BUS5SBF Statistics for Business: Household Data Analysis Report
VerifiedAdded on 2023/06/12
|12
|1615
|87
Report
AI Summary
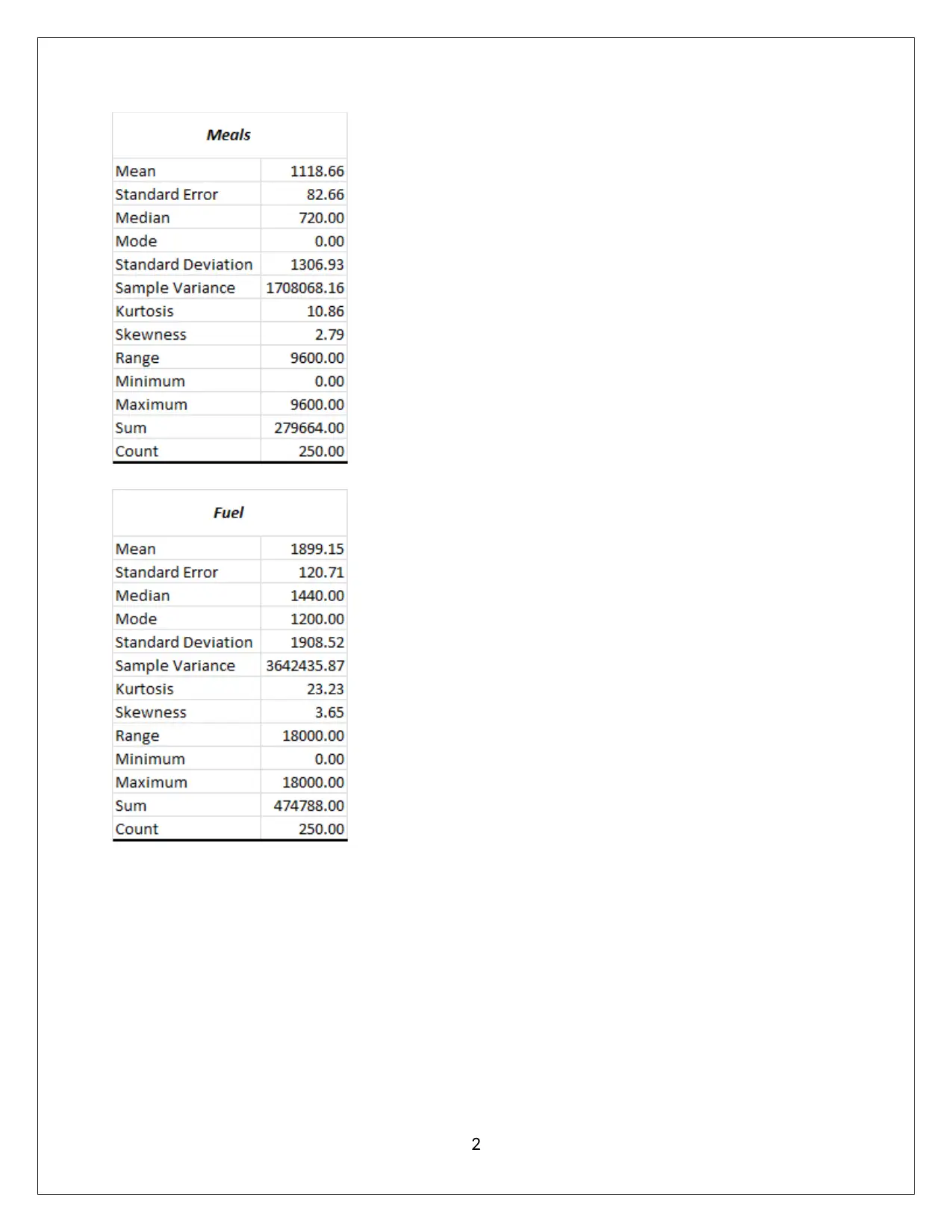
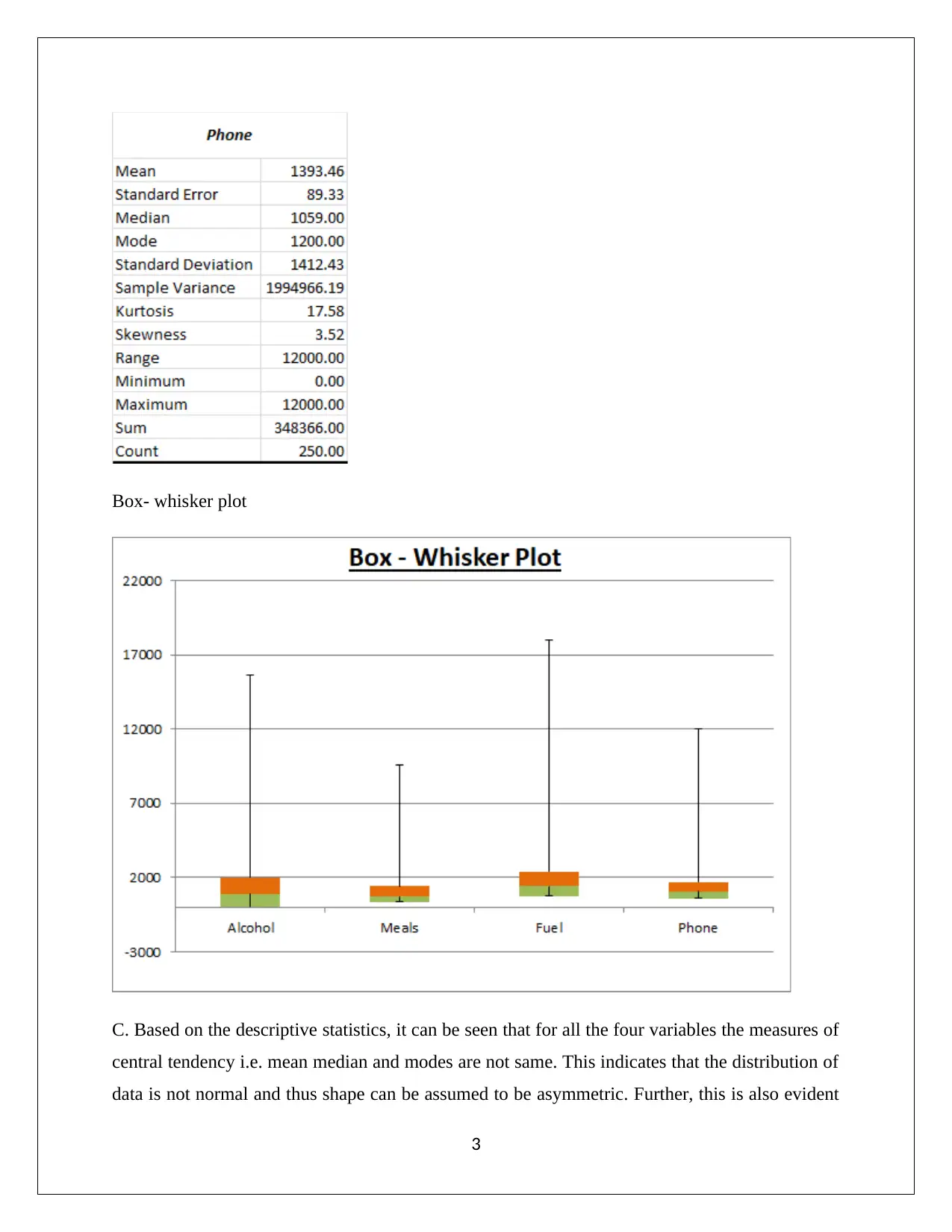
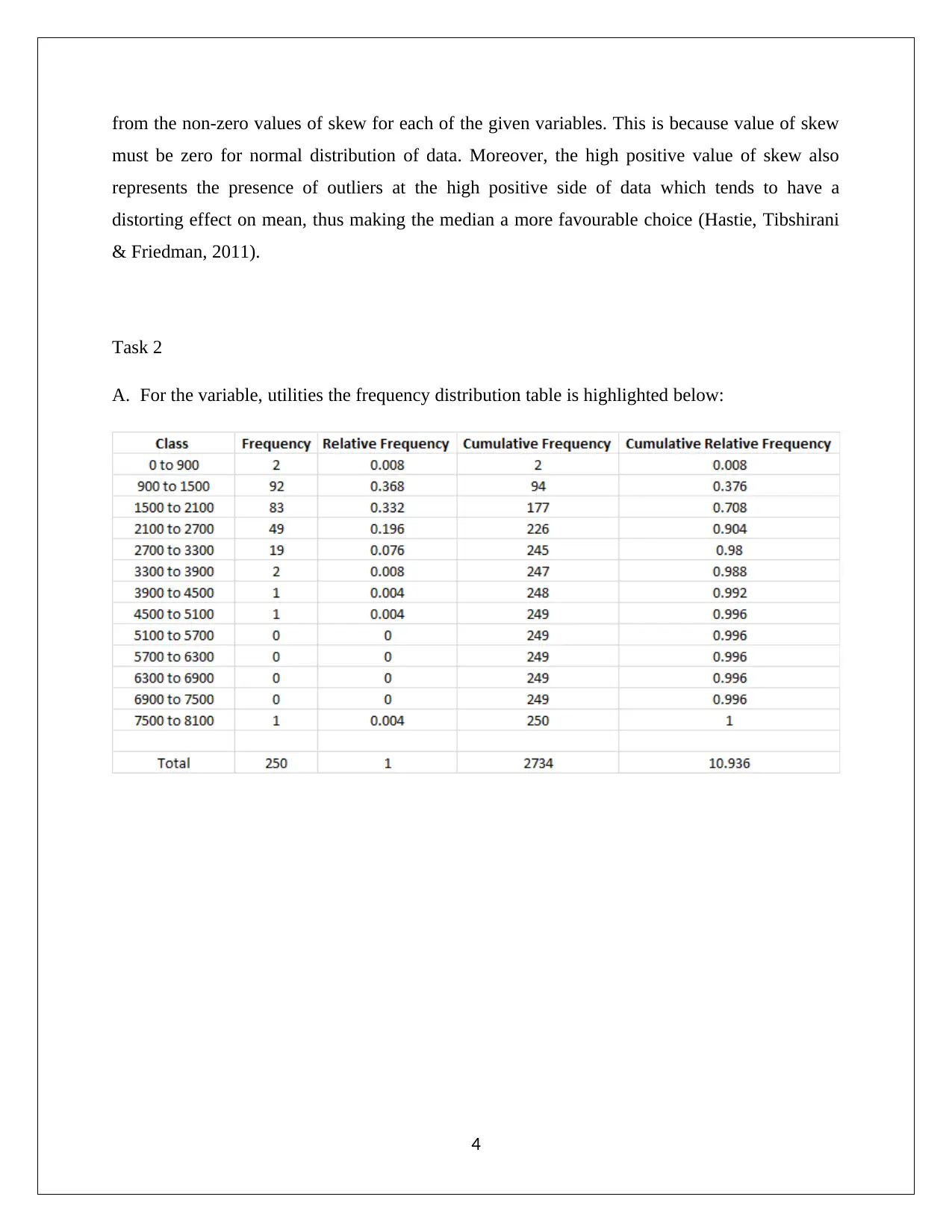
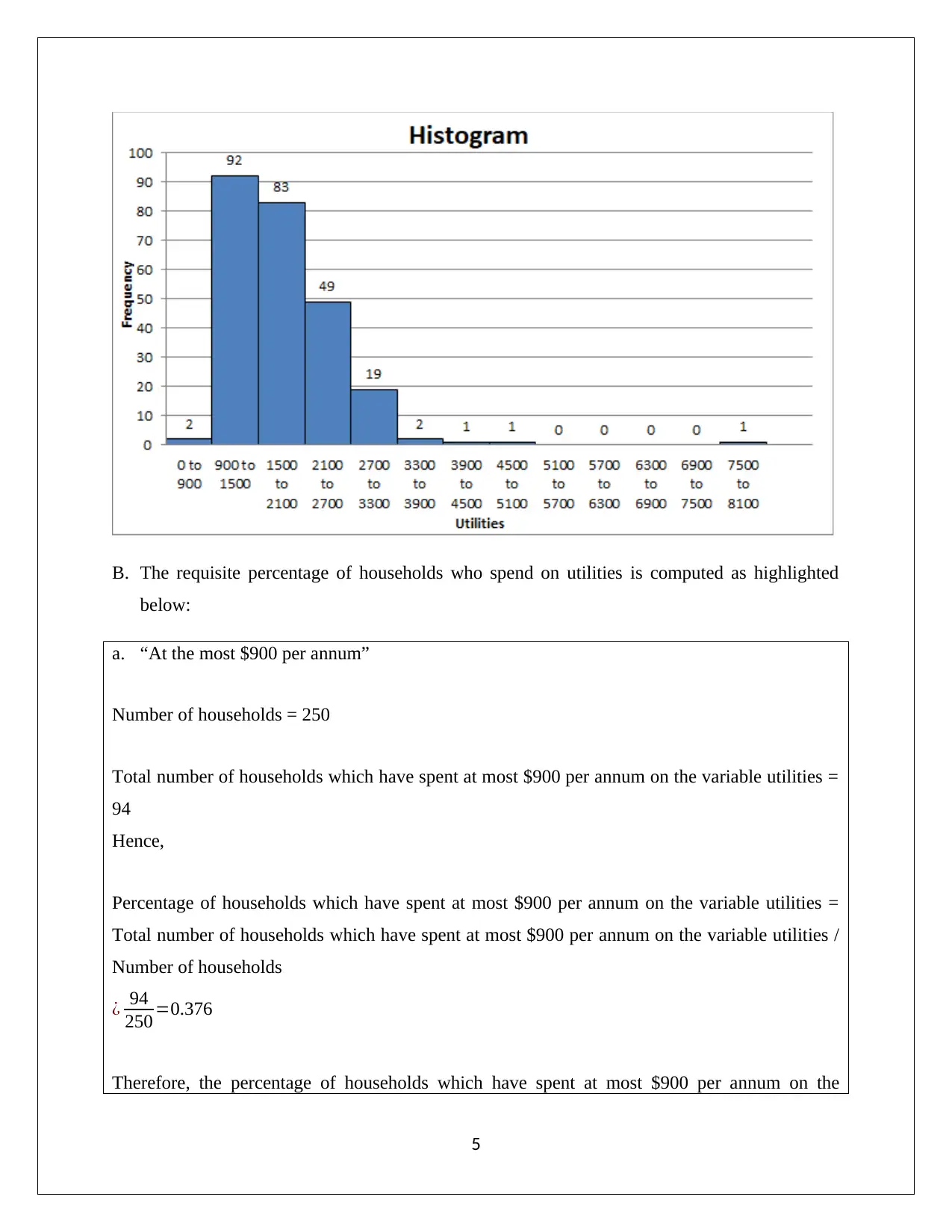
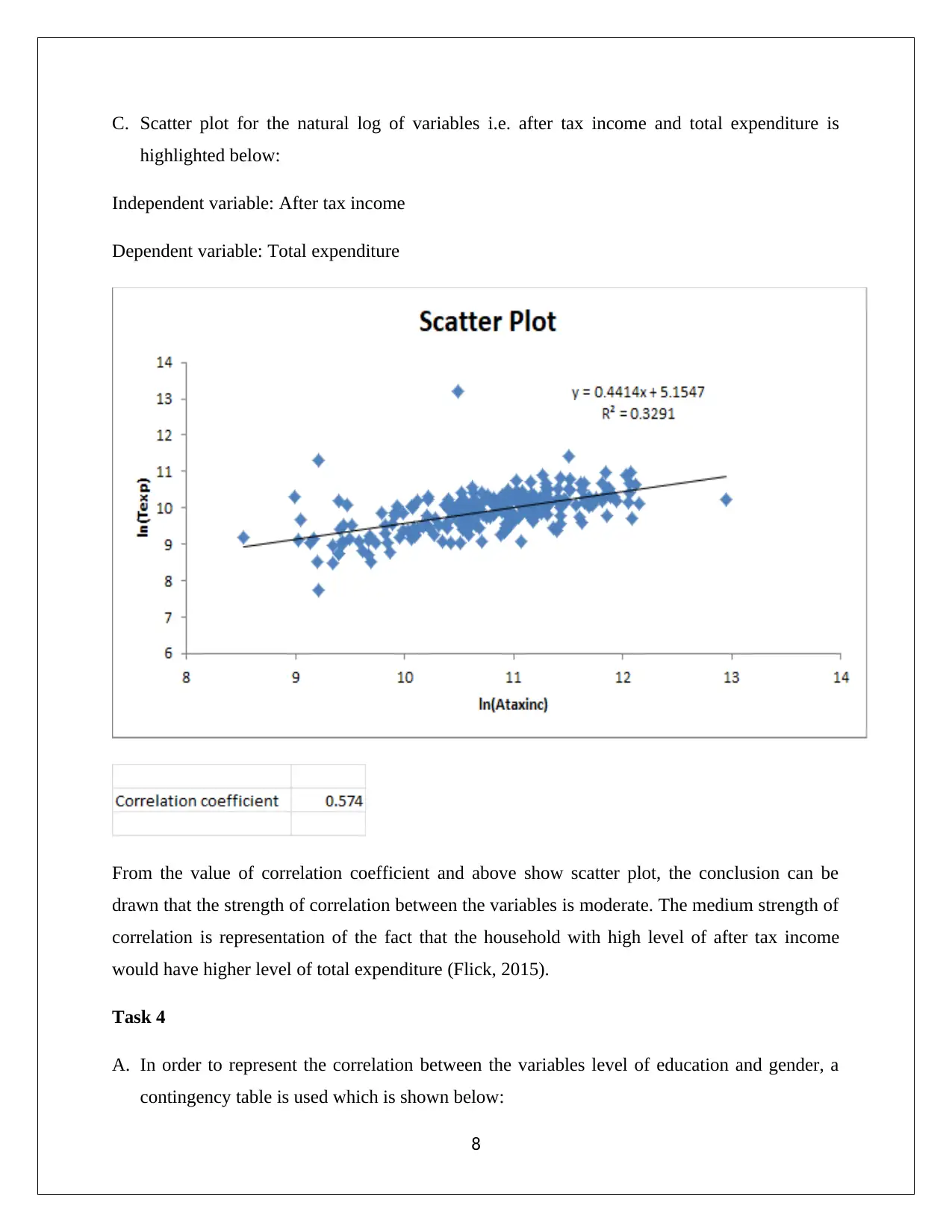
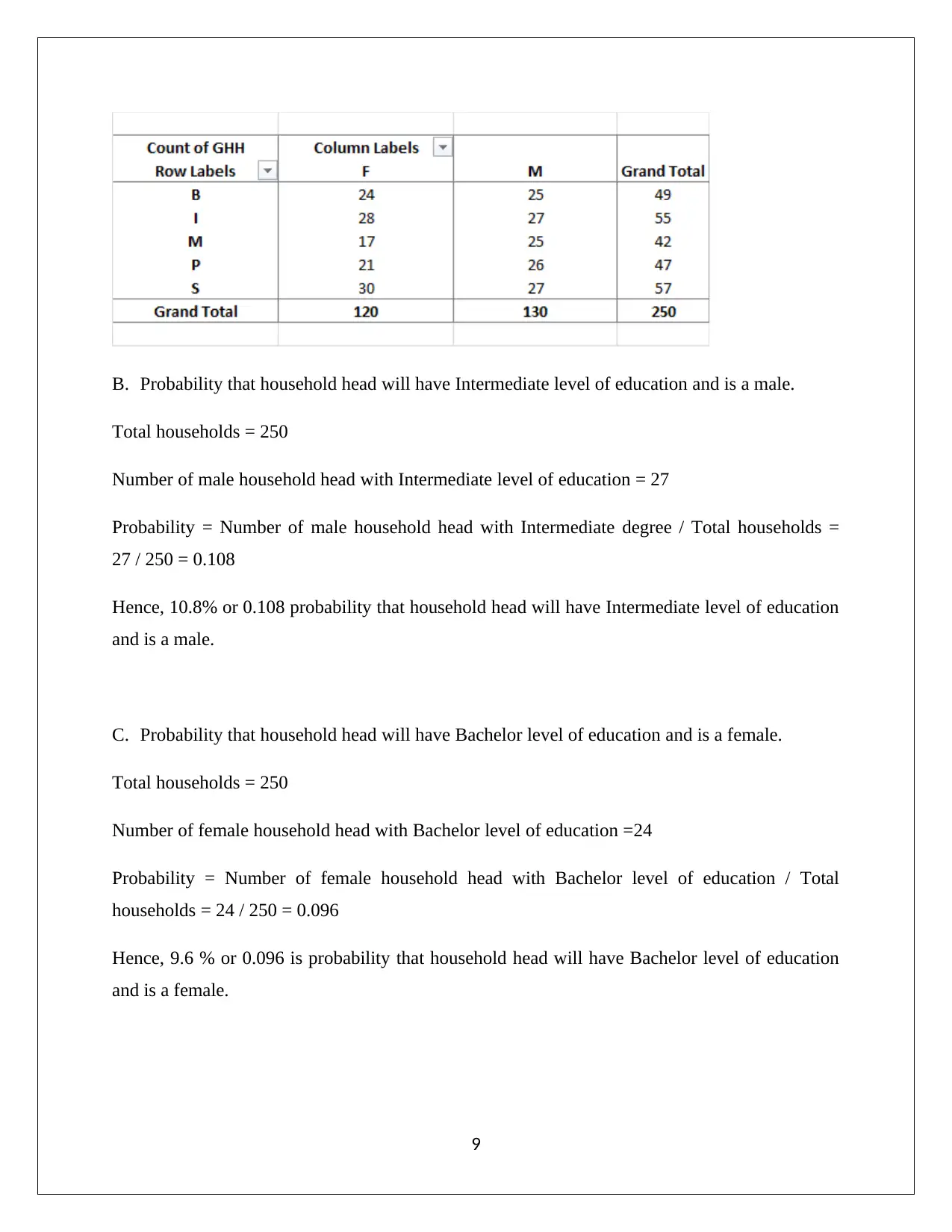
This report presents a comprehensive statistical analysis of household data, addressing various aspects such as sampling methods, descriptive statistics, frequency distributions, and correlation analysis. It begins by evaluating the appropriateness of simple random sampling and suggests stratified random sampling for better representation. Descriptive statistics and box-whisker plots are used to analyze variables like alcohol, meals, fuel, and phone expenses, revealing non-normal data distributions and the presence of outliers. The report then examines household spending on utilities, calculating percentages for different expenditure ranges. Further analysis includes determining top and bottom 5% values for after-tax income and discussing the probability distributions of household characteristics. Correlation between after-tax income and total expenditure is assessed using scatter plots and correlation coefficients. Finally, the report explores the relationship between education level and gender using contingency tables and probability calculations, concluding with an assessment of independence between variables. This assignment solution is available on Desklib, a platform offering a wealth of study resources for students.






1 out of 12
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.