COIT20253: Big Data for Sentiment Analysis in Business Intelligence
VerifiedAdded on 2023/06/13
|14
|3543
|232
Report
AI Summary
This report explores the application of big data in sentiment analysis, focusing on data collection from social media and web sources, storage solutions using cloud services like Amazon S3, and the processes involved in sentiment analysis using text analytics. It discusses business continuity strategies, disaster recovery plans, and the importance of maintaining services in the face of unforeseen events. The report details a user cookie log processing strategy, including data crawling, tag matching, and pre-processing, followed by data joining and initial processing using tools like Python and Hadoop Hive. Machine learning algorithms, specifically Naive Bayes, are employed for log data prediction, enabling insights into user trends and behaviors. The data flow architecture is described, highlighting the steps from web log data capture to storage on Amazon S3, emphasizing data standardization and noise removal throughout the process. Desklib provides access to similar assignments and study resources for students.
“Big Data for Sentiment Analysis”
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Abstract
Media is an medium of sites and web applications which design such a way to connect people in quick
manner for sharing content and real-time data.
Such people started to store apps on mobile or smart-phone or tablet, but the real logic behind is that
this communication is dome by computers.
We can share pictures, events and thoughts in real-time basis to transform the way of business and life.
Many Retailers, Organizations, Stores and Outlets are engage on media platform as part of their
marketing strategy and they get a better results. And we can say that this is the source of success with
media is to treat it with same care, respect and attention with our all marketing.
Rapid increasing in the data volume of sentiment rich social media on the web has resulted in an
increased interest among researchers regarding sentimental analysis and opinion.
The main target of social media is to provide real and relevant content to our products to the customers
so that could share our post to others.
Today, Big Data is in boom and why not is should be because every business needs to run on digitalis
and faster way so that we can connect with more customers in short period of time.
Data Collection and Storage
Data Analysis is the biggest challenges issue in the world due to huge volume of data. Social Media
Networks is also generating huge amount of data daily basis which contain structured, semi –
structured and unstructured data.
In this the data are in the format of audio, video, text files, numbers, hashtags and URL’s.
Data Collection : It is task to collect data in any format from different different sources and process for
further organizational work. Data can be collected through websites, blackbox, audio, video, text file
and user activities.
Business is running behind the data. So in respect to the data source main target is social media, where
data is collecting in cookie, userlogs, user activities and some likes or tweets.
Data Collection System : As per my scenario the data is collected through user cookie format which
contain user information. If user is visiting any websites then the site is captured user data in the form
of cookie. Further these cookie data going to be processed using in applications and further getting the
user insights - “What they are looking for”.
Media is an medium of sites and web applications which design such a way to connect people in quick
manner for sharing content and real-time data.
Such people started to store apps on mobile or smart-phone or tablet, but the real logic behind is that
this communication is dome by computers.
We can share pictures, events and thoughts in real-time basis to transform the way of business and life.
Many Retailers, Organizations, Stores and Outlets are engage on media platform as part of their
marketing strategy and they get a better results. And we can say that this is the source of success with
media is to treat it with same care, respect and attention with our all marketing.
Rapid increasing in the data volume of sentiment rich social media on the web has resulted in an
increased interest among researchers regarding sentimental analysis and opinion.
The main target of social media is to provide real and relevant content to our products to the customers
so that could share our post to others.
Today, Big Data is in boom and why not is should be because every business needs to run on digitalis
and faster way so that we can connect with more customers in short period of time.
Data Collection and Storage
Data Analysis is the biggest challenges issue in the world due to huge volume of data. Social Media
Networks is also generating huge amount of data daily basis which contain structured, semi –
structured and unstructured data.
In this the data are in the format of audio, video, text files, numbers, hashtags and URL’s.
Data Collection : It is task to collect data in any format from different different sources and process for
further organizational work. Data can be collected through websites, blackbox, audio, video, text file
and user activities.
Business is running behind the data. So in respect to the data source main target is social media, where
data is collecting in cookie, userlogs, user activities and some likes or tweets.
Data Collection System : As per my scenario the data is collected through user cookie format which
contain user information. If user is visiting any websites then the site is captured user data in the form
of cookie. Further these cookie data going to be processed using in applications and further getting the
user insights - “What they are looking for”.

The data should be collected in the form which can gives the user identification or information from
cookie. If I am talking about the cookie log, then it will captured user name, user email, user id,
browser name, system ip, time stamp, location, interest area, user location, current url, previous url,
hashtag, page like etc.
Some time data is captured in the form of log files that we can use those for sentiment analysis. Today
everybody is talking about big data means collecting huge amount of data and getting insights from the
data.
What people looking for ?
What they are talking about ?
Which is the highest trends in the market ?
Which is the top word for analysis ?
Data Storage : Data is collecting in huge volume but we also require storage devices so that we
can store that data. Data cant be stored in Hard drive or floppy disk, it requires scalable devices and on-
line medium which can easily shared those data to users or organization.
Cloud services comes under this role for storage high volume of data in different different locations.
Amazon introduced S3 bucket cloud device to store high volume of data at any place. The data is also
secure and accessible from any where the world on cloud. Huge amount of data is storing on S3 cloud
in the form of cookie, userlog, csv, text file etc.
cookie. If I am talking about the cookie log, then it will captured user name, user email, user id,
browser name, system ip, time stamp, location, interest area, user location, current url, previous url,
hashtag, page like etc.
Some time data is captured in the form of log files that we can use those for sentiment analysis. Today
everybody is talking about big data means collecting huge amount of data and getting insights from the
data.
What people looking for ?
What they are talking about ?
Which is the highest trends in the market ?
Which is the top word for analysis ?
Data Storage : Data is collecting in huge volume but we also require storage devices so that we
can store that data. Data cant be stored in Hard drive or floppy disk, it requires scalable devices and on-
line medium which can easily shared those data to users or organization.
Cloud services comes under this role for storage high volume of data in different different locations.
Amazon introduced S3 bucket cloud device to store high volume of data at any place. The data is also
secure and accessible from any where the world on cloud. Huge amount of data is storing on S3 cloud
in the form of cookie, userlog, csv, text file etc.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

Data in Action
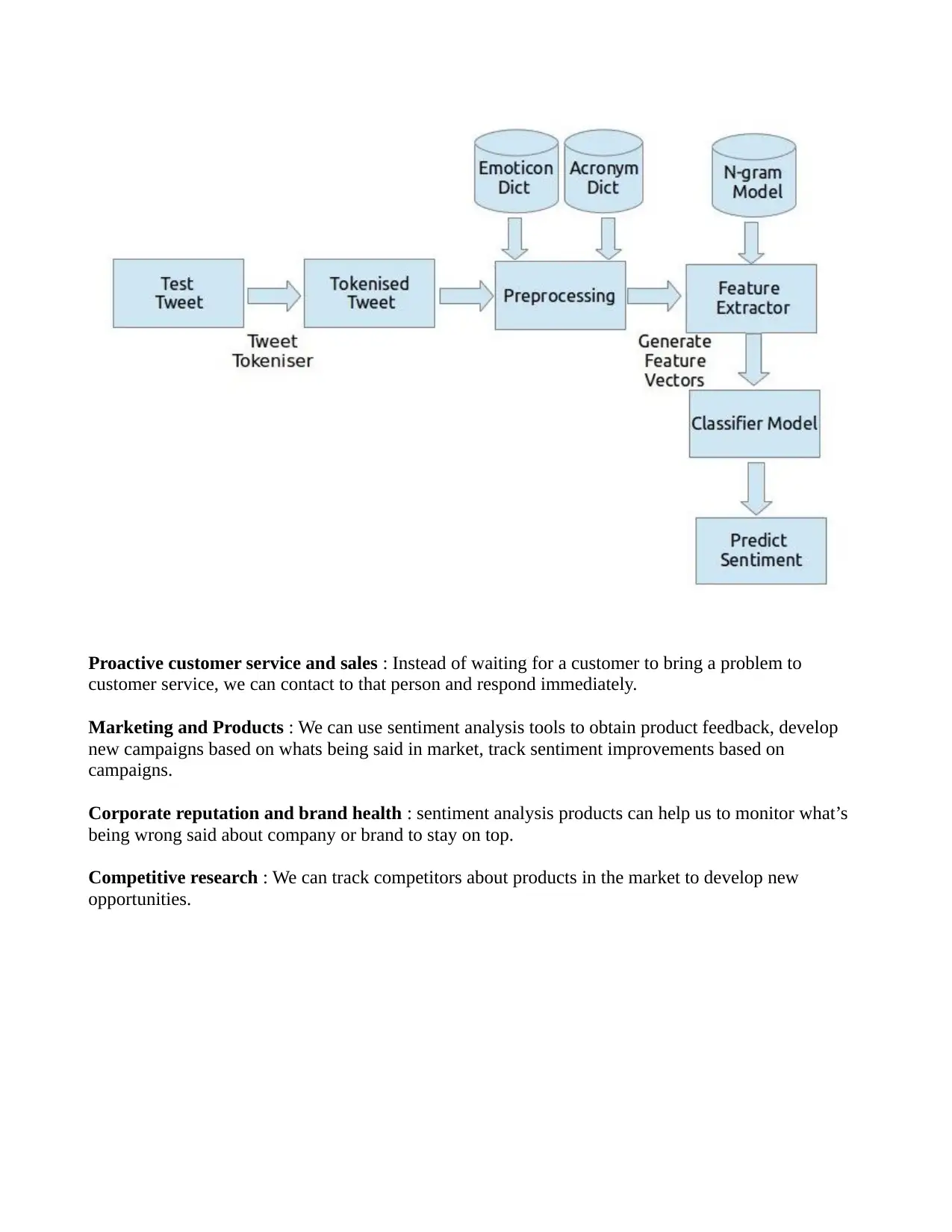
Analysis of Sentiment is the processes using of text analytics to extract various source of data for
opinions and analysis.
The sentiment analysis is done on the data that is collecting from the websites and various social media
platforms like Amazon, Twitter, Instagram, LinkedIn and WhatApp etc.
Mostly businessman, government and politicians are using analysis to understand how the people feel
about themselves and their policies.
Sentiment analysis gauges a customers attitude and preferences in relation to a company’s products,
services, brand and more. Companies use surveys, polls and social listening – which may not always
present their true attitudes.
Analysis of Sentiment is the processes using of text analytics to extract various source of data for
opinions and analysis.
The sentiment analysis is done on the data that is collecting from the websites and various social media
platforms like Amazon, Twitter, Instagram, LinkedIn and WhatApp etc.
Mostly businessman, government and politicians are using analysis to understand how the people feel
about themselves and their policies.
Sentiment analysis gauges a customers attitude and preferences in relation to a company’s products,
services, brand and more. Companies use surveys, polls and social listening – which may not always
present their true attitudes.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
Proactive customer service and sales : Instead of waiting for a customer to bring a problem to
customer service, we can contact to that person and respond immediately.
Marketing and Products : We can use sentiment analysis tools to obtain product feedback, develop
new campaigns based on whats being said in market, track sentiment improvements based on
campaigns.
Corporate reputation and brand health : sentiment analysis products can help us to monitor what’s
being wrong said about company or brand to stay on top.
Competitive research : We can track competitors about products in the market to develop new
opportunities.
customer service, we can contact to that person and respond immediately.
Marketing and Products : We can use sentiment analysis tools to obtain product feedback, develop
new campaigns based on whats being said in market, track sentiment improvements based on
campaigns.
Corporate reputation and brand health : sentiment analysis products can help us to monitor what’s
being wrong said about company or brand to stay on top.
Competitive research : We can track competitors about products in the market to develop new
opportunities.

Business continuity
It is the ability of an organization to maintain services and product features in the market.
It is important for every organization which can small or big of any size, but it may not be practical for
any but the largest enterprises or organizations to maintain their functions from disaster. They also
maintaining their function based on cost, revenue and budgets.
Online business disaster : When an unseen event takes place and causes daily operations to come a
halt, a organization will need to recover as quickly as possible to ensure we are continue providing our
services to the client and customers.
It can happen due to market crises, due to resources, due to financial planning but company needs to be
continue survive the products and services to the customers.
Disaster recovery : It is the process of creating, implementing and maintaining a total business
recovery plan in time consuming for large organizations its very very important to have an strategy
planning and disaster recovery plan to ensure business survival.
In the real life the companies making below mistakes :
Considering the impact of interrupted applications not business function
Considering application in isolation
Paying to little attention to financial impact
Failing to recognize data center applications
Confusing a risk assessment with a business impact analysis
Acceptance with a business impact analysis
Pre determined results
Executive Summary :
Topic : “User Cookie log capturing”
As per my proposal cookie log processing is one of the big and data processing strategy which can help
to recover and get the insights of the user data from log files.
User log on the any website, the robots of the website will captured user activity information and stored
as in log files. From the Python analytics tools we can crawl the website cookie log data and generate
the insights based on the user activity.
The cookie log will have around 30 fields like –
user email,
user id,
people name,
people id,
hashtags,
It is the ability of an organization to maintain services and product features in the market.
It is important for every organization which can small or big of any size, but it may not be practical for
any but the largest enterprises or organizations to maintain their functions from disaster. They also
maintaining their function based on cost, revenue and budgets.
Online business disaster : When an unseen event takes place and causes daily operations to come a
halt, a organization will need to recover as quickly as possible to ensure we are continue providing our
services to the client and customers.
It can happen due to market crises, due to resources, due to financial planning but company needs to be
continue survive the products and services to the customers.
Disaster recovery : It is the process of creating, implementing and maintaining a total business
recovery plan in time consuming for large organizations its very very important to have an strategy
planning and disaster recovery plan to ensure business survival.
In the real life the companies making below mistakes :
Considering the impact of interrupted applications not business function
Considering application in isolation
Paying to little attention to financial impact
Failing to recognize data center applications
Confusing a risk assessment with a business impact analysis
Acceptance with a business impact analysis
Pre determined results
Executive Summary :
Topic : “User Cookie log capturing”
As per my proposal cookie log processing is one of the big and data processing strategy which can help
to recover and get the insights of the user data from log files.
User log on the any website, the robots of the website will captured user activity information and stored
as in log files. From the Python analytics tools we can crawl the website cookie log data and generate
the insights based on the user activity.
The cookie log will have around 30 fields like –
user email,
user id,
people name,
people id,
hashtags,
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

interest areas,
user locations,
time stamp,
current_url,
previous_url,
destination_url,
user_agent,
sg_timedate,
user_device,
ip,
country_code,
country_name,
region_code,
region_name,
city,
zip_code,
time_zone,
latitude,
longitude,
metro_code.
The proposal data is based on 2 types – known log data ( user registered on websites at the time of
visiting) and unknown data ( user did not register themselves, he just only visiting on the site).
Known log and Unknown log data having 31 column which contains all the above fields but people
data having only 5 fields which is user_email, user_name, people_id,people_name and count.
Program execution flow :
Step a)
Here we are running cran job daily which is written in python code will gives us an .CSV file which is
containing below fields
destination, user_name, location, hashtags, interest area, interest keywords, date, current_url,
previous_url.
Step b)
We used this output file as an input in java code and it will gives again an .CSV file with time stamp
which contains below column
tags, url, title, location, hashtags, interest area.
Step c)
Now in this flow first we download log files from Amazon S3 bucket to local hdfs hive directory and
join with .CSV file and getting one parquet file which contain data without noisy.
Step d)
We used this parquet file to LogInitial job flow to get deterministic result, and this will give three
output files – known log, unknown log and people.
Step e)
In this phase we used only people log file because it contain user_email_user_id,people_name and
people_id. Remaining file we again stores in amazon s3 bucket due to fast processing.
user locations,
time stamp,
current_url,
previous_url,
destination_url,
user_agent,
sg_timedate,
user_device,
ip,
country_code,
country_name,
region_code,
region_name,
city,
zip_code,
time_zone,
latitude,
longitude,
metro_code.
The proposal data is based on 2 types – known log data ( user registered on websites at the time of
visiting) and unknown data ( user did not register themselves, he just only visiting on the site).
Known log and Unknown log data having 31 column which contains all the above fields but people
data having only 5 fields which is user_email, user_name, people_id,people_name and count.
Program execution flow :
Step a)
Here we are running cran job daily which is written in python code will gives us an .CSV file which is
containing below fields
destination, user_name, location, hashtags, interest area, interest keywords, date, current_url,
previous_url.
Step b)
We used this output file as an input in java code and it will gives again an .CSV file with time stamp
which contains below column
tags, url, title, location, hashtags, interest area.
Step c)
Now in this flow first we download log files from Amazon S3 bucket to local hdfs hive directory and
join with .CSV file and getting one parquet file which contain data without noisy.
Step d)
We used this parquet file to LogInitial job flow to get deterministic result, and this will give three
output files – known log, unknown log and people.
Step e)
In this phase we used only people log file because it contain user_email_user_id,people_name and
people_id. Remaining file we again stores in amazon s3 bucket due to fast processing.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Step f)
Here we use people file in LogAutomation and after processing this will gives 4 files known log,
unknown log, people and acknowledgement file (containing log count). Again we use only people file
for next day job process and remaining files we stored in s3 bucker.
Step g)
This process is the final probabilistic matching with our known log data with unknown log data to find
out count of user_email,user_name,people_id and people_name whose count is maximum only those
data will assign to known log based on daily job count.
Here we used Naive Bayes machine learning algorithm model to use most informative variables from
dataset and predict the output.
Data Collection :
Cookie log processing will have below process to the data :
a) Crawling the cookie log from websites – It will crawl the user cookie from the website and generate
the log file. The data will get in two types –
Known log cookie – It is the process where user visits the site and register themselves using there email
id, name, mobile no, address and country.
Unknown log – It is the process where user only visits the sites but did not register on the websites.
b) Tag matching with interest area – It will matching the user hashtag to interest area and getting the
insights.
Storage System :
After data collection and tag matching, we will put all data file to hadoop module Hive.
We will create three different tables inside Hive.
# Known-log
# Unknow-log
# People
# Known-log table having all 30 columns
# Unknown-log table having the same 30 columns
# People table having only 4 column which gives us an prediction based on email id.
c) Log Pre Processing – It will remove noisy data from the log file. If there is any missing values and
null files in file then it will replace those to ‘NA’ and values will separated by pipes (|) or comma (,)
and space ( ).
d) Joining user data – It will join the noisy data with tag data and gives an parquet file. This file we
stored in hive directory and set the path in hive tables so on the query processing time it can take the
data from mentioned location.
Here we use people file in LogAutomation and after processing this will gives 4 files known log,
unknown log, people and acknowledgement file (containing log count). Again we use only people file
for next day job process and remaining files we stored in s3 bucker.
Step g)
This process is the final probabilistic matching with our known log data with unknown log data to find
out count of user_email,user_name,people_id and people_name whose count is maximum only those
data will assign to known log based on daily job count.
Here we used Naive Bayes machine learning algorithm model to use most informative variables from
dataset and predict the output.
Data Collection :
Cookie log processing will have below process to the data :
a) Crawling the cookie log from websites – It will crawl the user cookie from the website and generate
the log file. The data will get in two types –
Known log cookie – It is the process where user visits the site and register themselves using there email
id, name, mobile no, address and country.
Unknown log – It is the process where user only visits the sites but did not register on the websites.
b) Tag matching with interest area – It will matching the user hashtag to interest area and getting the
insights.
Storage System :
After data collection and tag matching, we will put all data file to hadoop module Hive.
We will create three different tables inside Hive.
# Known-log
# Unknow-log
# People
# Known-log table having all 30 columns
# Unknown-log table having the same 30 columns
# People table having only 4 column which gives us an prediction based on email id.
c) Log Pre Processing – It will remove noisy data from the log file. If there is any missing values and
null files in file then it will replace those to ‘NA’ and values will separated by pipes (|) or comma (,)
and space ( ).
d) Joining user data – It will join the noisy data with tag data and gives an parquet file. This file we
stored in hive directory and set the path in hive tables so on the query processing time it can take the
data from mentioned location.

e) LogInitial processing – It will take input from Joining user data and will provide known user
information. User information will be based on registered user on websites.
f) LogAutomation processing – We will used sentiment analysis to get user trends. Data fetch by R
library for sentiment analysis.
g) Log data prediction – Will use machine learning Naive Bayes model to get unknown log user data.
This will used most informative fields from the list of table variables and gives an insights, So based on
the data we can take the further decision.
User Cookie Log Process Architecture
In the data flow architecture first web log data will captured into a file using Python code. After that we
will remove some duplicate and noisy values from the files based on sentiment fields.
Standardize field will generate output file and will take this into Supplement IP addresses with location
to detect user device IP and location.
Next step we will remove unused URL to activity lookup. After completion the cookie process we will
store the data files on Amazon S3 cloud service on daily basis. All the log data files stored in s3 bucket
in parquet format to consume less amount of storage size.
Cookie process is based on users log activity, If more users logging on page we will get more cookie
data.
information. User information will be based on registered user on websites.
f) LogAutomation processing – We will used sentiment analysis to get user trends. Data fetch by R
library for sentiment analysis.
g) Log data prediction – Will use machine learning Naive Bayes model to get unknown log user data.
This will used most informative fields from the list of table variables and gives an insights, So based on
the data we can take the further decision.
User Cookie Log Process Architecture
In the data flow architecture first web log data will captured into a file using Python code. After that we
will remove some duplicate and noisy values from the files based on sentiment fields.
Standardize field will generate output file and will take this into Supplement IP addresses with location
to detect user device IP and location.
Next step we will remove unused URL to activity lookup. After completion the cookie process we will
store the data files on Amazon S3 cloud service on daily basis. All the log data files stored in s3 bucket
in parquet format to consume less amount of storage size.
Cookie process is based on users log activity, If more users logging on page we will get more cookie
data.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

Data in Action :
Consumer-centric product design is sometimes called user centric design, and it is the process of
framing our product and services around the needs as per customer’s.
As per the above case study the user cookie data will used to sell or provide our services to maximum
number of count users. We are targeting only those users who is frequently visiting websites.
Recommendation system for sentiment analysis data is the system who can generate the product and
service based on user interest. If user is looking for food so our recommendation system automatically
generate some Hotel & Travel or Accommodation so that might be he can interest to take this service
along with food.
The websites can be of Tour & Travel, Food & Travel, Content Marketing, Product Development,
Service based, Hotel & Accommodation etc. Once the data is generated based on user interest, we can
sell our services and products to those users.
Once the data is collected we can analysis the key factor on data and after acknowledgement we can the
action on data. Based on the action user will shared some feedback about the services and products and
can take the user sentiment and make better our services to the market.
Consumer-centric product design is sometimes called user centric design, and it is the process of
framing our product and services around the needs as per customer’s.
As per the above case study the user cookie data will used to sell or provide our services to maximum
number of count users. We are targeting only those users who is frequently visiting websites.
Recommendation system for sentiment analysis data is the system who can generate the product and
service based on user interest. If user is looking for food so our recommendation system automatically
generate some Hotel & Travel or Accommodation so that might be he can interest to take this service
along with food.
The websites can be of Tour & Travel, Food & Travel, Content Marketing, Product Development,
Service based, Hotel & Accommodation etc. Once the data is generated based on user interest, we can
sell our services and products to those users.
Once the data is collected we can analysis the key factor on data and after acknowledgement we can the
action on data. Based on the action user will shared some feedback about the services and products and
can take the user sentiment and make better our services to the market.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Business continuity :
Analysis of Sentiment is also known as thoughts of mining to refers to the use of NLP and
computational linguistics to extract information from the given data and classify option.
To Understand continuity preparedness needs, as well the necessity for establishing business
continuity management policies and objectives.
Monitoring and reviewing the performance of the business continuity management system.
Continue improvement based on objective.
Identify documentation and implement to recover critical business processes.
A) Sentiment Classification : The process is also known as sentiment orientation. The opinions can be
classify one of the following – positive , negative, neutral.
The data can be classified based on below -
# Document level
# Sentence level
# Aspect level
B) Subjectivity Classification : It consists of the evaluating weather a given sentence is subjective or
not. The accuracy of sentiment classification can be improved by employing a better subjective
classification.
C) Tag Summarization : It is a process on extracting the main features of an entity shared with
documents and sentiment regarding them. The procedure can evolved either single document or multi
document summarization.
In single document users phase will containing only limited tags data in structured format while in
Multi document summarization users phase will consists text, audio, video, cookie, blackbox and plain
text files.
D) Opinion retrieval : The document that express opinions or review are retrieved based on the query.
In this the documents are ranked based on the review and score.
Analysis of Sentiment is also known as thoughts of mining to refers to the use of NLP and
computational linguistics to extract information from the given data and classify option.
To Understand continuity preparedness needs, as well the necessity for establishing business
continuity management policies and objectives.
Monitoring and reviewing the performance of the business continuity management system.
Continue improvement based on objective.
Identify documentation and implement to recover critical business processes.
A) Sentiment Classification : The process is also known as sentiment orientation. The opinions can be
classify one of the following – positive , negative, neutral.
The data can be classified based on below -
# Document level
# Sentence level
# Aspect level
B) Subjectivity Classification : It consists of the evaluating weather a given sentence is subjective or
not. The accuracy of sentiment classification can be improved by employing a better subjective
classification.
C) Tag Summarization : It is a process on extracting the main features of an entity shared with
documents and sentiment regarding them. The procedure can evolved either single document or multi
document summarization.
In single document users phase will containing only limited tags data in structured format while in
Multi document summarization users phase will consists text, audio, video, cookie, blackbox and plain
text files.
D) Opinion retrieval : The document that express opinions or review are retrieved based on the query.
In this the documents are ranked based on the review and score.

Sentence analysis of natural language texts is a large and developing field. Analysis or opinion mining
is the computational procedure of opinions of texts.
The proposed work is described below :
Framework construction : This framework is done in such a way to provide products
recommendation to the users on web or mobiles as per specific area wise. Admin is the responsibility
for maintaining the all details in server.
Admin can post the products and user can choose the product and shared the feedback related to
products.
Review collection : Admin collect reviews on various types which can be smiley, positive,negative,text
etc. All review are stored in database for future evaluation. Rating, review and emotions are assessment
in terms of quality.
Sentiment analysis : It is the process to identify, extract and study effective and useful information. It
is mostly applied for reviews and ratings for applications that range from marketing to customer
services to buy the products effective. In text reviews, extract keywords and matched with database.
And the smiley reviews are calculated based positive and negative symbols.
Recommendation system : It is the class of information filtering that seek to predict rating or
preference. User can search the product and view the list of products based on price and review details.
Implementing machine learning algorithm to classify the products based positive and negative.
Fake review monitoring : It is the phase to review the fake comments and review and it is analyzed by
admin. Admin can get the user account details, mobile number and id. So one user can post a review
that will be a genuine one.
is the computational procedure of opinions of texts.
The proposed work is described below :
Framework construction : This framework is done in such a way to provide products
recommendation to the users on web or mobiles as per specific area wise. Admin is the responsibility
for maintaining the all details in server.
Admin can post the products and user can choose the product and shared the feedback related to
products.
Review collection : Admin collect reviews on various types which can be smiley, positive,negative,text
etc. All review are stored in database for future evaluation. Rating, review and emotions are assessment
in terms of quality.
Sentiment analysis : It is the process to identify, extract and study effective and useful information. It
is mostly applied for reviews and ratings for applications that range from marketing to customer
services to buy the products effective. In text reviews, extract keywords and matched with database.
And the smiley reviews are calculated based positive and negative symbols.
Recommendation system : It is the class of information filtering that seek to predict rating or
preference. User can search the product and view the list of products based on price and review details.
Implementing machine learning algorithm to classify the products based positive and negative.
Fake review monitoring : It is the phase to review the fake comments and review and it is analyzed by
admin. Admin can get the user account details, mobile number and id. So one user can post a review
that will be a genuine one.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 14
Related Documents



Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.