MITS6002 Assignment 3: Retail Insights and Regression Analysis
VerifiedAdded on 2022/08/20
|11
|1630
|9
Homework Assignment
AI Summary
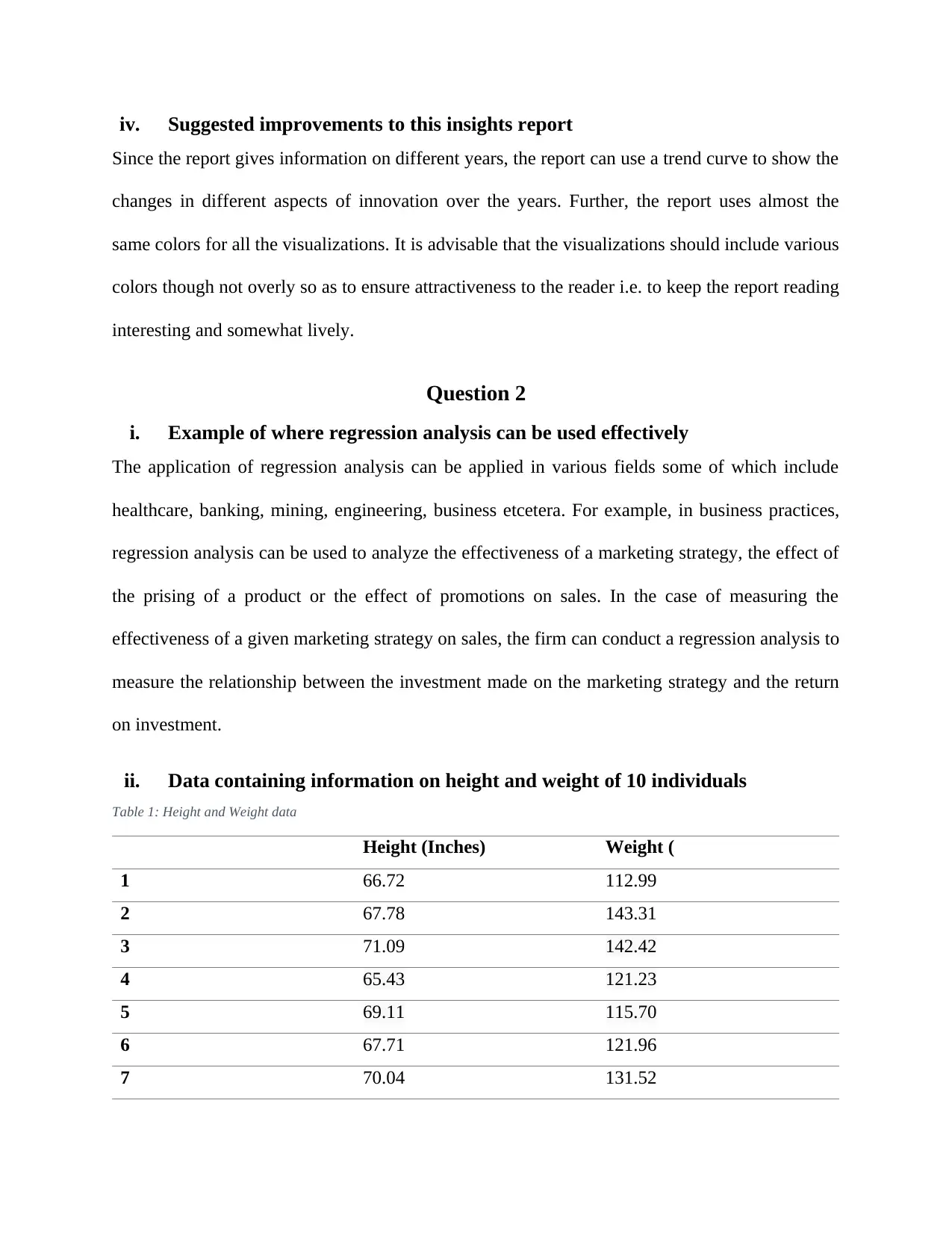
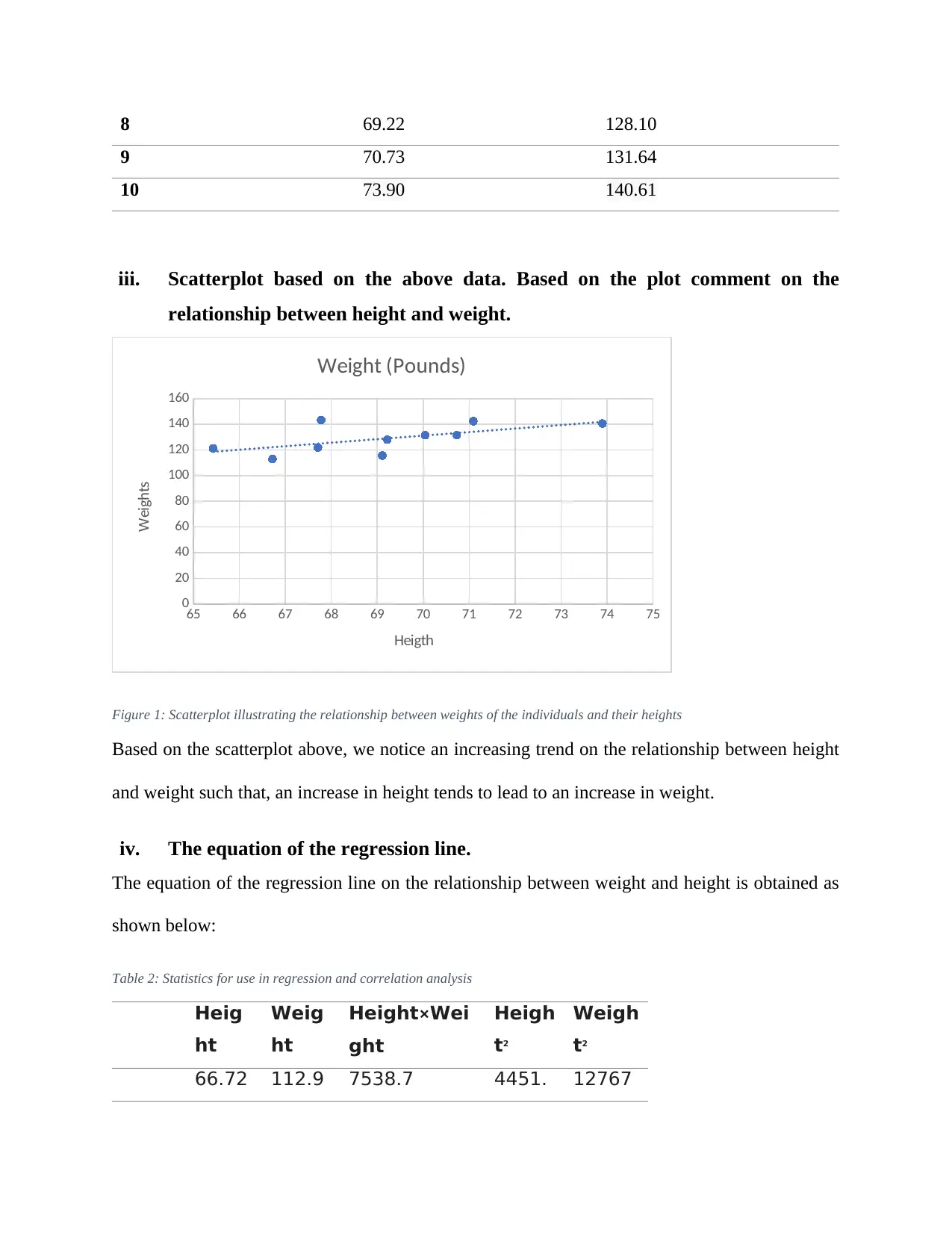
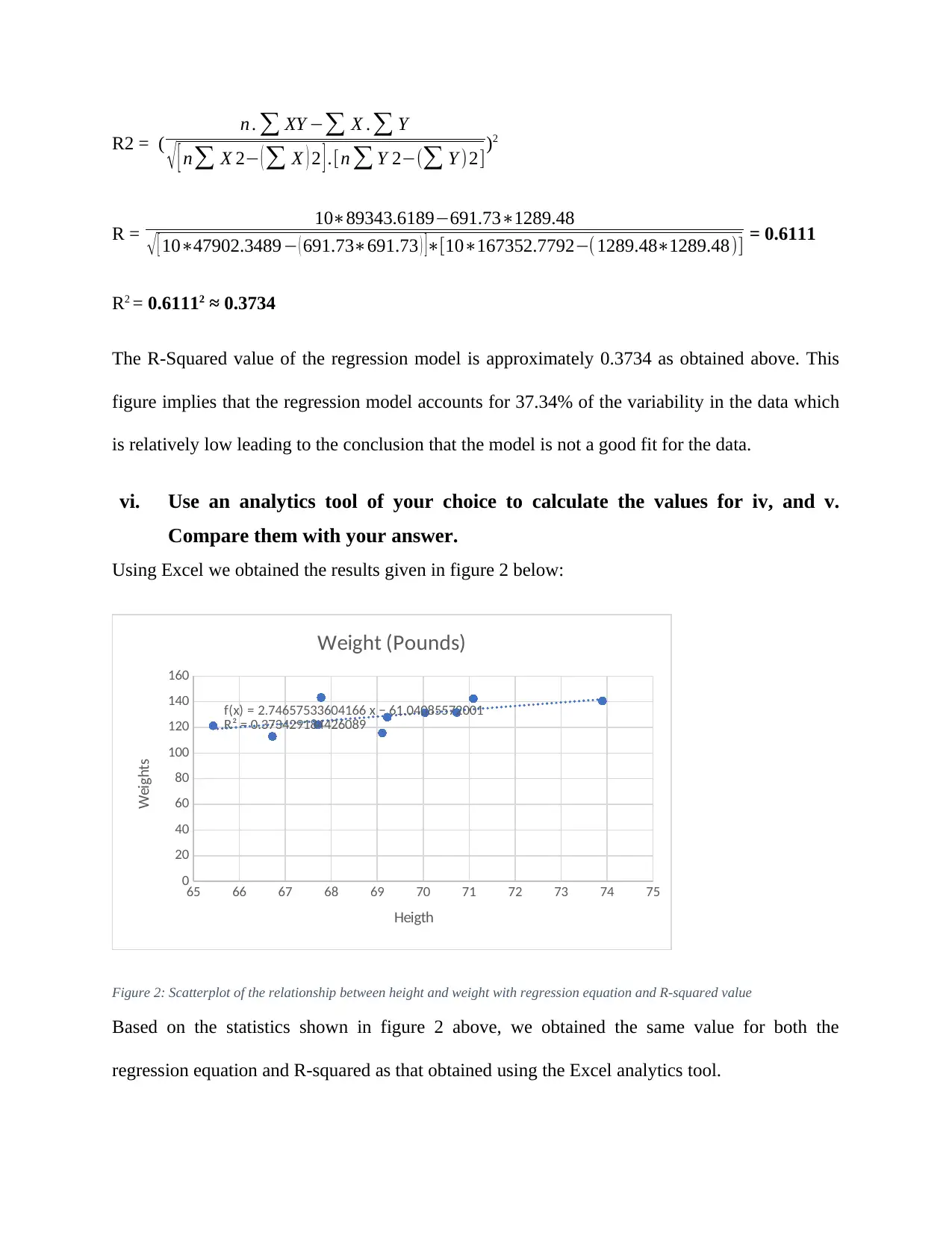
This assignment, for the MITS6002 Business Analytics course, addresses key concepts in data analysis and business insights. The first part of the assignment involves a critical review of the 'CommBank Retail Business Insights Report FY18,' evaluating the quality of visualizations, presentability, and the information provided, followed by a summary of key findings and suggestions for improvement. The report highlights innovation trends among Australian retailers. The second part delves into regression analysis, providing an example of its application, collecting and analyzing height and weight data to compute the regression equation, calculate the R-squared value, and interpret the goodness of fit. The third part differentiates between classification and prediction methods, explores neural networks, and discusses the application of clustering in business analytics, with examples such as customer segmentation in grocery stores, banking, and car rental businesses. References are included to support the analysis.








1 out of 11
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.