge
around the segmented data security issues, even though the new technologies are easily
surfacing. The proper utilization of the Kerberos authentication protocol could be the
security measure for the Hadoop environments (Pääkkönen and Pakkala 2015). Extensive data management and data governance: Hadoop does not possess the easy-to-
use, complete feature tools for the data management, data cleansing, metadata and the
governance. Specifically is lacking the tools for the data quality and the standardization
(Bhatt, Dey and Ashour 2017).
Spark
The Apache Spark is also a part of the ecosystem of Hadoop, but it is also used in different
situation as a single technology. This is typical type of technology, which is used for processing
the Big Data within the Hadoop environment. The main advantage of the Apache Spark over the
traditional type of Hadoop system is that it is hundred times faster while compared with the
Hadoop system. Currently, interest in this technology is growing noticeably (Zhang 2016).
Apache Spark is referred as the fast, in-memory data processing engine with the elegant and the
expressive development APIs for allowing the data workers to execute the streaming, SQL
workloads or the machine learning efficiently, which needs the fast iterative access to the
datasets. With the Spark executing on the Apache Hadoop YARN, the developers everywhere
multiple files among the MapReduce phases and it is inefficient for the advanced analytic
computing (Hashem et al. 2015).
Knowledge gap: It could be significantly difficult to discover the entry-level
programmers who possess the adequate Java skills in being significantly productive with
the MapReduce.
Data security: The major challenge that is associated with Hadoop is the challenge
around the segmented data security issues, even though the new technologies are easily
surfacing. The proper utilization of the Kerberos authentication protocol could be the
security measure for the Hadoop environments (Pääkkönen and Pakkala 2015). Extensive data management and data governance: Hadoop does not possess the easy-to-
use, complete feature tools for the data management, data cleansing, metadata and the
governance. Specifically is lacking the tools for the data quality and the standardization
(Bhatt, Dey and Ashour 2017).
Spark
The Apache Spark is also a part of the ecosystem of Hadoop, but it is also used in different
situation as a single technology. This is typical type of technology, which is used for processing
the Big Data within the Hadoop environment. The main advantage of the Apache Spark over the
traditional type of Hadoop system is that it is hundred times faster while compared with the
Hadoop system. Currently, interest in this technology is growing noticeably (Zhang 2016).
Apache Spark is referred as the fast, in-memory data processing engine with the elegant and the
expressive development APIs for allowing the data workers to execute the streaming, SQL
workloads or the machine learning efficiently, which needs the fast iterative access to the
datasets. With the Spark executing on the Apache Hadoop YARN, the developers everywhere

8BIG DATA ANALYSIS
could now execute the creation of the application for exploiting the power of Spark, derive the
insights and then enrich the workloads of the data science within the single, shared dataset in the
Hadoop (Suthaharan 2014). The architecture of the Hadoop YARN offers the base for allowing
the sharing of common dataset and the cluster by the Spark and the other applications with
ensuring the constant levels of the response and the service. The Spark is presently one of the
many data access engines that works with the YARN in HDP. Spark has been designed for the
data science and the abstraction helps in simplification of the data science (Zhang et al. 2015).
The data scientists majorly utilize the machine learning that is the set of methods as well as the
algorithms that could learn from the data. These particular algorithms are frequently iterative and
the ability of Spark to cache the dataset in the memory significantly speeds up the iterative data
processing and it makes Spark the ideal processing engine for the implementation of these
algorithms. There are several benefits that could be gained from by using Apache Spark are:
Increased data processing that helps in reducing the number of the read-write to the disk.
The Spark also initiates with similar concept of being significantly able to execute the
jobs of MapReduce except that is initially places data into the RDDs (Resilient
Distributed Datasets) for allowing the proper storing of the data in the memory that could
be accessed anytime (Demchenko, De Laat and Membrey 2014). This access to the real
time data helps in proper working of the organizations.
As with the increase of the amount of data that is captured from within the organizations
are increasing exponentially, there is the major requirement of swift processing of all the
data and provide real time results by the processing and the manipulation of the data.
Spark helps in the analysis of the real time data when it has been collected. The
applications could be categorized as the fraud detection, the electronic data of trading,
could now execute the creation of the application for exploiting the power of Spark, derive the
insights and then enrich the workloads of the data science within the single, shared dataset in the
Hadoop (Suthaharan 2014). The architecture of the Hadoop YARN offers the base for allowing
the sharing of common dataset and the cluster by the Spark and the other applications with
ensuring the constant levels of the response and the service. The Spark is presently one of the
many data access engines that works with the YARN in HDP. Spark has been designed for the
data science and the abstraction helps in simplification of the data science (Zhang et al. 2015).
The data scientists majorly utilize the machine learning that is the set of methods as well as the
algorithms that could learn from the data. These particular algorithms are frequently iterative and
the ability of Spark to cache the dataset in the memory significantly speeds up the iterative data
processing and it makes Spark the ideal processing engine for the implementation of these
algorithms. There are several benefits that could be gained from by using Apache Spark are:
Increased data processing that helps in reducing the number of the read-write to the disk.
The Spark also initiates with similar concept of being significantly able to execute the
jobs of MapReduce except that is initially places data into the RDDs (Resilient
Distributed Datasets) for allowing the proper storing of the data in the memory that could
be accessed anytime (Demchenko, De Laat and Membrey 2014). This access to the real
time data helps in proper working of the organizations.
As with the increase of the amount of data that is captured from within the organizations
are increasing exponentially, there is the major requirement of swift processing of all the
data and provide real time results by the processing and the manipulation of the data.
Spark helps in the analysis of the real time data when it has been collected. The
applications could be categorized as the fraud detection, the electronic data of trading,
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

9BIG DATA ANALYSIS
and the log processing in the live streams (Zomaya and Sakr 2017). The graph processing
is the major functionality of Spark. Apart from the Steam processing, Spark could also be
utilized for the graph processing from the advertising to the social data analysis, the
graph processing captures the relationships in the data among the entities (Abuín et al.
2015).
Even though there are several benefits of Apache Spark, there are some limitations to this
technology that is required to be considered and analysed prior utilization. Some of the major
drawbacks of the Apache Spark are:
Absence of the in-house file management system: The Apache Spark majorly depends on
any other third party system for the capabilities of the file management and therefore it
makes this platform significantly less efficient than the other platforms. When it has not
been merged with HDFS or the Hadoop Distributed File System, it requires to be utilized
with any other cloud based platform of data (Baaziz and Quoniam 2014).
Huge number of smaller files: This is considered as another prospect of the file
management that is a drawback of Spark. As the Apache Spark is used with Hadoop, the
developers usually face the issues of the small files. HDFS supports the restricted number
of the large files rather than the large number of the small files. Inefficient real time processing: When the Spark streaming is considered, the major
arriving stream is segmented into the batches of the pre-defined intervals and each of the
batch is then processed as the RDD or Resilient Distributed Dataset. Afterwards the
operations has been applied to each of the batch, results are then returned back in the
batches. Therefore, the treatment of data in the batches do not qualify to be referred as the
and the log processing in the live streams (Zomaya and Sakr 2017). The graph processing
is the major functionality of Spark. Apart from the Steam processing, Spark could also be
utilized for the graph processing from the advertising to the social data analysis, the
graph processing captures the relationships in the data among the entities (Abuín et al.
2015).
Even though there are several benefits of Apache Spark, there are some limitations to this
technology that is required to be considered and analysed prior utilization. Some of the major
drawbacks of the Apache Spark are:
Absence of the in-house file management system: The Apache Spark majorly depends on
any other third party system for the capabilities of the file management and therefore it
makes this platform significantly less efficient than the other platforms. When it has not
been merged with HDFS or the Hadoop Distributed File System, it requires to be utilized
with any other cloud based platform of data (Baaziz and Quoniam 2014).
Huge number of smaller files: This is considered as another prospect of the file
management that is a drawback of Spark. As the Apache Spark is used with Hadoop, the
developers usually face the issues of the small files. HDFS supports the restricted number
of the large files rather than the large number of the small files. Inefficient real time processing: When the Spark streaming is considered, the major
arriving stream is segmented into the batches of the pre-defined intervals and each of the
batch is then processed as the RDD or Resilient Distributed Dataset. Afterwards the
operations has been applied to each of the batch, results are then returned back in the
batches. Therefore, the treatment of data in the batches do not qualify to be referred as the
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

10BIG DATA ANALYSIS
real time processing but as there is significant speed in the operations, the Apache Spark
could be referred as inefficient processing platform (Hashem et al. 2016).
Data Lakes
Data lakes is one of the major technology in the Big Data which is used by many of the
enterprises for accessing vast stores of data. In this case there are huge data repository which
collects different kind of data from different kind of sources and this data are stored in the
repository while the data maintain its natural state. Though various types of data is collected and
stored using the data lakes, it is quite different from a normal data warehouse. It is different from
a data warehouse in the sense that it process and structures the data for the storage purpose which
is missing in normal data warehouses. The services of data lake is quite useful for the enterprises
who are aiming to store the data in very much effective manner but they are not sure about how
to use this technology. Some important categories of the Internet of Things data can fit within
this type of category and the current trends in the IoT is one of the main reason behind the
important rate of growth of the Data Lakes. Some of the major benefits of data lakes includes:
Ability of deriving the value from unrestricted kinds of data
Ability of storing all kinds of the unstructured and structured data in the data lakes from
the social media data to the CRM data
Increased flexibility
Unrestricted methods to query the data
Application of variety of the tools for gaining valuable insight into the meaning of the
data
Elimination of the data silos
real time processing but as there is significant speed in the operations, the Apache Spark
could be referred as inefficient processing platform (Hashem et al. 2016).
Data Lakes
Data lakes is one of the major technology in the Big Data which is used by many of the
enterprises for accessing vast stores of data. In this case there are huge data repository which
collects different kind of data from different kind of sources and this data are stored in the
repository while the data maintain its natural state. Though various types of data is collected and
stored using the data lakes, it is quite different from a normal data warehouse. It is different from
a data warehouse in the sense that it process and structures the data for the storage purpose which
is missing in normal data warehouses. The services of data lake is quite useful for the enterprises
who are aiming to store the data in very much effective manner but they are not sure about how
to use this technology. Some important categories of the Internet of Things data can fit within
this type of category and the current trends in the IoT is one of the main reason behind the
important rate of growth of the Data Lakes. Some of the major benefits of data lakes includes:
Ability of deriving the value from unrestricted kinds of data
Ability of storing all kinds of the unstructured and structured data in the data lakes from
the social media data to the CRM data
Increased flexibility
Unrestricted methods to query the data
Application of variety of the tools for gaining valuable insight into the meaning of the
data
Elimination of the data silos

11BIG DATA ANALYSIS
Democratized access to the data using the single, combined view of the data across the
organization when utilizing the effective platform of data management
Even though the data lakes provides several benefits, there are some challenges of the data lakes
that are required to be considered and analysed. Some of the challenges includes:
Understanding the limitations and the purpose of technology: The Hadoop environment
offers the vendor with the independent tool chain for the data storage, analytics and the
management in proper format and it could manage the infinite quantity of the data and
along with the add-ons, the real time and the data science use cases are made available
for any enterprise.
In the present world of the information security and vast data breaches, the security
structure is significantly important stage when the introduction of data lake is done.
There is significant issues related to the data governance within the data lakes. Defining
the security policies as well as the procedure could be problematic for the organizations
and it makes the data management significantly difficult.
R technology
The R is also an open source technology for the Big Data. The R is mainly designed as a
programming language a typical type of software environment that is used for handling the data
related with the statistics. R programming language involves the functions, which supports the
linear modelling, the non-linear modelling, the classical statistics, the classifications, as well as
clustering. It has prevailed as significantly popular in the academic settings because of the strong
features and fact that it is significantly free for downloading in the source code form under terms
of Free Software Foundation. It compiles and executes on the Unix platforms as well as another
Democratized access to the data using the single, combined view of the data across the
organization when utilizing the effective platform of data management
Even though the data lakes provides several benefits, there are some challenges of the data lakes
that are required to be considered and analysed. Some of the challenges includes:
Understanding the limitations and the purpose of technology: The Hadoop environment
offers the vendor with the independent tool chain for the data storage, analytics and the
management in proper format and it could manage the infinite quantity of the data and
along with the add-ons, the real time and the data science use cases are made available
for any enterprise.
In the present world of the information security and vast data breaches, the security
structure is significantly important stage when the introduction of data lake is done.
There is significant issues related to the data governance within the data lakes. Defining
the security policies as well as the procedure could be problematic for the organizations
and it makes the data management significantly difficult.
R technology
The R is also an open source technology for the Big Data. The R is mainly designed as a
programming language a typical type of software environment that is used for handling the data
related with the statistics. R programming language involves the functions, which supports the
linear modelling, the non-linear modelling, the classical statistics, the classifications, as well as
clustering. It has prevailed as significantly popular in the academic settings because of the strong
features and fact that it is significantly free for downloading in the source code form under terms
of Free Software Foundation. It compiles and executes on the Unix platforms as well as another
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 20
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.