Building and Evaluating Predictive Models: BUS5PA Assignment 2 Report
VerifiedAdded on 2022/09/28
|8
|1405
|30
Report
AI Summary
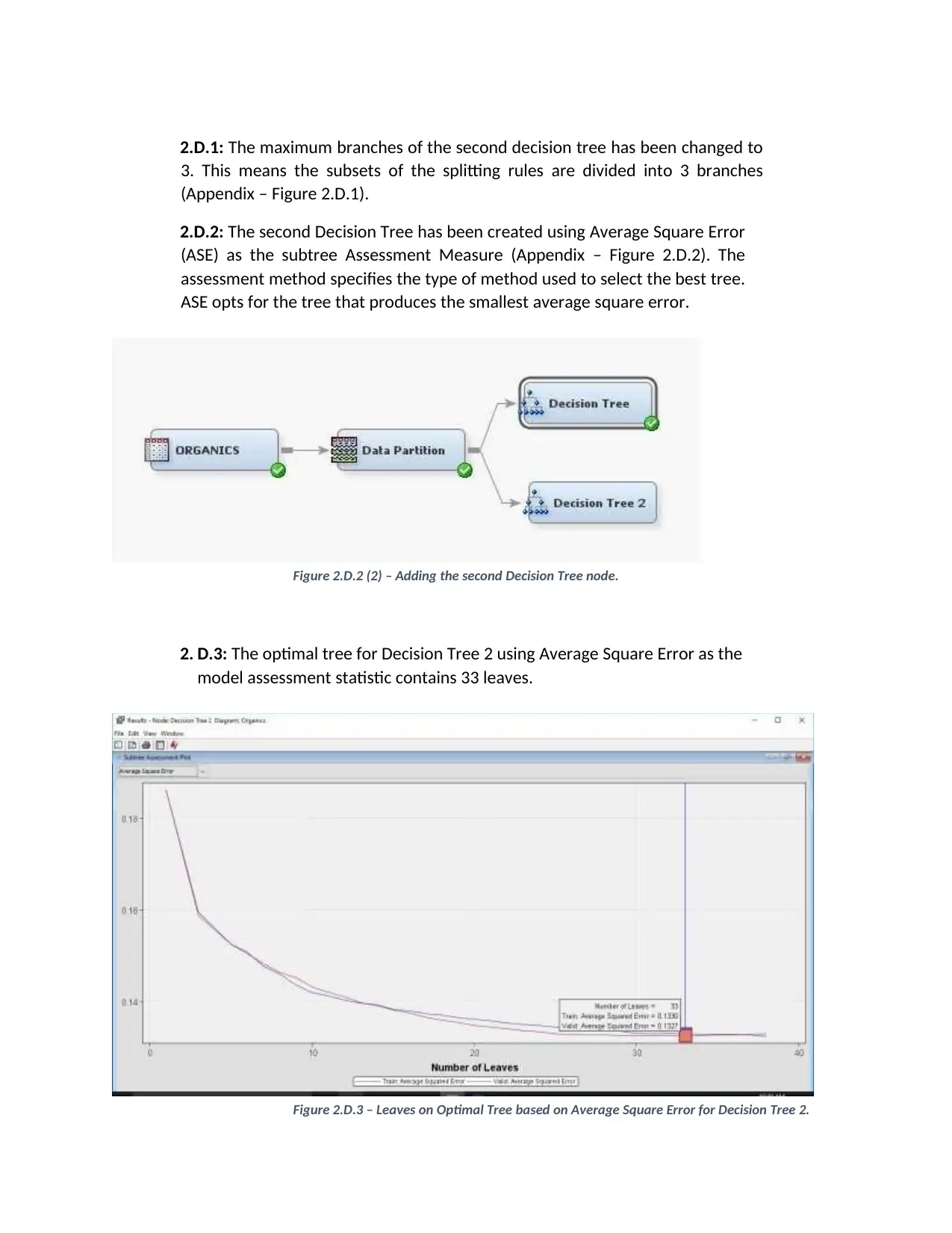
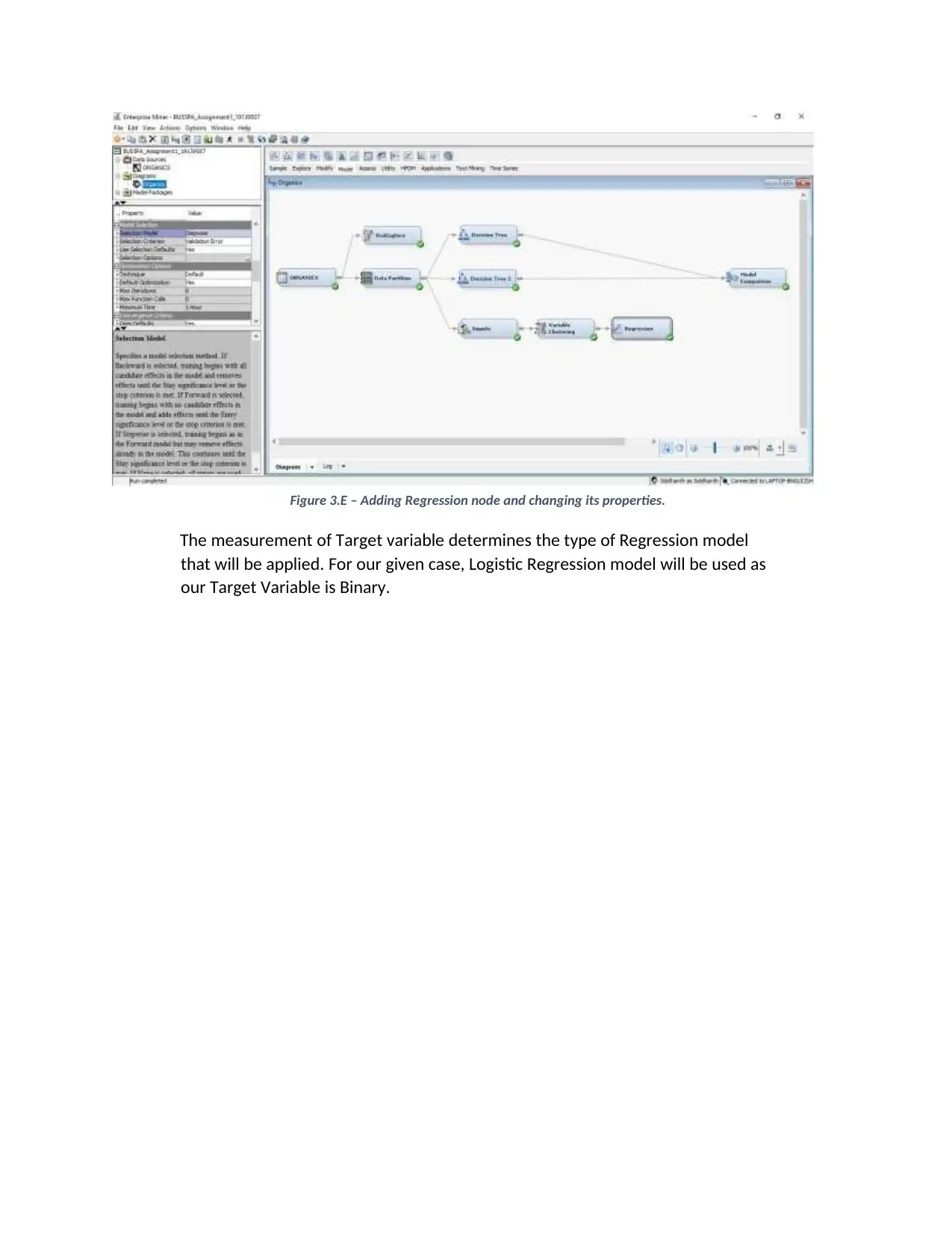
This report details a student's approach to a predictive analysis assignment (BUS5PA) using SAS Enterprise Miner. The assignment focuses on building and evaluating predictive models for target marketing, leveraging a customer purchase dataset. The solution encompasses the creation of decision tree and regression models. The report outlines the steps involved, including data partitioning, model building with different parameters (e.g., maximum branches, assessment measures), and model comparison based on average square error. The analysis also includes handling missing values through imputation and variable clustering to optimize the regression model. The student demonstrates practical application of predictive modeling techniques and interprets the results to identify customers likely to purchase new clothing lines. The report provides a comprehensive overview of the modeling process, including the selection of variables, model evaluation metrics, and the interpretation of model outputs to derive actionable insights for the business case.






1 out of 8
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.