Biostatistics Assignment: Analysis of Income and Education Data
VerifiedAdded on 2023/01/03
|8
|1676
|41
Homework Assignment
AI Summary
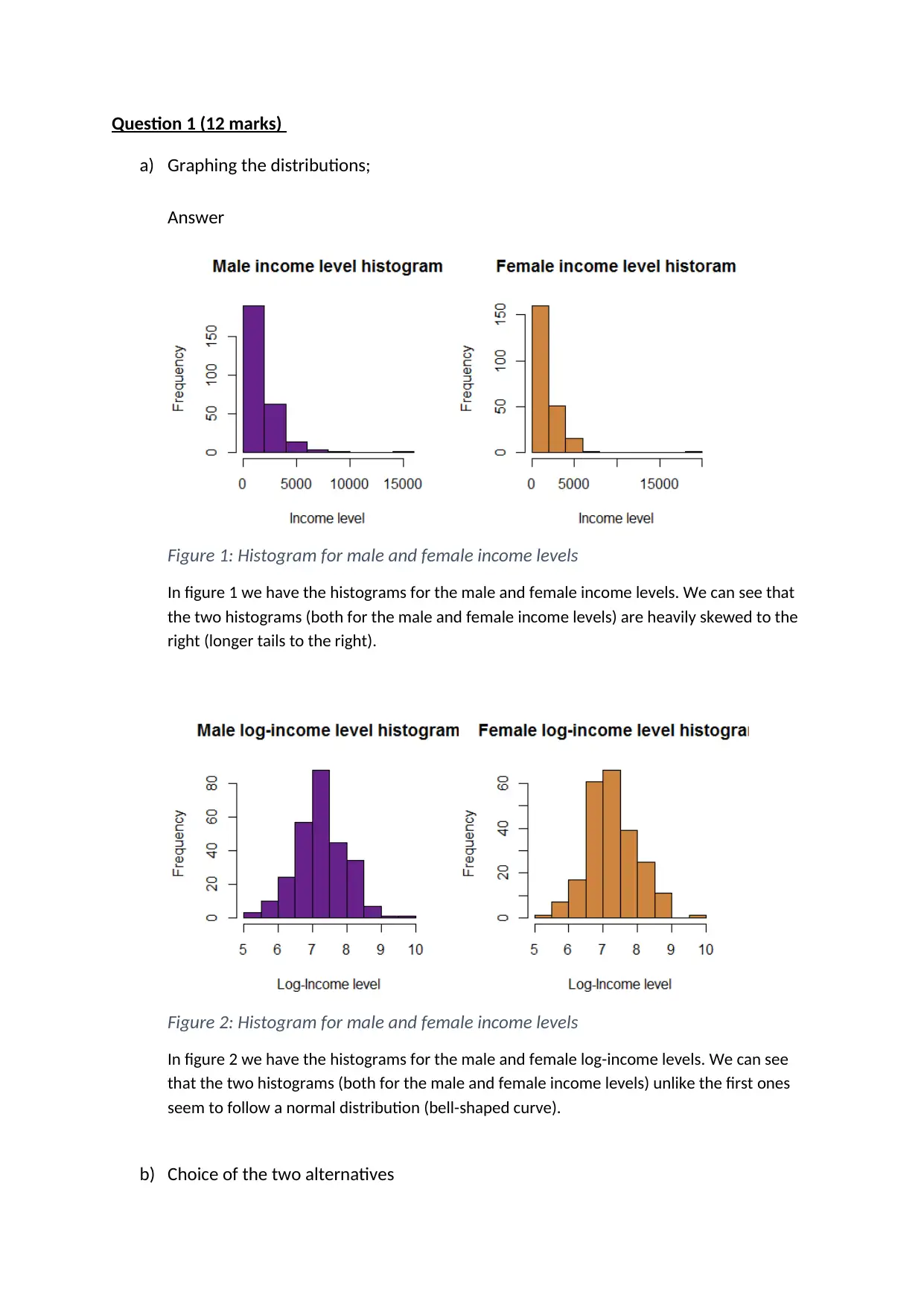
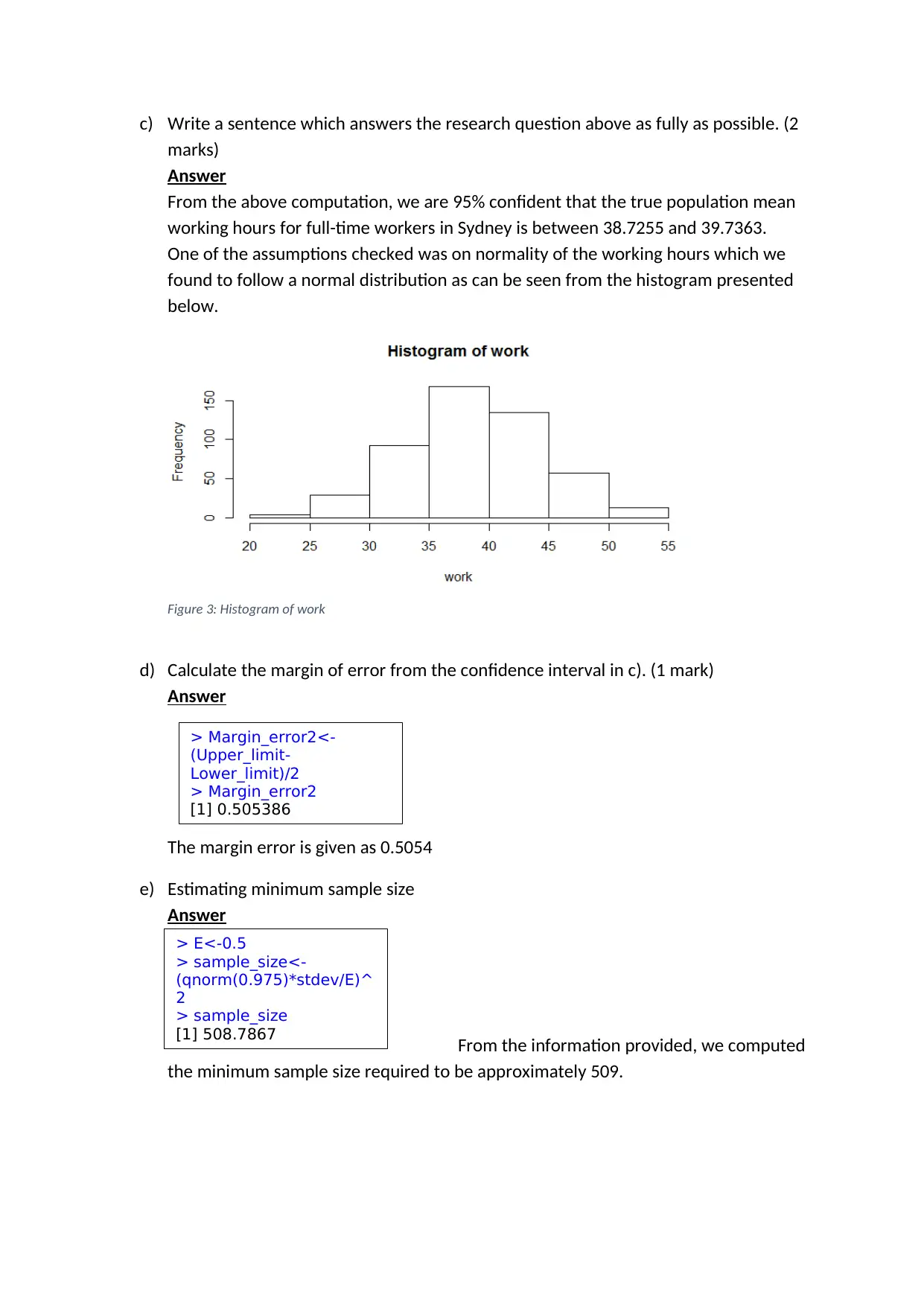
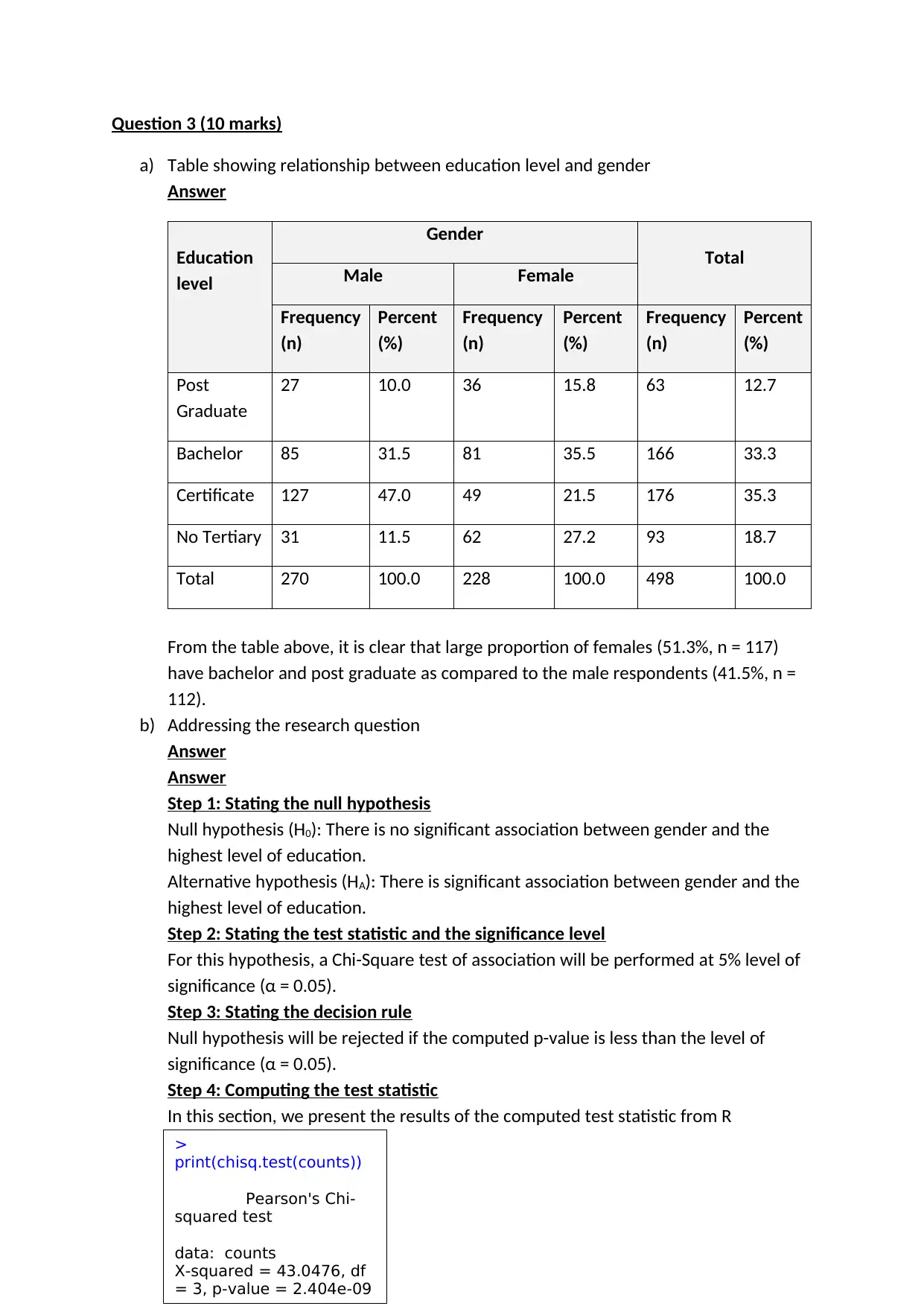
This biostatistics assignment analyzes a dataset related to income, education, and gender. The assignment includes several questions that require the application of statistical methods. Question 1 focuses on comparing income levels between males and females using t-tests and non-parametric tests, including the construction of histograms to assess data distribution. Question 2 involves calculating descriptive statistics, constructing confidence intervals, and determining the required sample size. Finally, Question 3 explores the relationship between education level and gender using a chi-square test, including the calculation of proportions and sample size requirements. The solution includes the presentation of results, hypothesis testing, and the interpretation of statistical outputs from R programming, along with the necessary R code used for the analysis. This assignment assesses the student's ability to apply statistical concepts to real-world data and draw meaningful conclusions.





1 out of 8
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.