Business Analytics Report: Classification, Regression, and Analysis
VerifiedAdded on 2020/12/29
|12
|1793
|236
Report
AI Summary
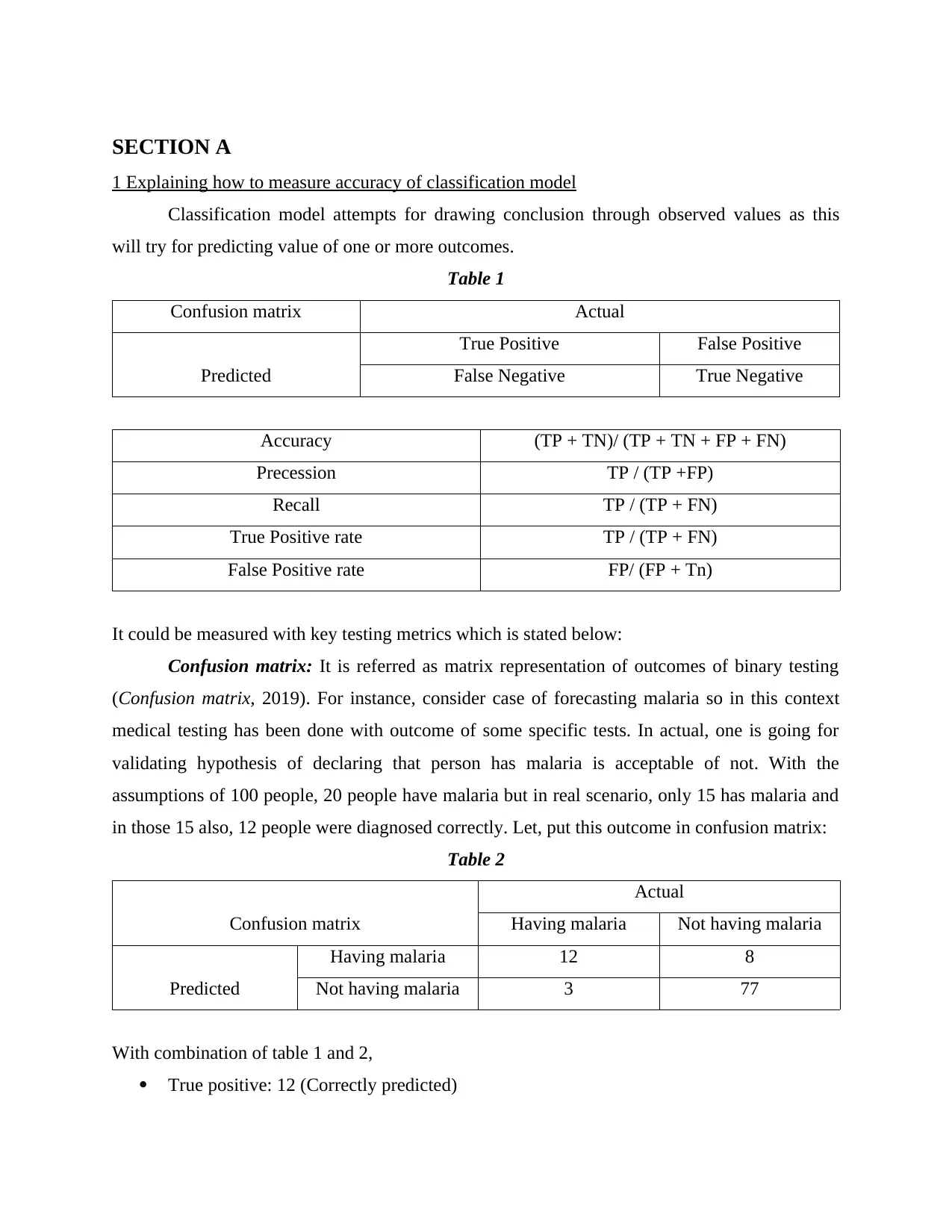
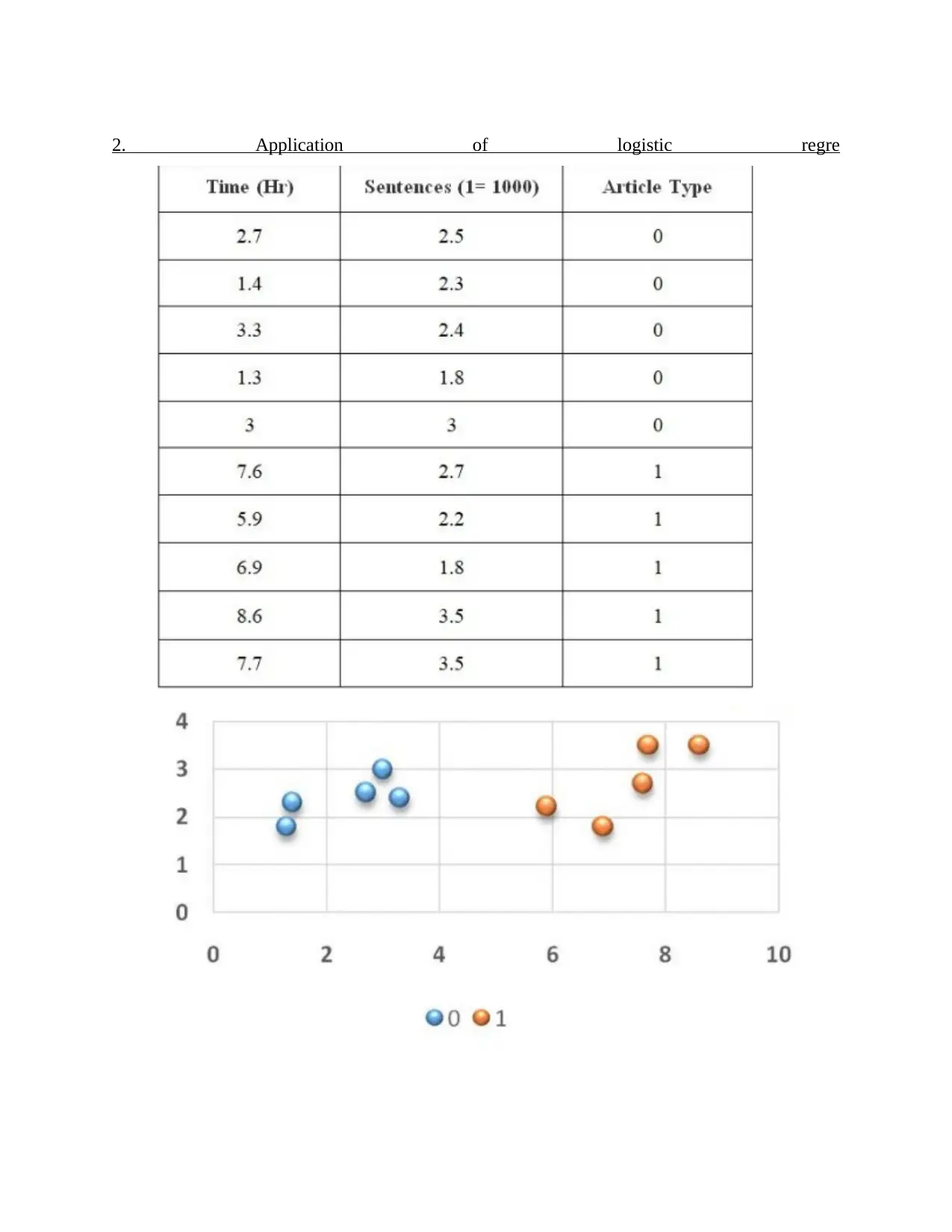
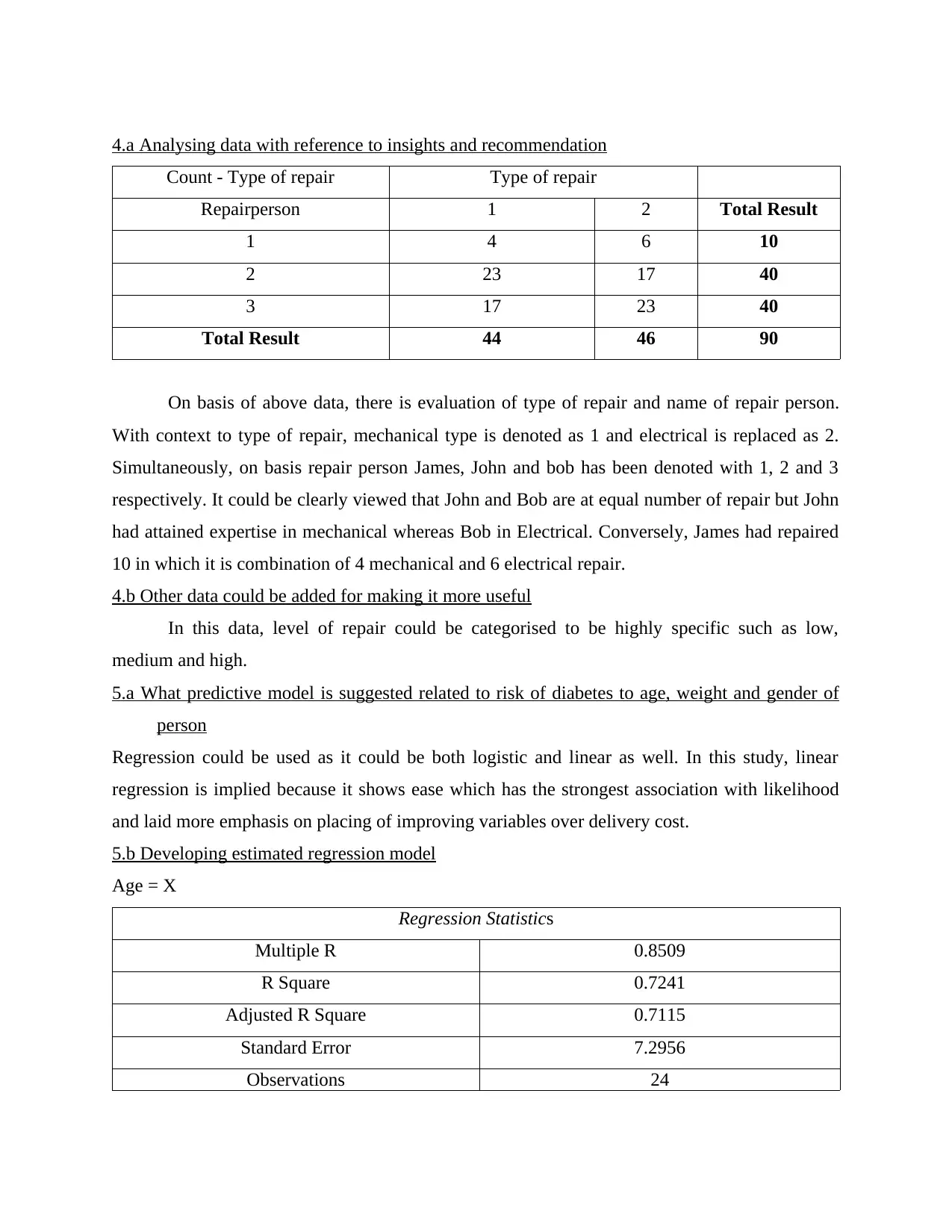
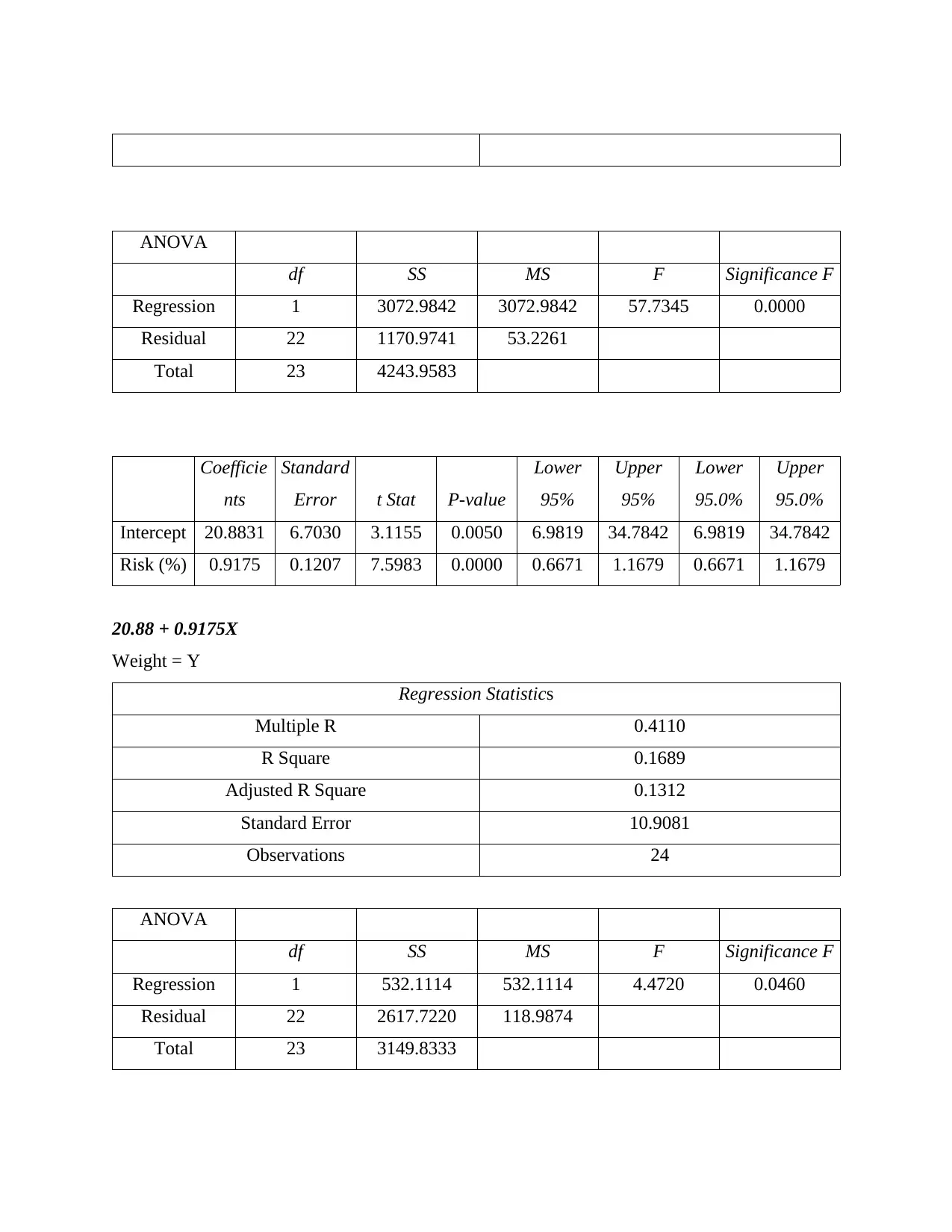
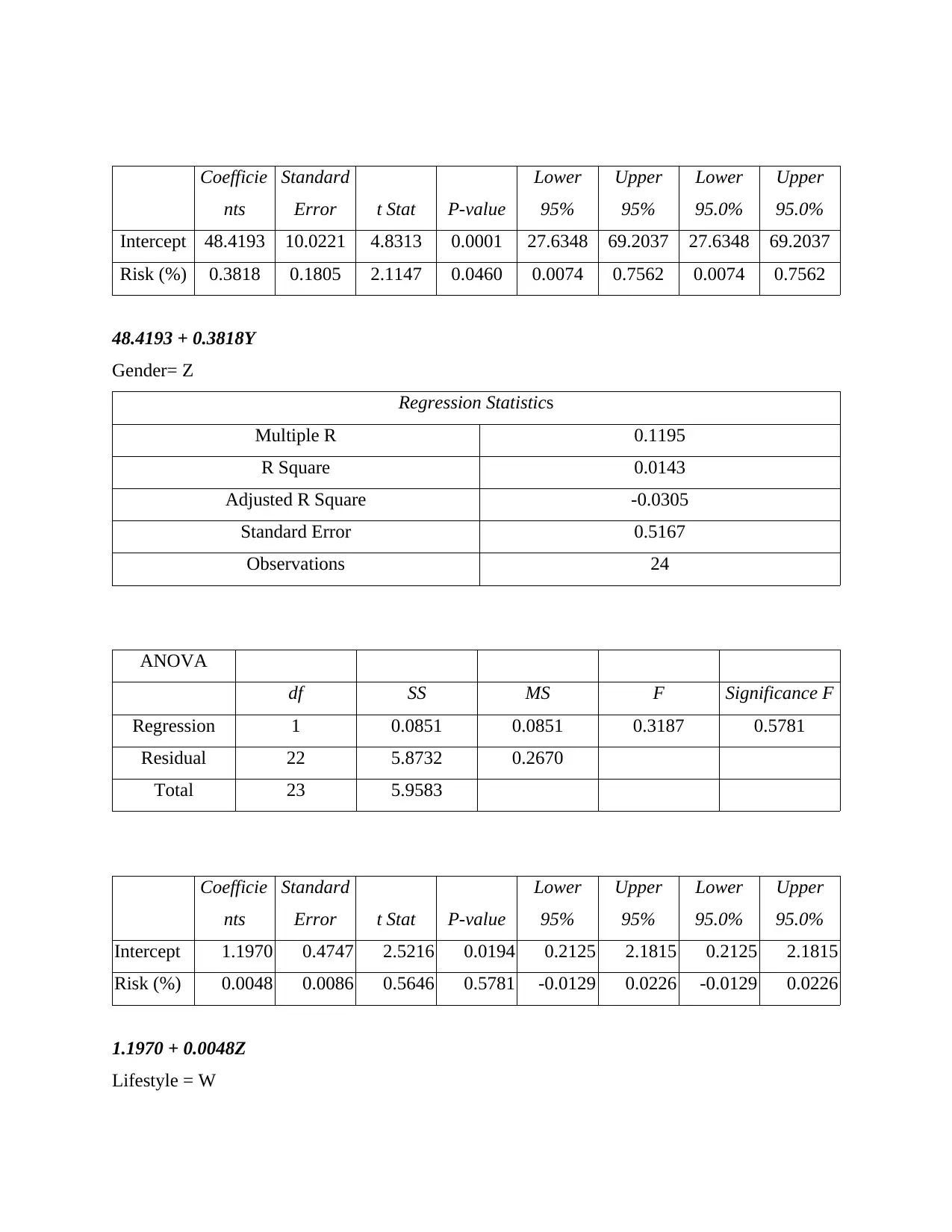
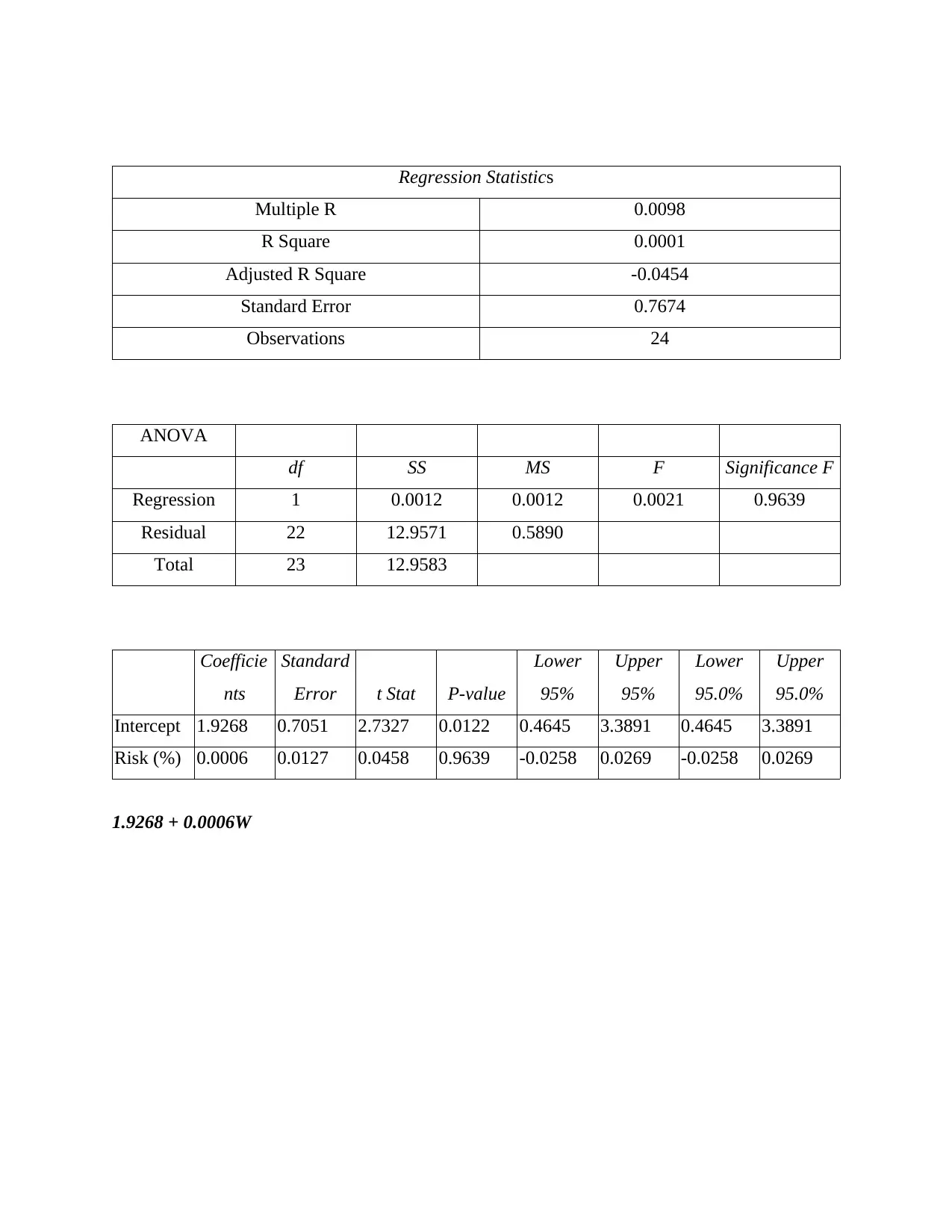
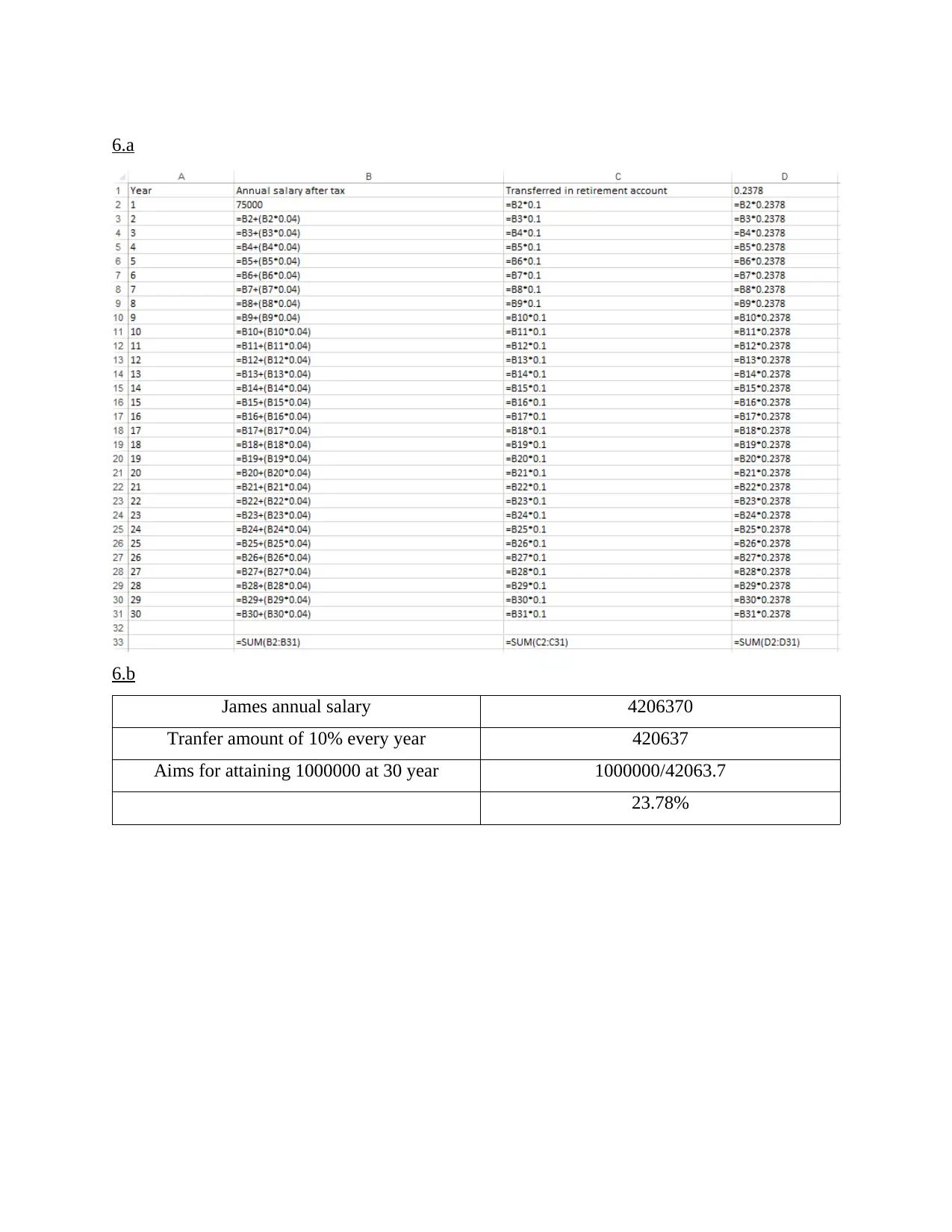
This business analytics report delves into various aspects of data analysis and predictive modeling. It begins by explaining how to measure the accuracy of classification models using the confusion matrix and related metrics like precision and recall. The report then explores the application of logistic regression with a hypothetical example involving technical and non-technical articles. Section B focuses on developing regression models, including steps for predicting spending patterns and a discussion on predictive models for new customers. The report also analyzes data, providing insights and recommendations based on repair data and suggests additional data points to enhance analysis. Furthermore, it suggests a predictive model for assessing the risk of diabetes based on age, weight, and gender, providing estimated regression models for each factor. The report concludes with additional analyses, including salary and transfer amount calculations and references to relevant online resources. This report provides a comprehensive overview of business analytics techniques, demonstrating the application of statistical methods in various business scenarios. The report uses examples to illustrate the concepts and includes the formulas used to derive the results.





1 out of 12
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.