Deakin University SIT773 Project: Inverted Index and Search Engines
VerifiedAdded on 2020/05/16
|11
|1099
|288
Project
AI Summary
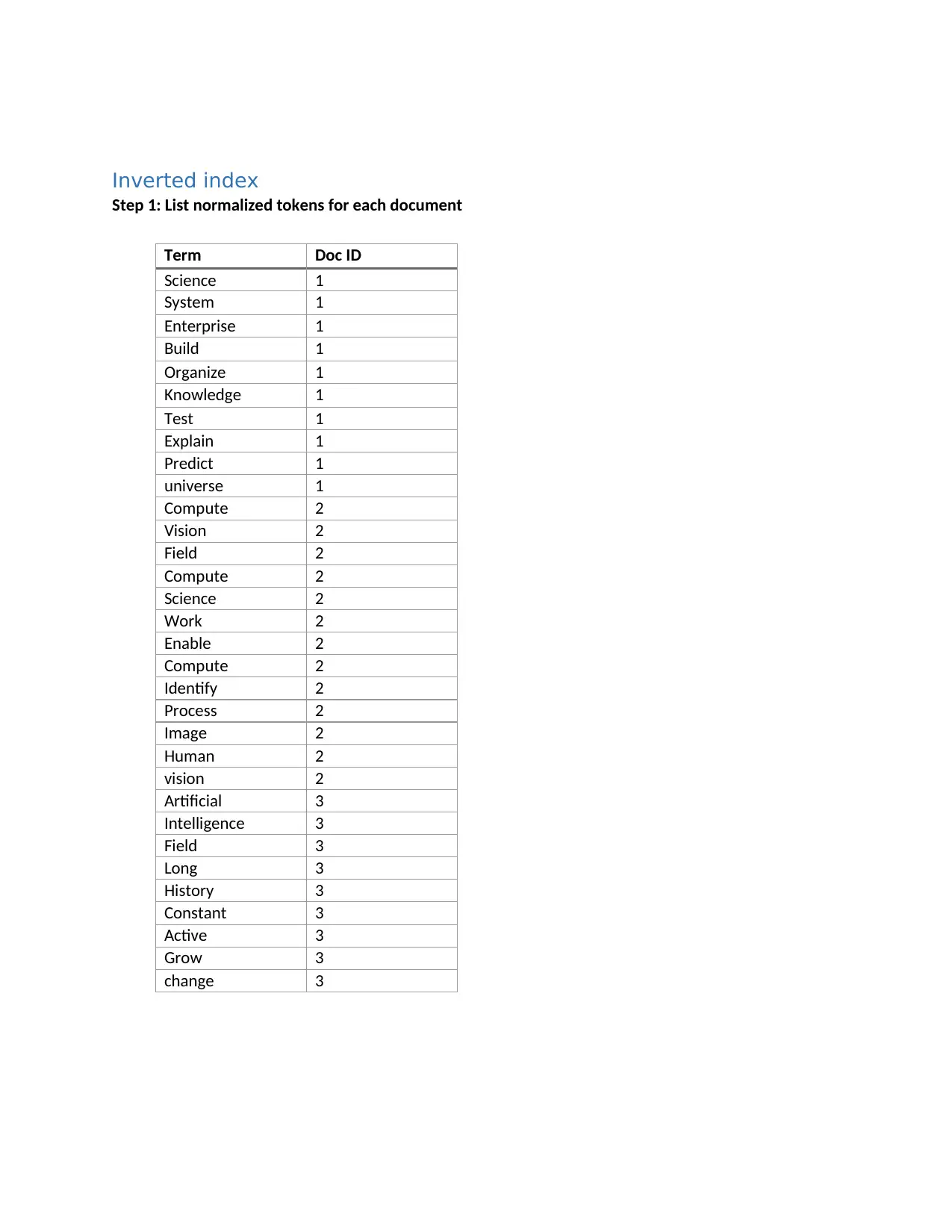
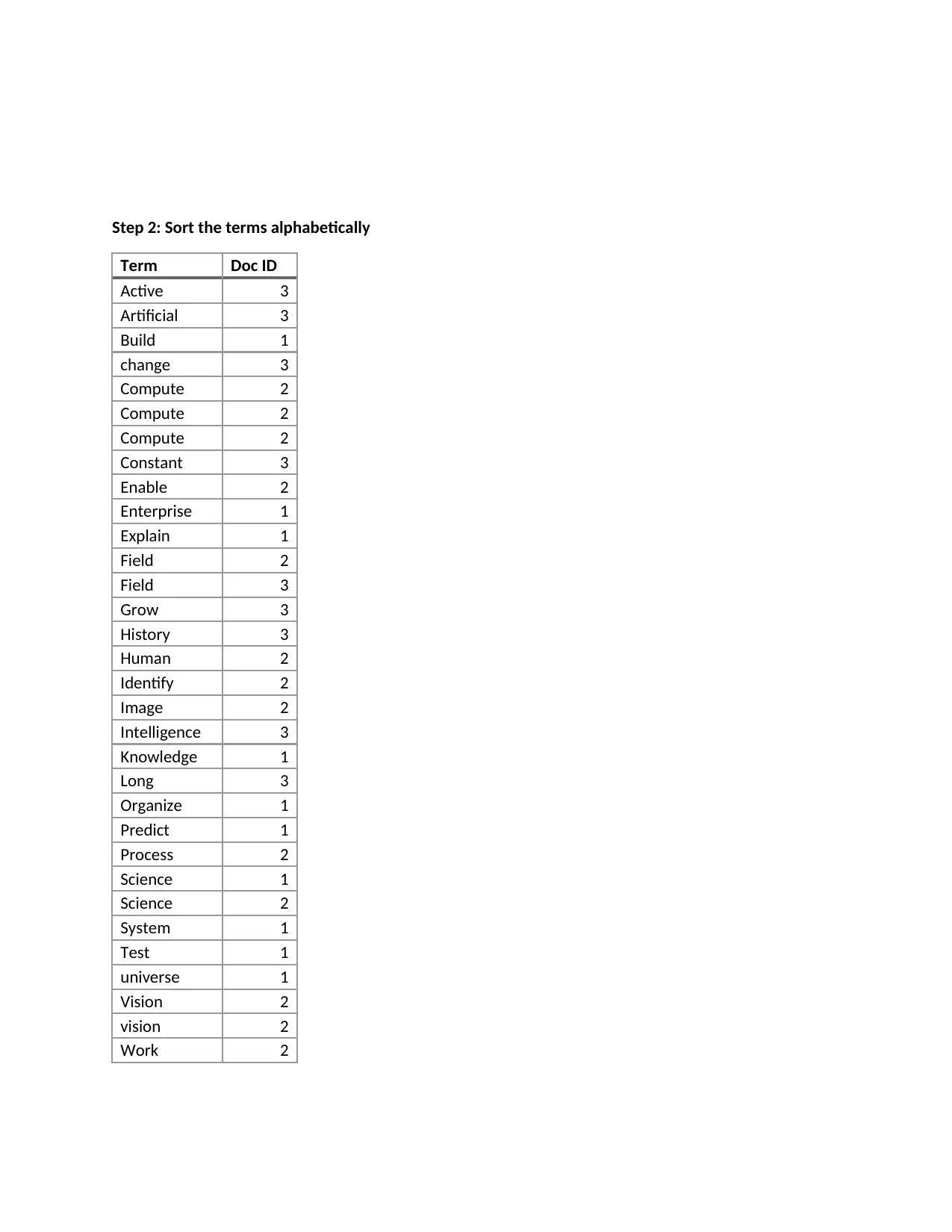
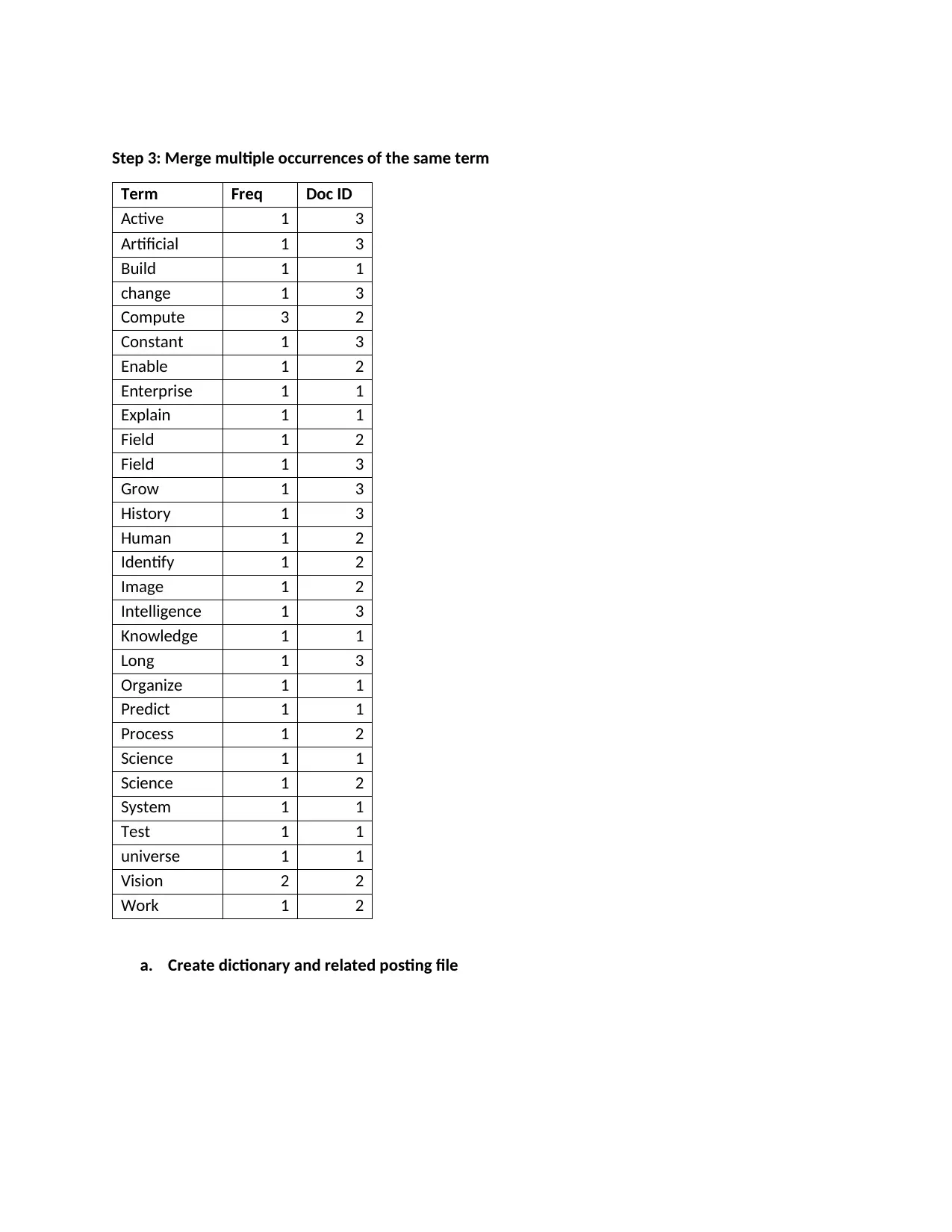
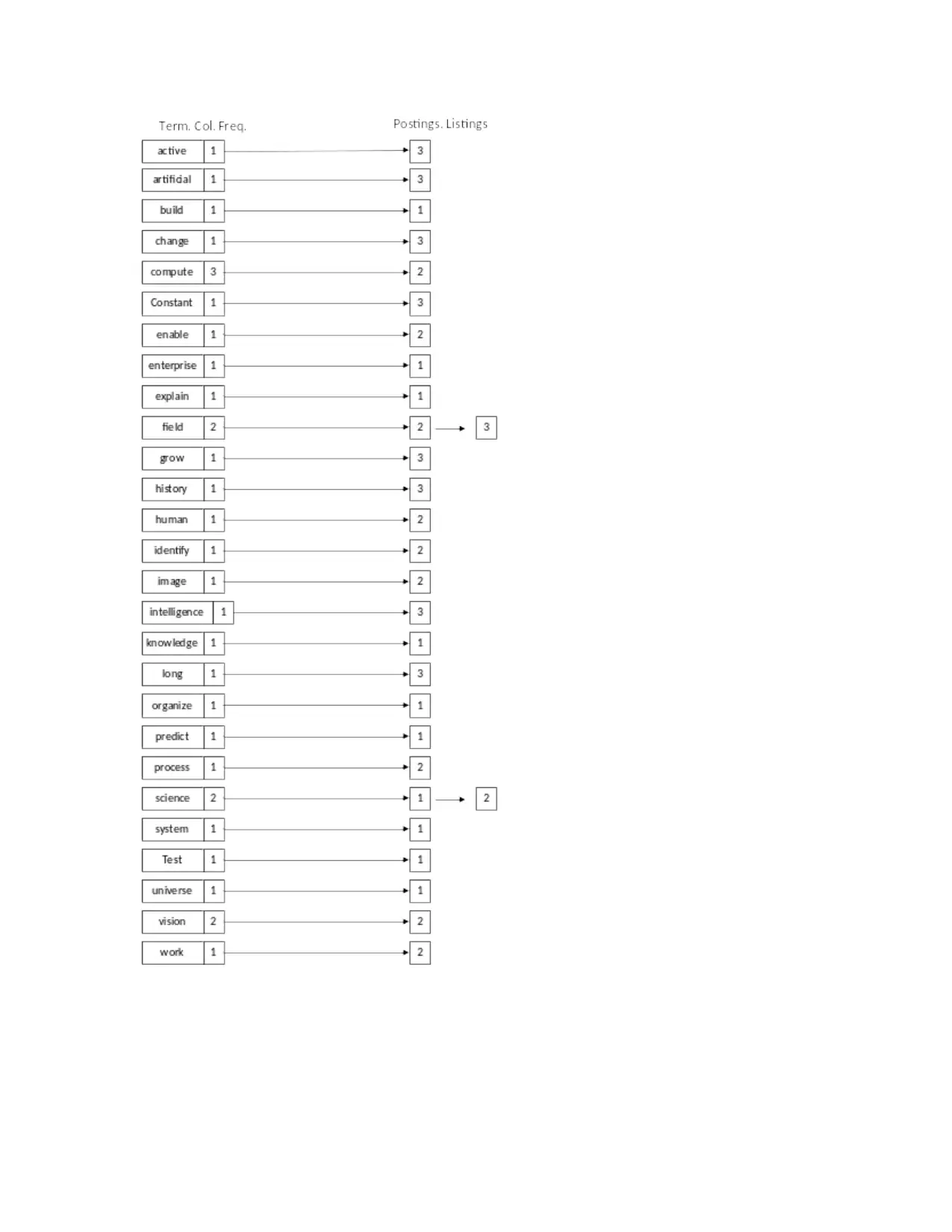
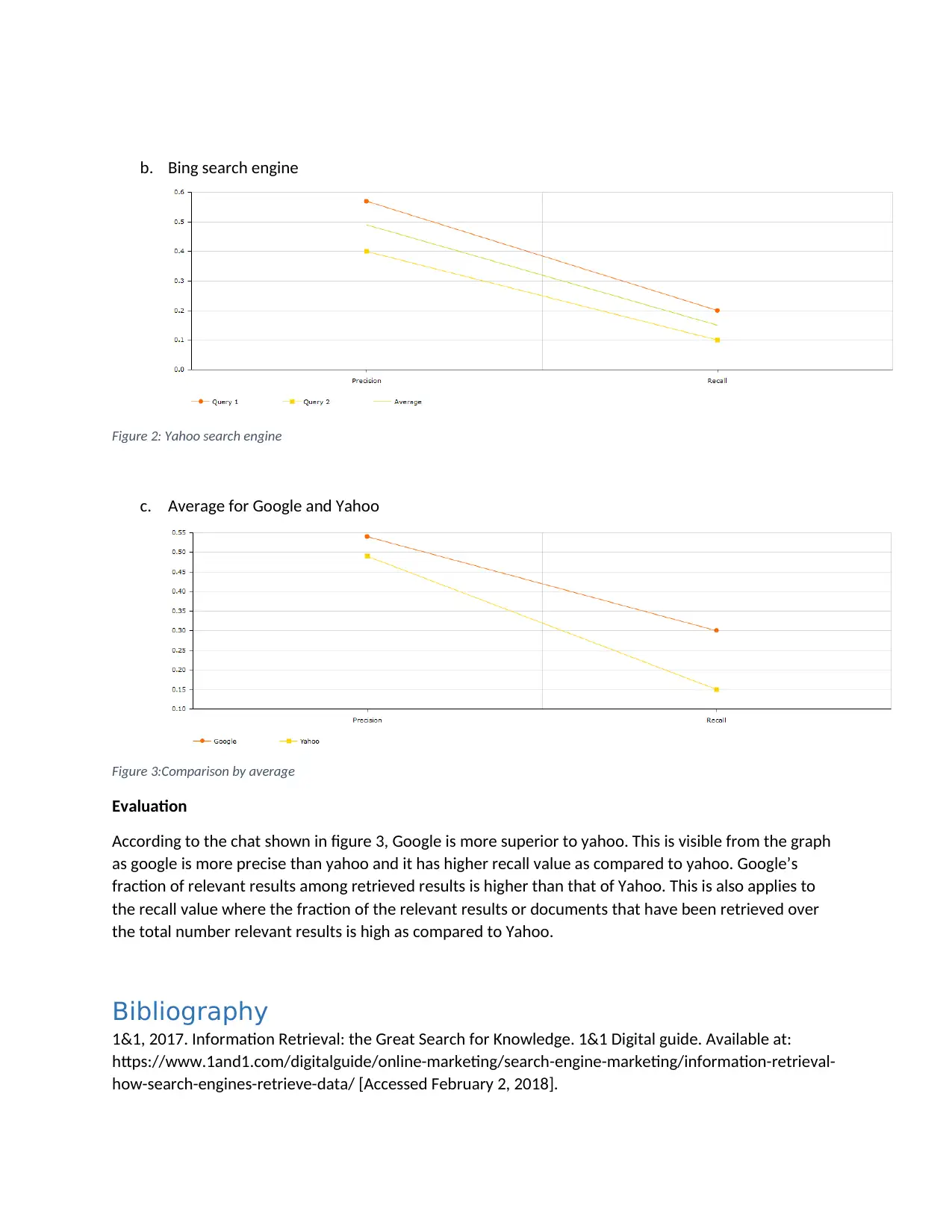
This project delves into the concepts of information retrieval, focusing on the creation of an inverted index from three documents related to science, computer vision, and artificial intelligence. It details the process of stop word elimination and the application of the Porter stemming algorithm to normalize the text. The project then constructs the inverted index, listing normalized tokens and their corresponding document IDs. The analysis extends to Boolean and vector queries, demonstrating their application and comparing their functionalities. The project also evaluates the performance of Google and Yahoo search engines using specific queries, assessing their precision and recall. The evaluation includes the comparison of the search engines' average performance, concluding with a bibliography of the resources used.





1 out of 11
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.