Data Analysis Project: Probability, Regression, and Hypothesis Testing
VerifiedAdded on 2022/11/26
|11
|821
|194
Project
AI Summary
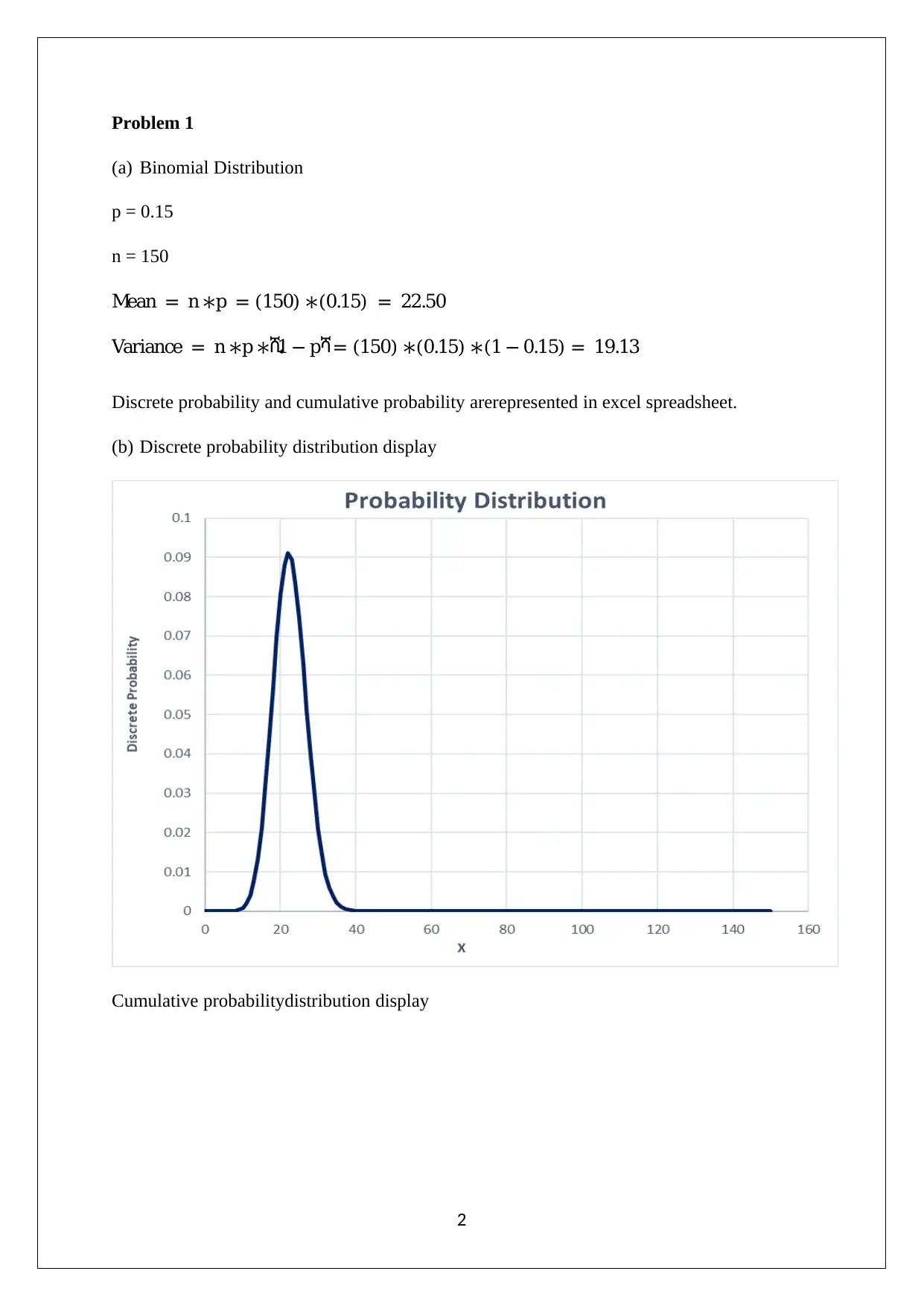
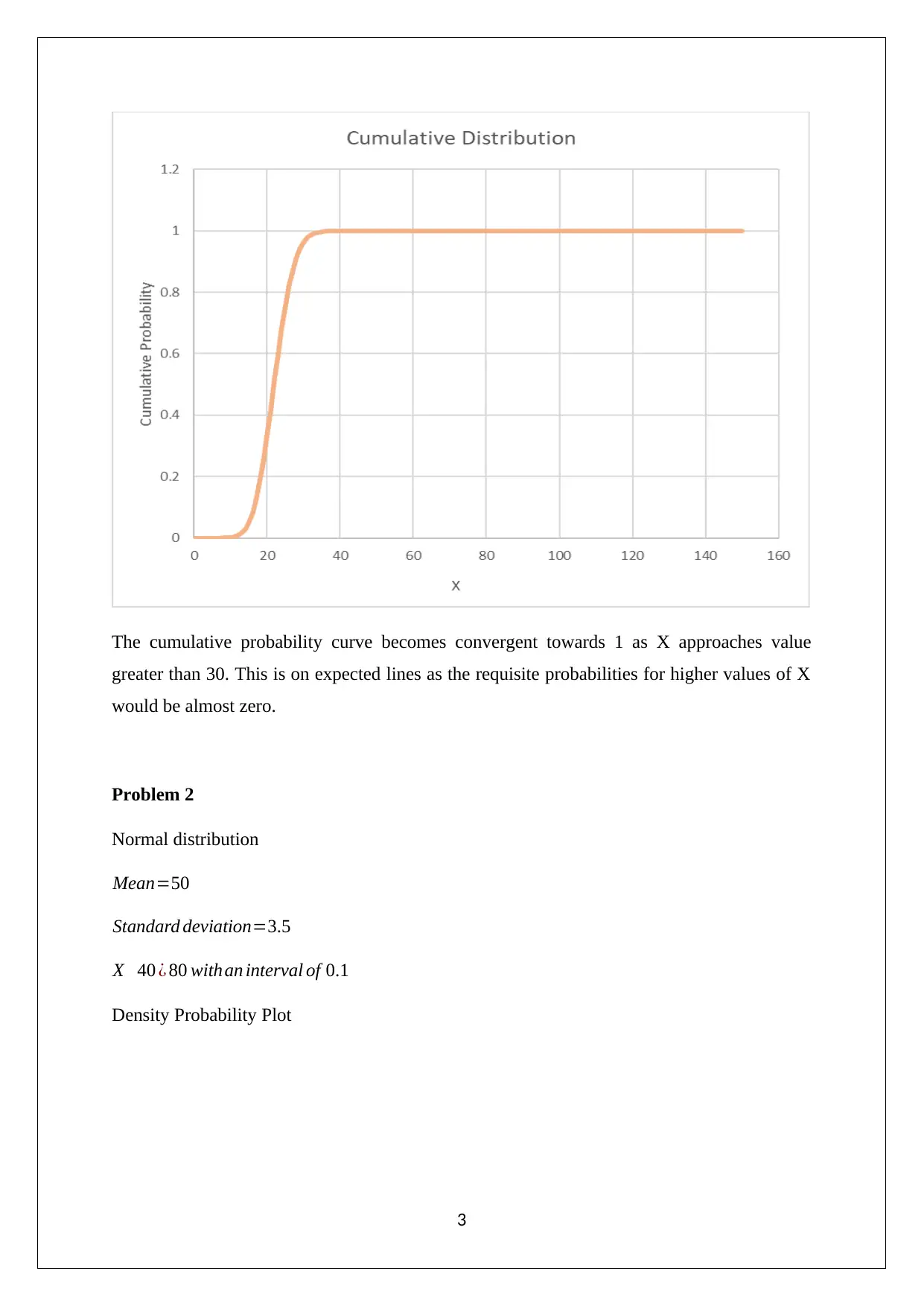
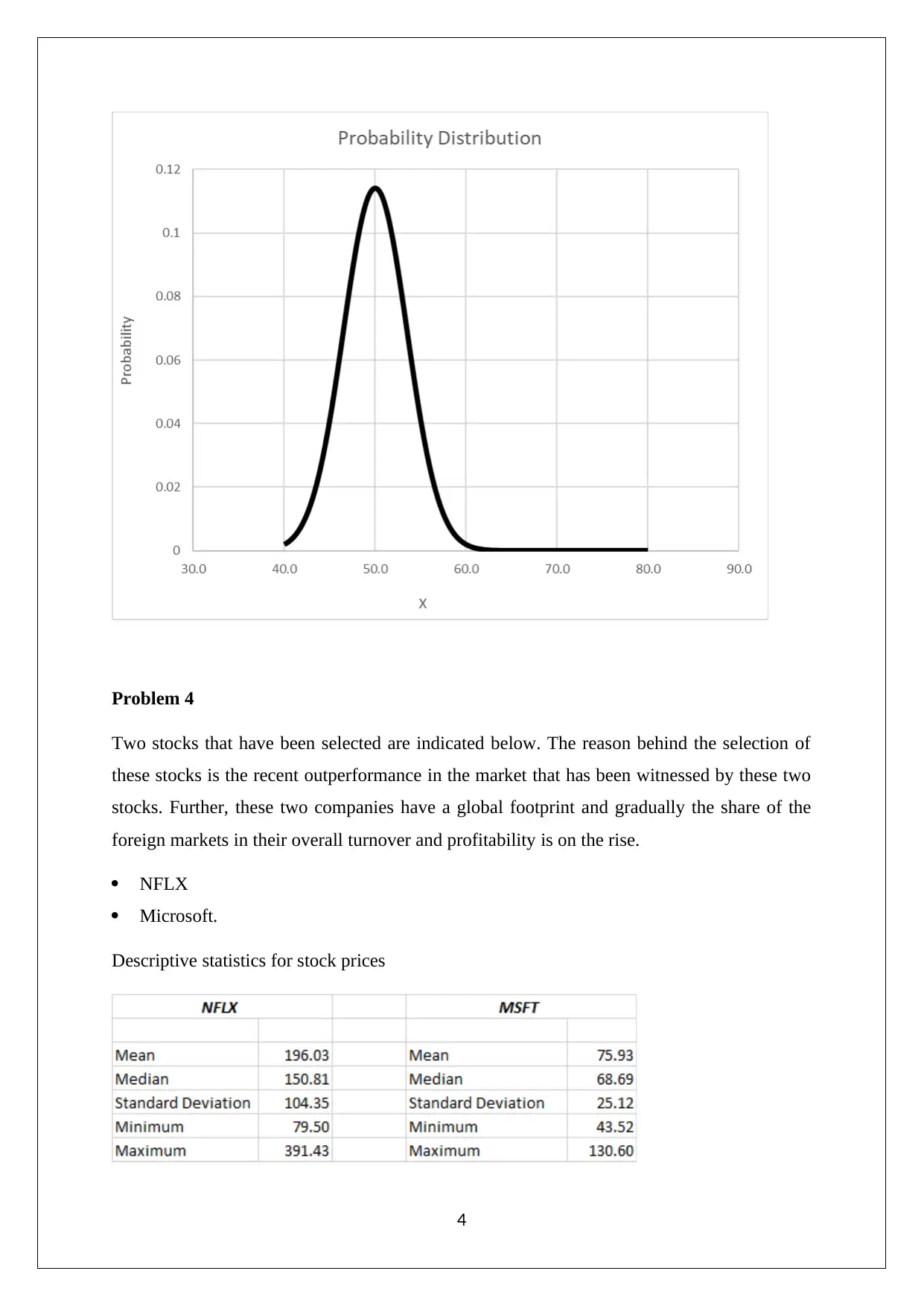
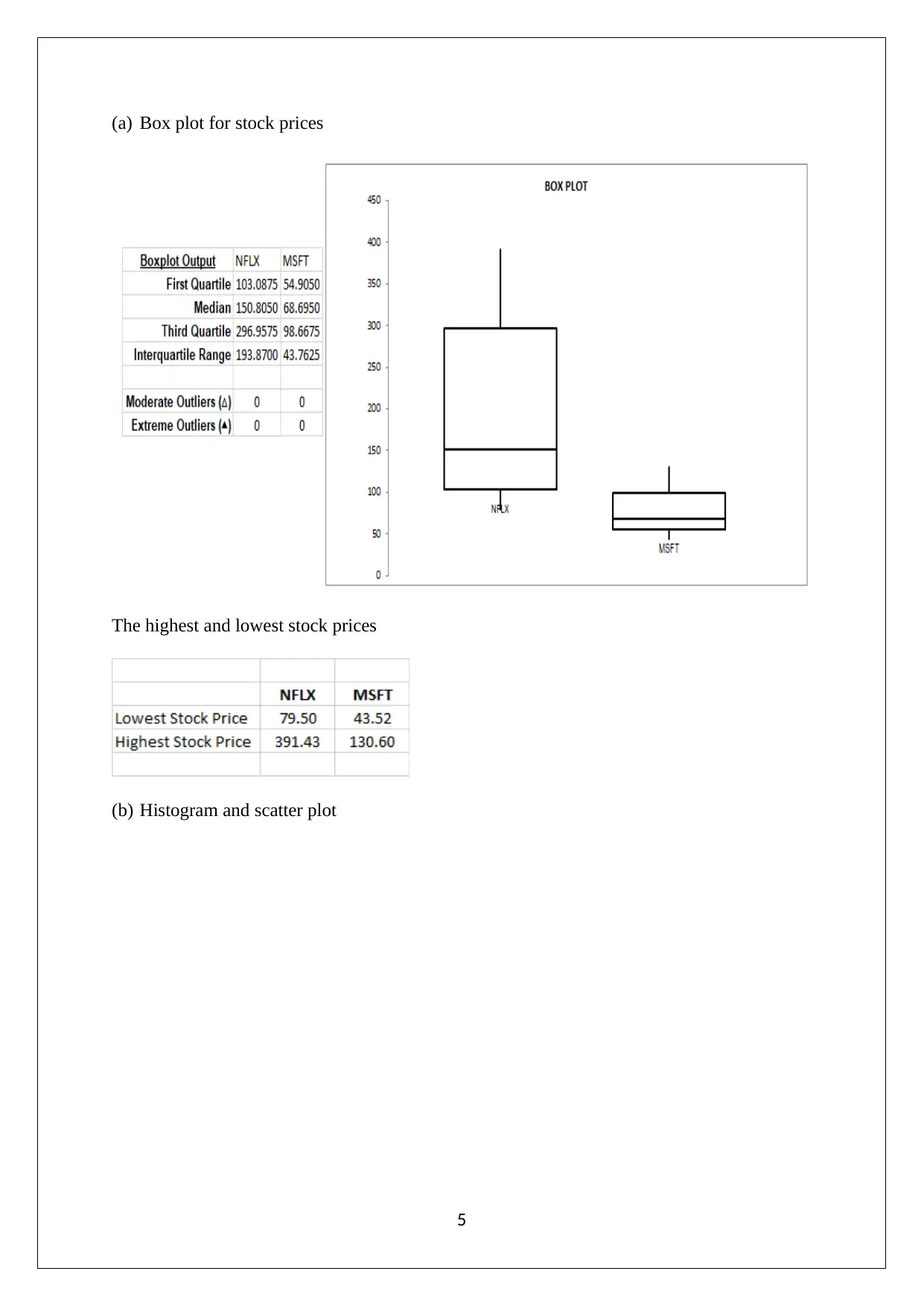
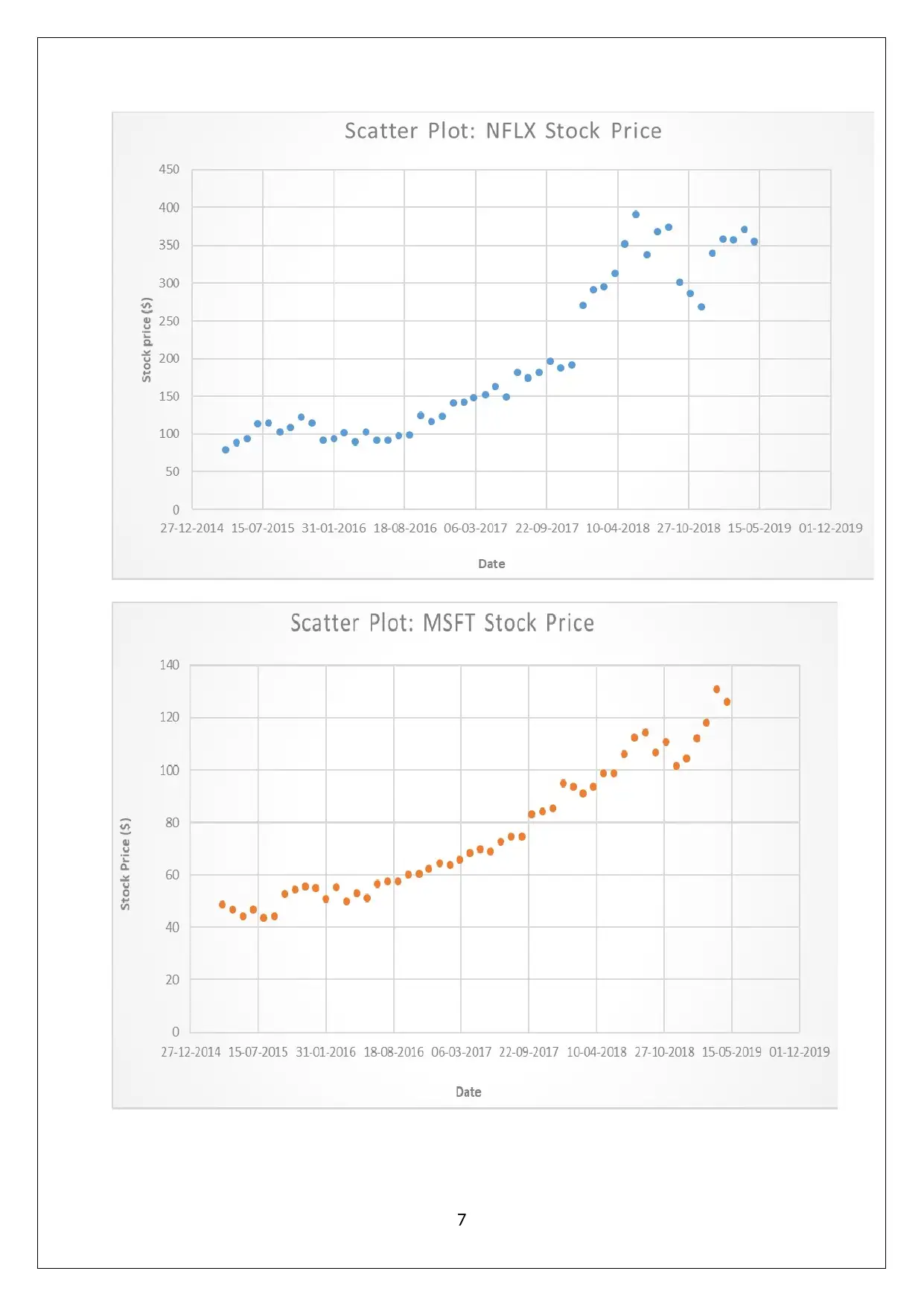
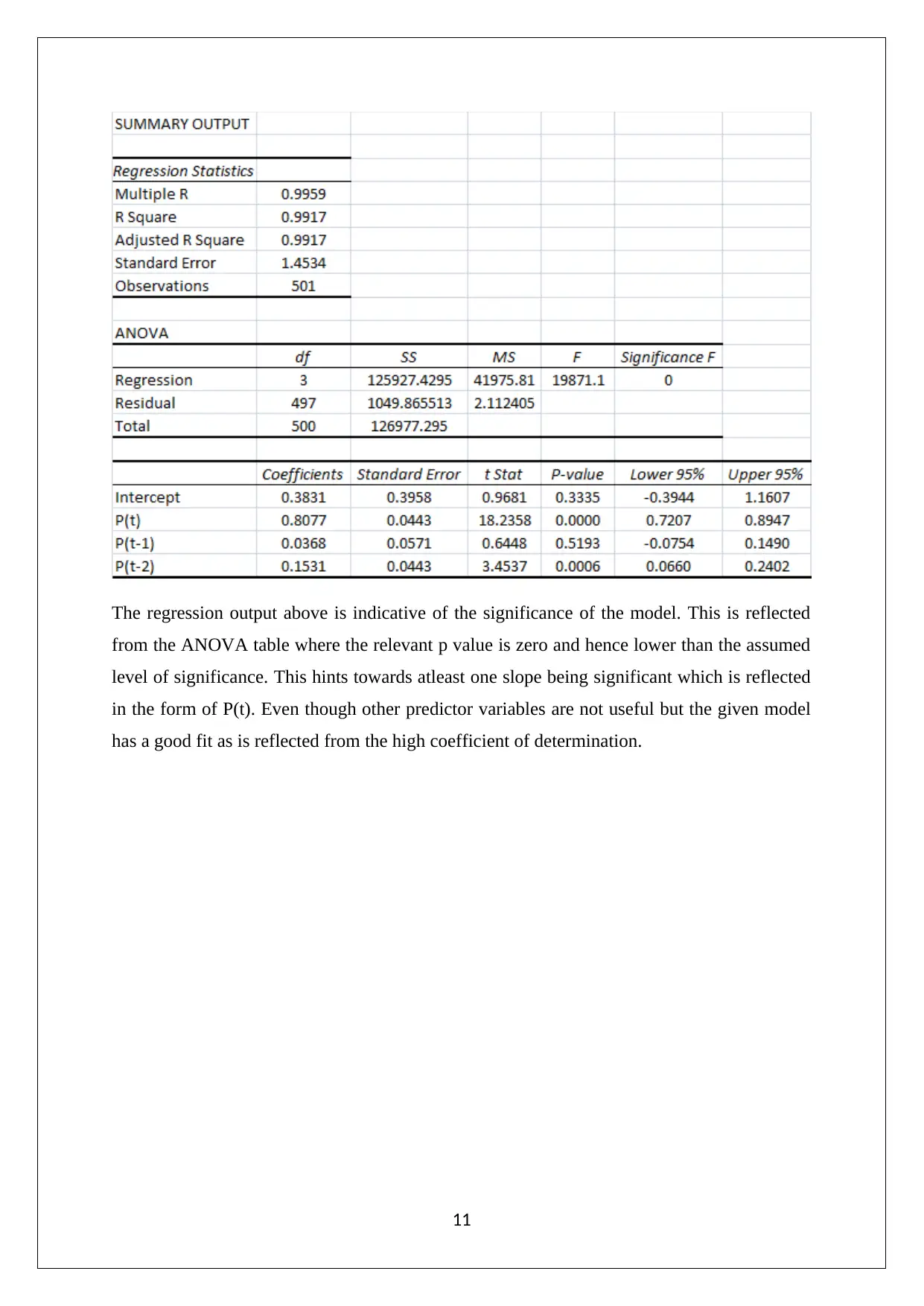
This data analysis project, completed for Pace University's Math 117 course, explores several statistical concepts. The project begins with an analysis of binomial distributions, calculating discrete and cumulative probabilities using Excel. It then moves on to normal distributions, creating a density probability plot. The project also examines historical trends and patterns in stock prices, specifically focusing on Netflix and Microsoft. It includes descriptive statistics, box plots, correlation analysis, and regression models to predict stock prices. Furthermore, the project involves hypothesis testing, including F-tests for variance and Jarque-Bera tests for normality. The final section conducts regression analysis on Microsoft stock prices to assess the reliability of future price predictions based on historical data.





1 out of 11
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.