Autumn 2018 Biostatistics 401077 Assignment 3: STROBE Checklist Review
VerifiedAdded on 2023/06/03
|13
|2255
|313
Homework Assignment
AI Summary
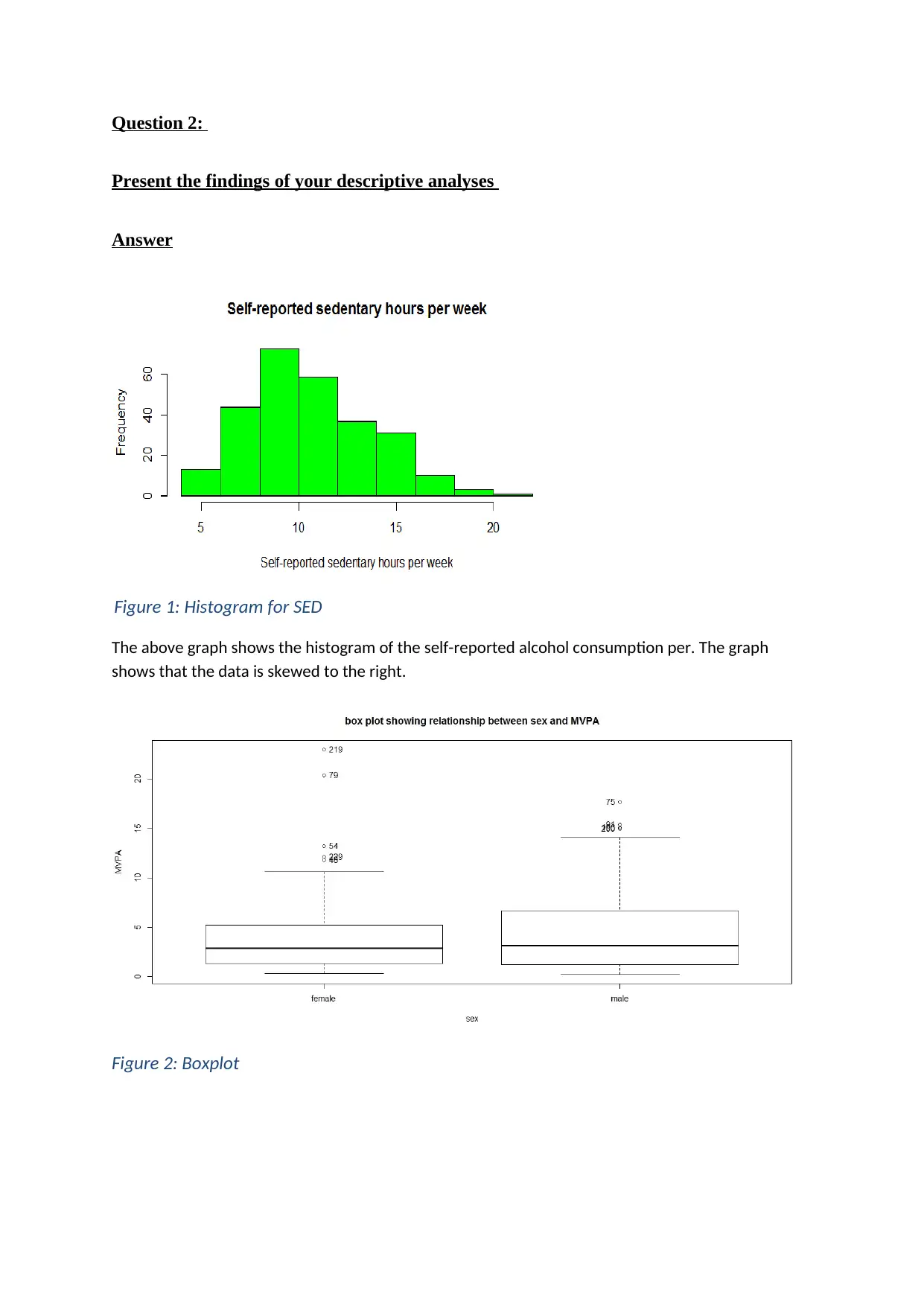
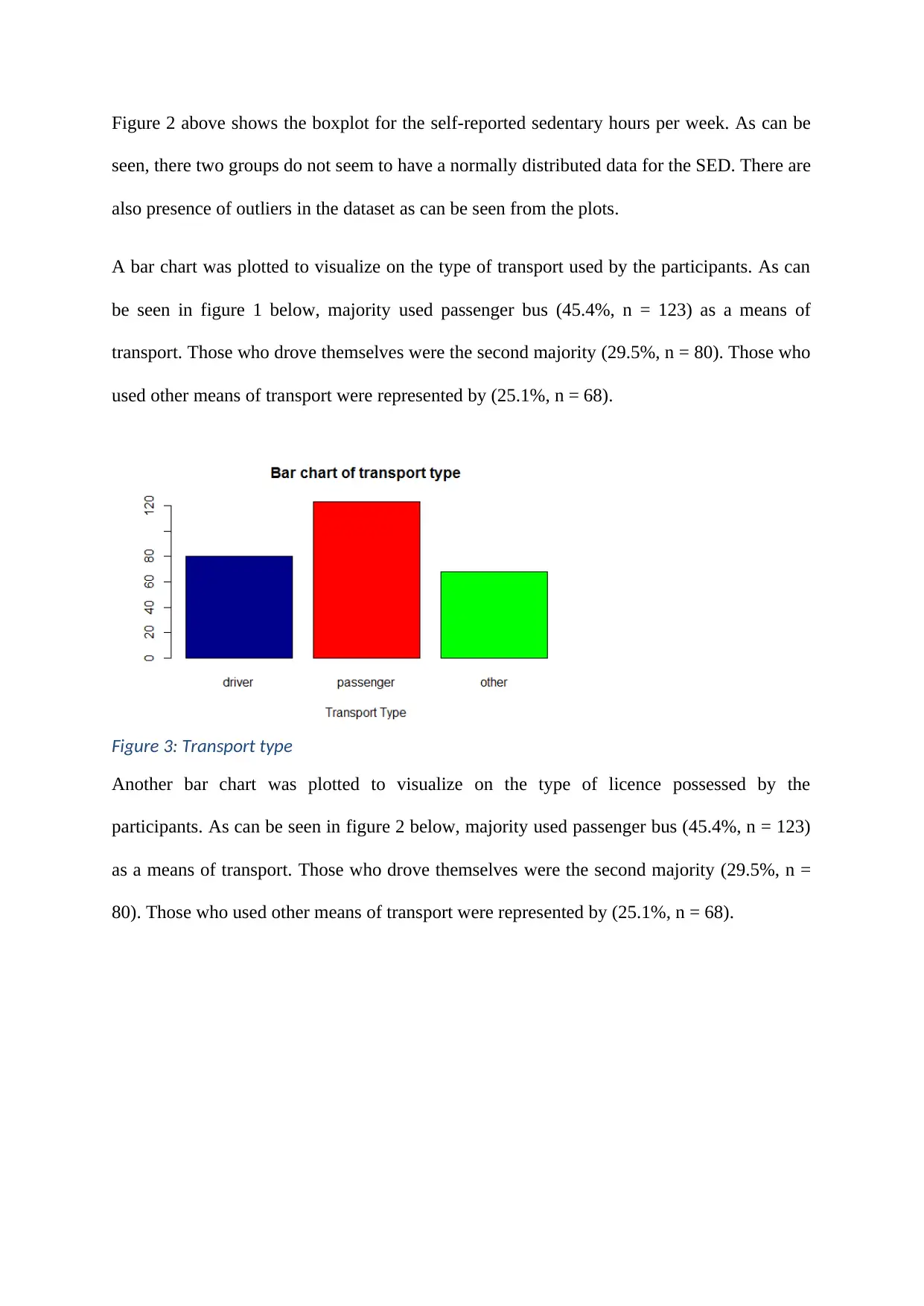
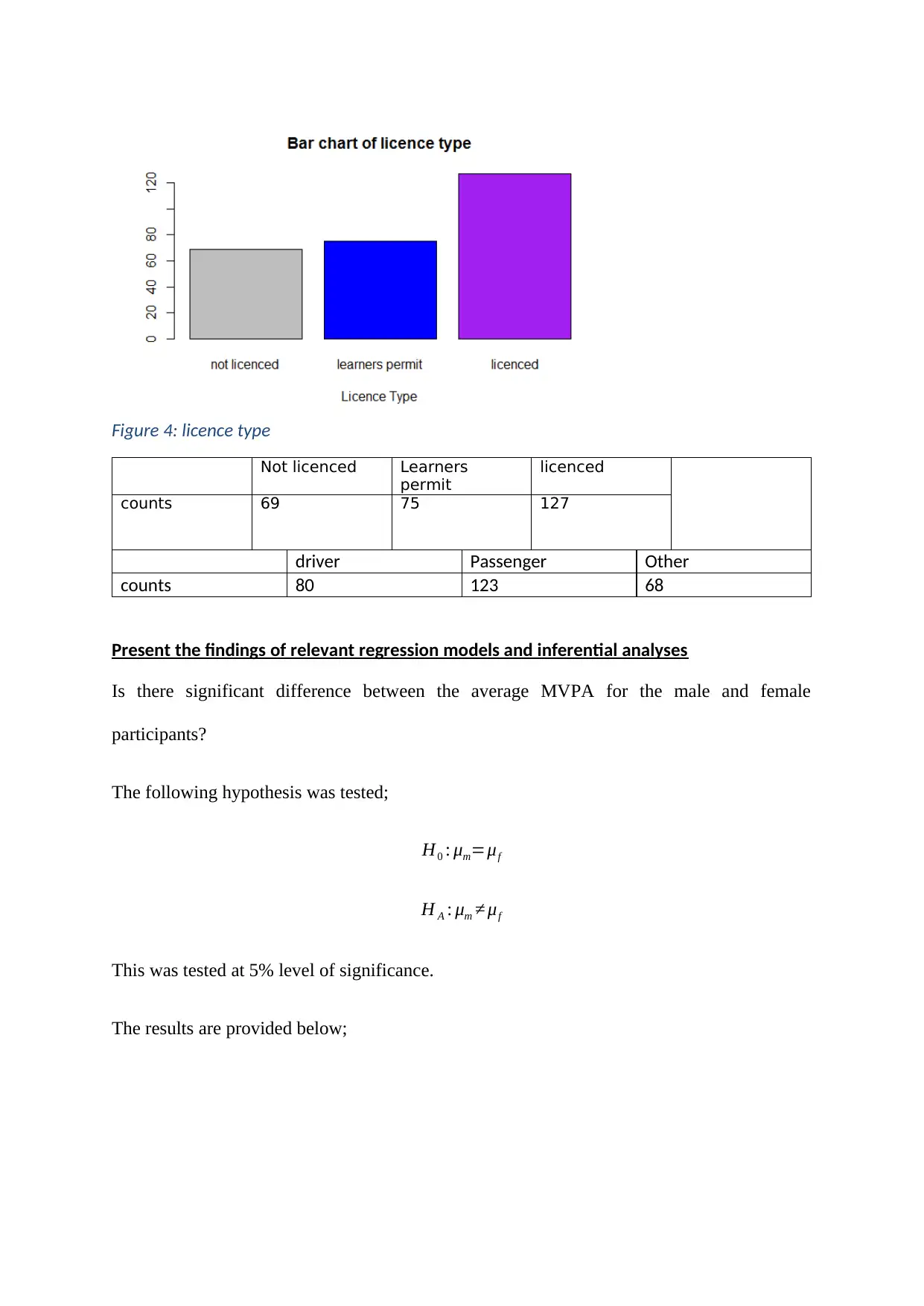
This document presents a comprehensive solution to a biostatistics assignment, focusing on a critical appraisal of a research paper using the STROBE checklist. The assignment involves a 400-500 word report evaluating the statistical material in the paper against items 10, 12-17 of the STROBE checklist. The student analyzed the paper's adherence to the checklist, highlighting strengths and weaknesses in the documentation of statistical methods. The assignment also includes descriptive analyses, such as histograms and boxplots, and inferential analyses, including t-tests and regression models, to address research questions related to the mean MVPA of male and female participants and the factors influencing logMVPA. The results revealed no significant difference in mean MVPA between genders, but found that self-reported sedentary hours significantly influenced logMVPA. The document includes the student's analysis, findings, and interpretations, along with relevant code and output from statistical software.









1 out of 13
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.