Biostatistics Assignment: STROBE Review & Regression Analysis in R
VerifiedAdded on 2023/03/30
|5
|1169
|195
Homework Assignment
AI Summary
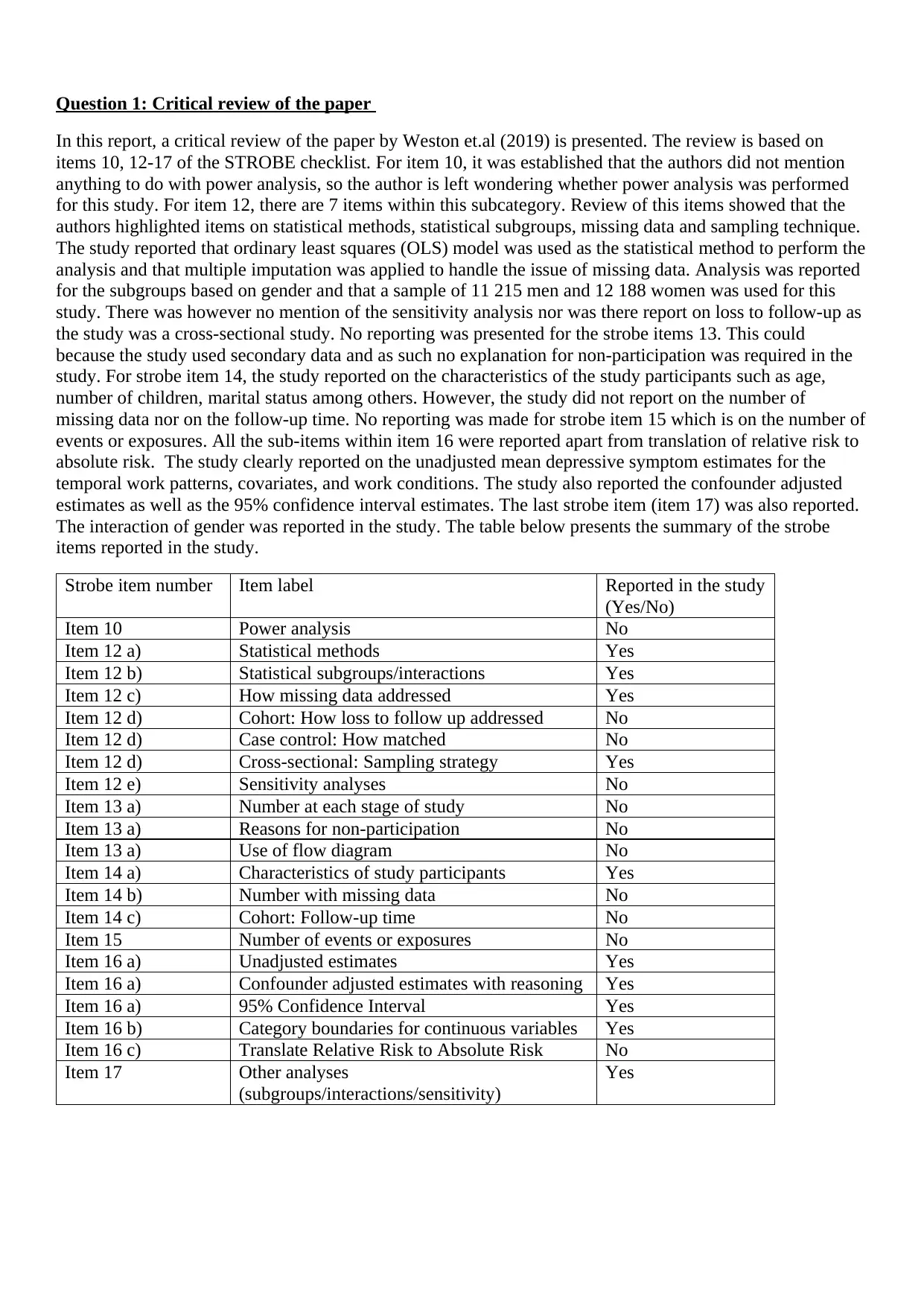
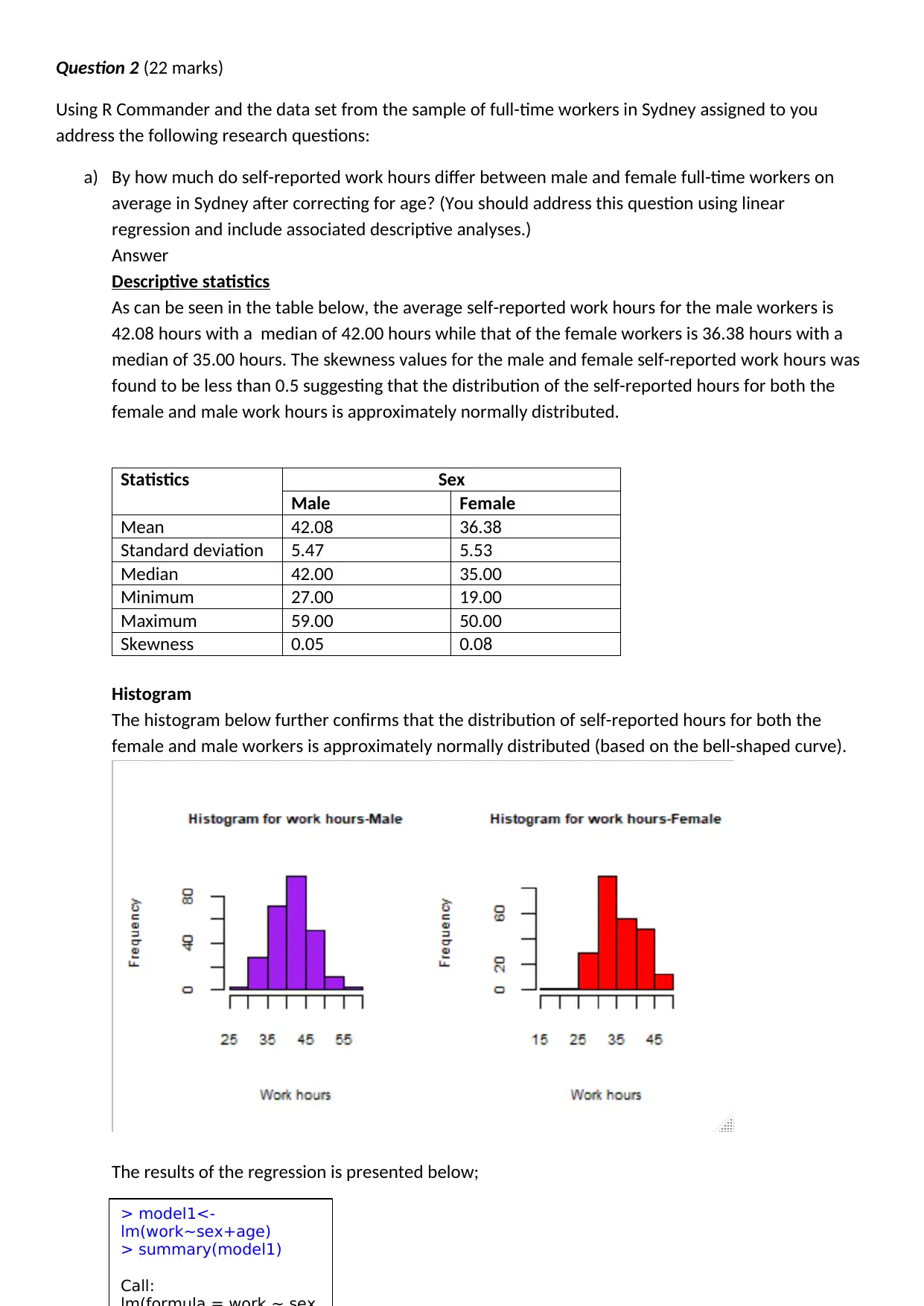
This biostatistics assignment solution includes a critical review of a research paper using selected items from the STROBE checklist, focusing on power analysis, statistical methods, handling of missing data, and reporting of results. It also involves a regression analysis using R Commander to investigate the difference in self-reported work hours between male and female full-time workers in Sydney, controlling for age. The solution provides descriptive statistics, histogram visualizations, regression model results with interpretation, and predictions of work hours for 25-year-old male and female workers, along with the R code used for the analysis. Desklib provides more such solved assignments and study resources for students.



1 out of 5
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.