Statistical Analysis of Weight, Exercise, and Gender Data - 2017
VerifiedAdded on 2020/04/07
|18
|4561
|39
Homework Assignment
AI Summary
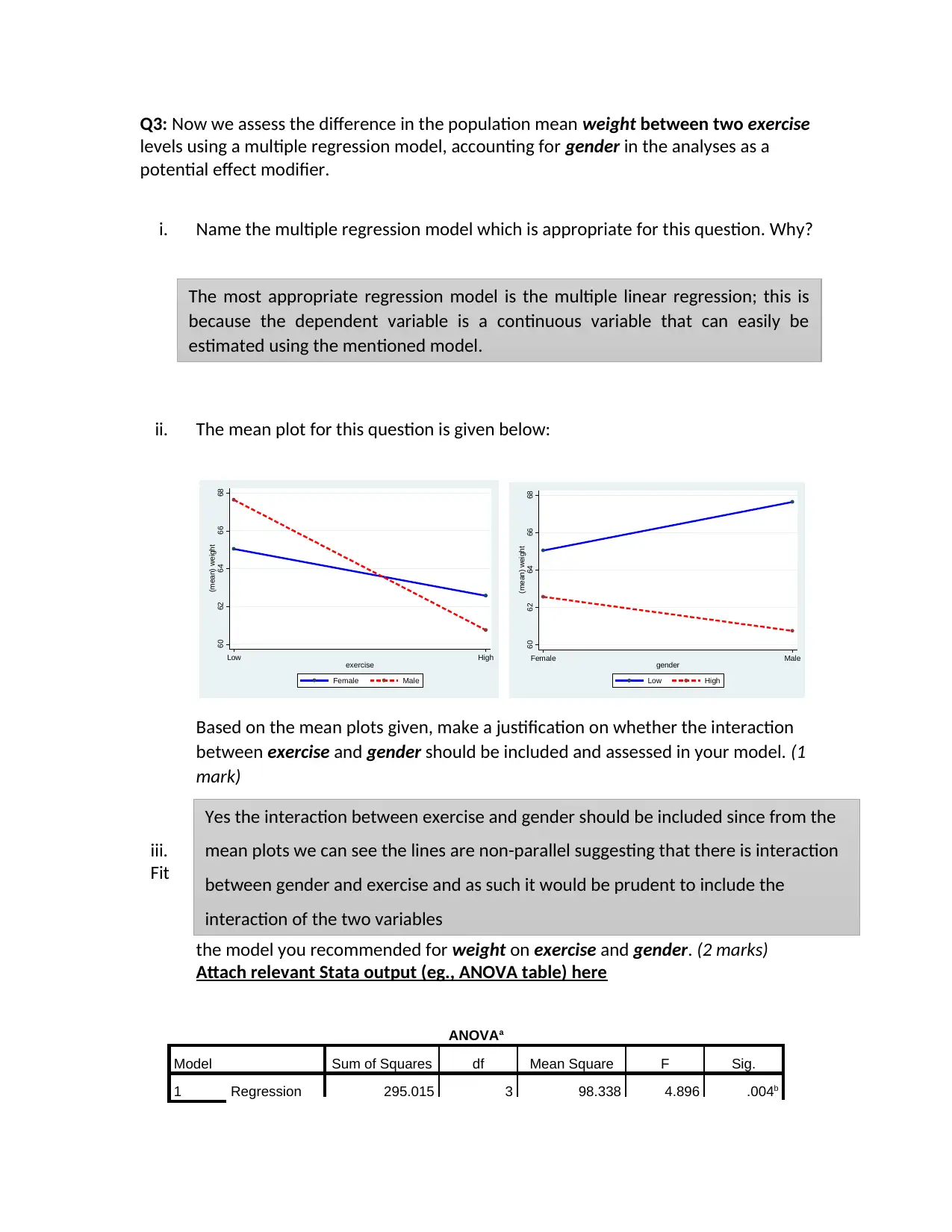
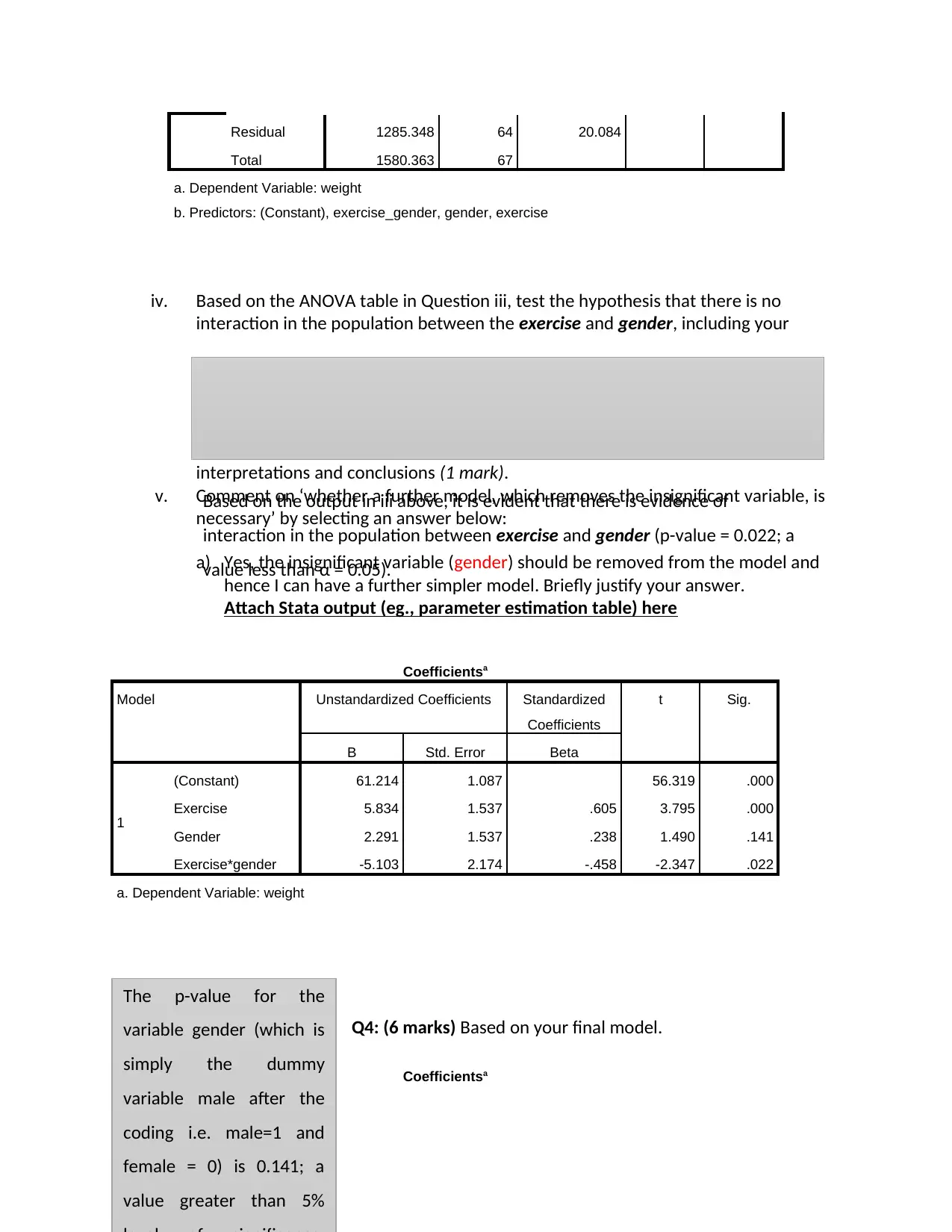
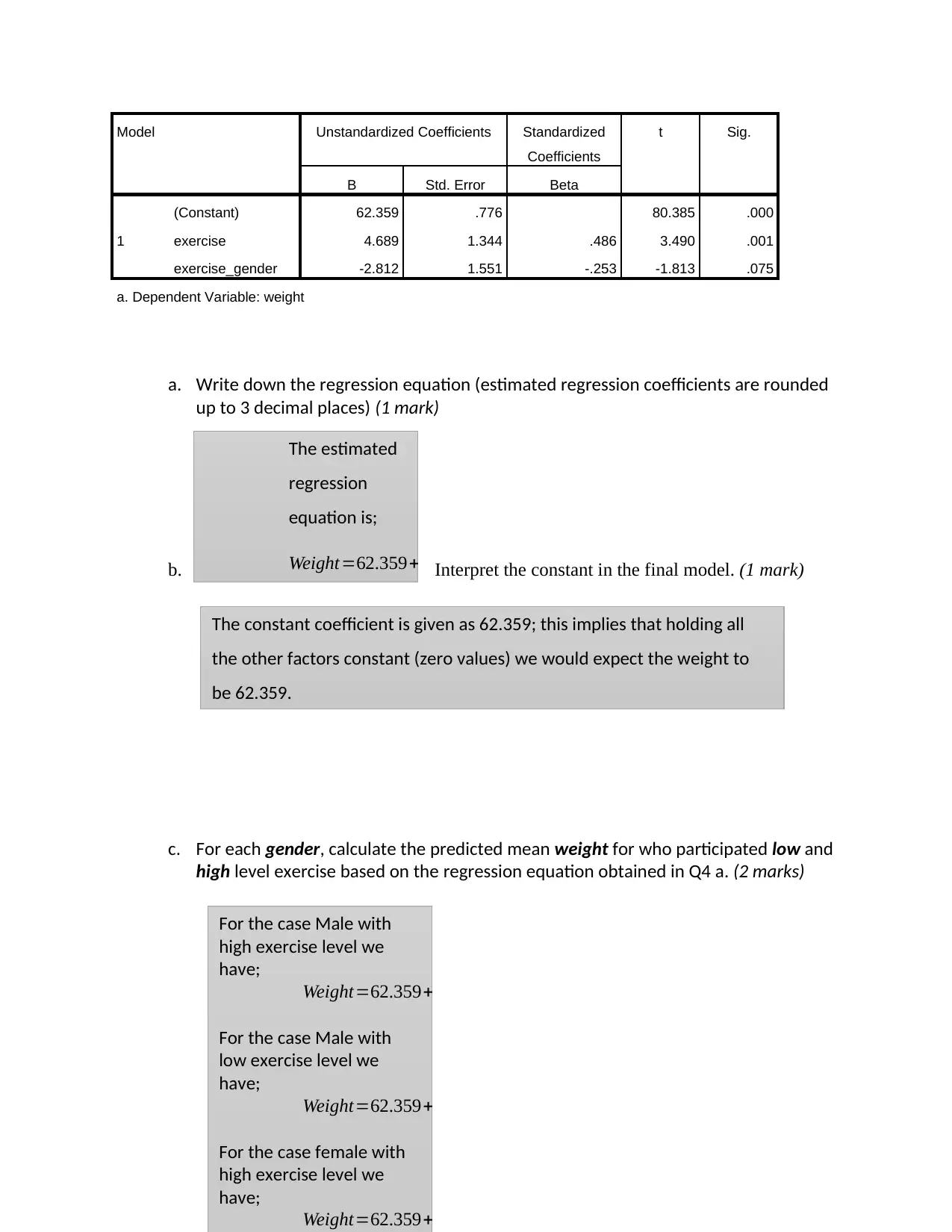
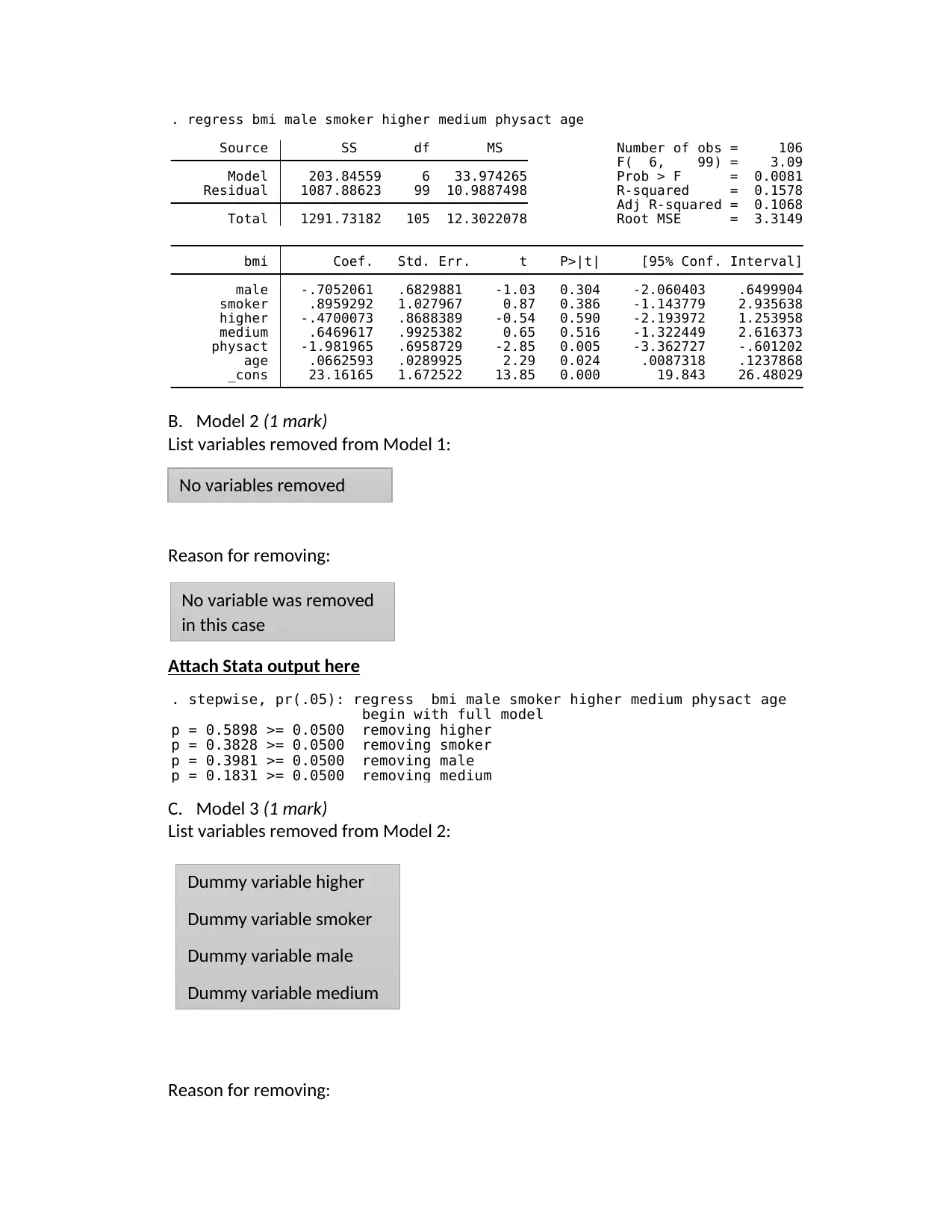
This biostatistics assignment presents a comprehensive analysis of weight data, exploring the relationships between weight, exercise levels, and gender. The assignment begins with descriptive statistics, comparing the mean weights of males and females at low and high exercise levels. It then tests the hypothesis that population mean weight is the same regardless of exercise levels using an independent samples t-test, followed by a multiple regression model to assess the influence of exercise and gender on weight, including interaction effects. The student justifies the inclusion of an interaction term based on mean plots and tests for its significance using ANOVA. Furthermore, the assignment involves model interpretation, including the regression equation and interpretation of coefficients, and calculations of predicted mean weights for different gender and exercise level combinations. Finally, the assignment investigates the relationship between BMI and age using correlation, and the association between BMI and categorical variables like gender, physical activity, and socioeconomic status using t-tests and ANOVA, providing conclusions based on statistical outputs.







1 out of 18
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.