Business Case Analysis on PCA for Utility Data, Assignment-II
VerifiedAdded on 2020/04/07
|7
|724
|42
Homework Assignment
AI Summary
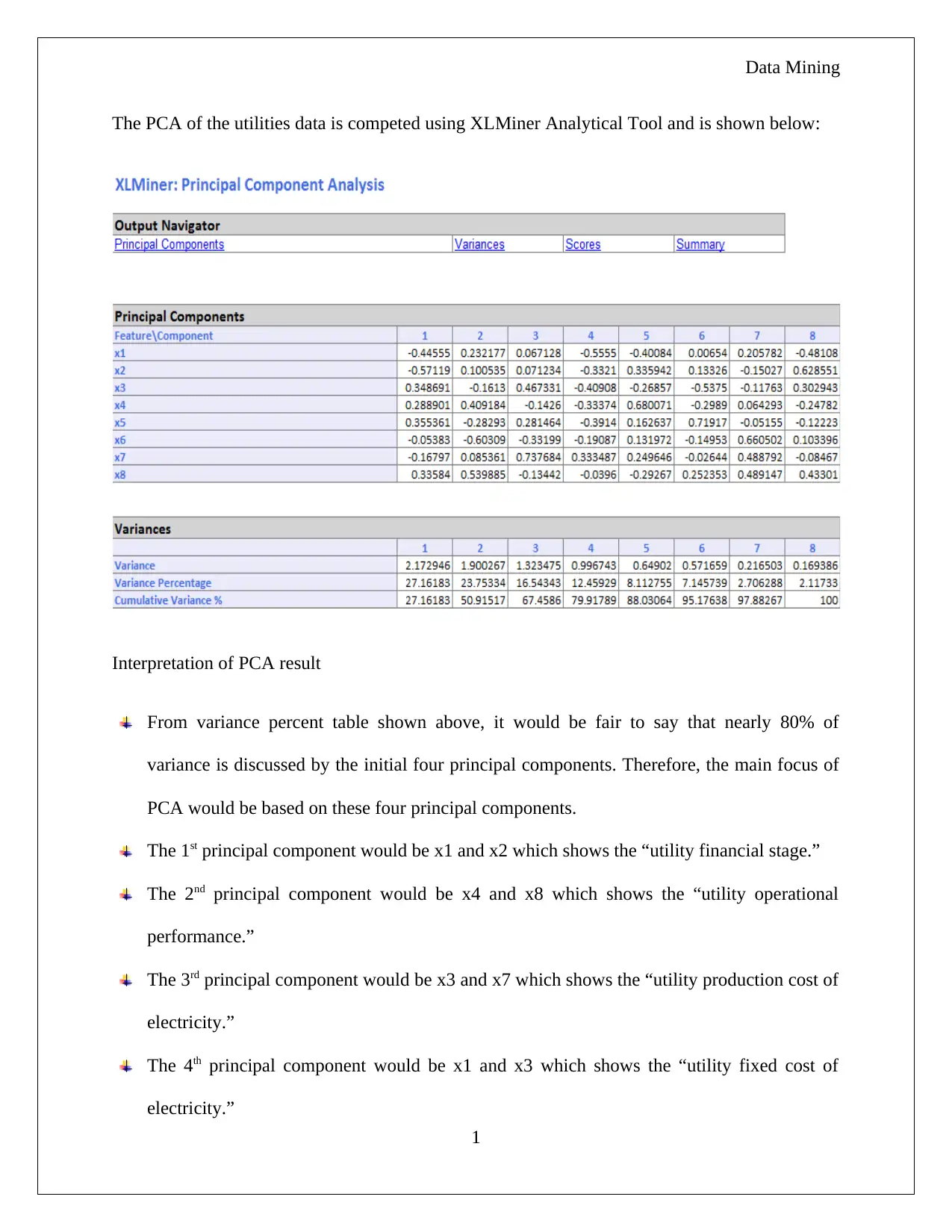
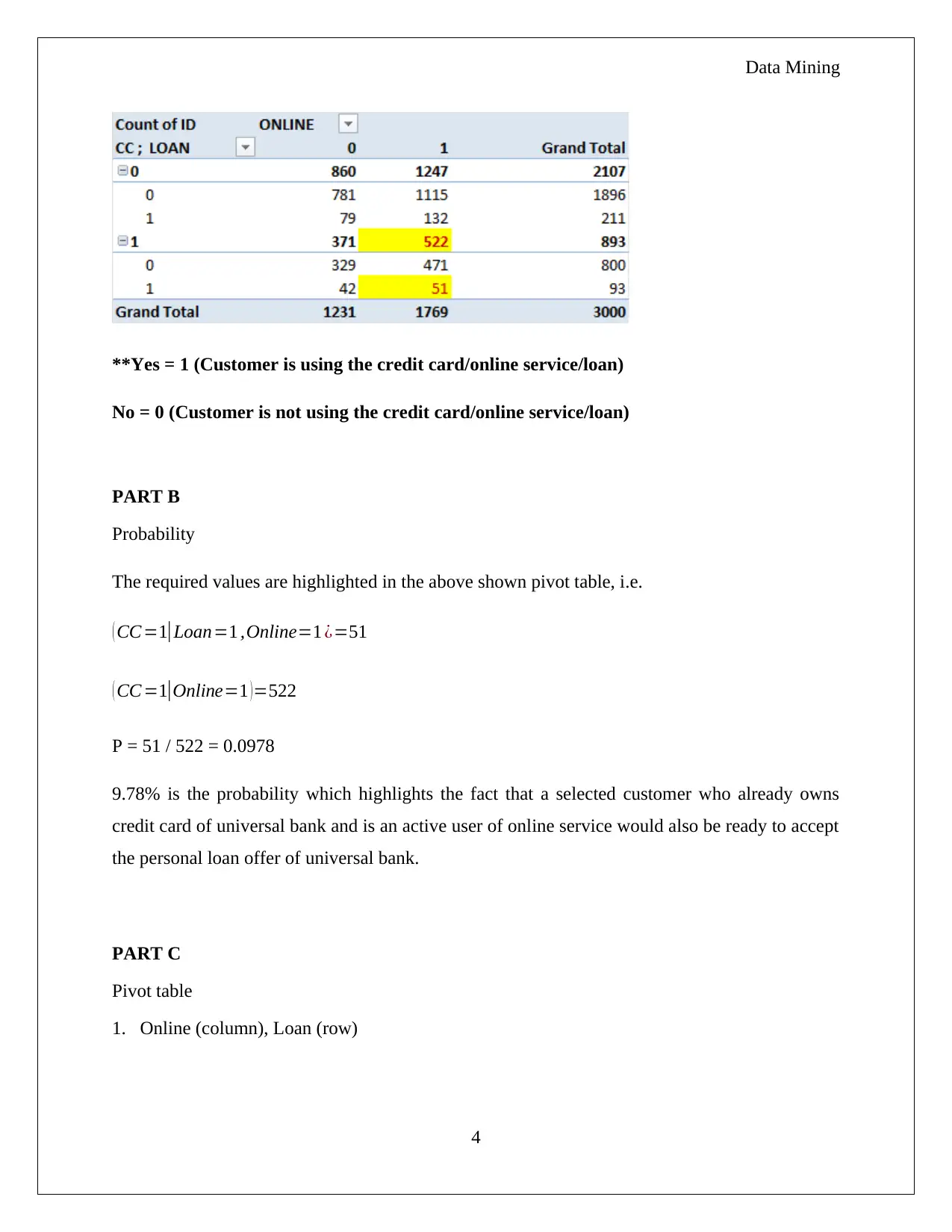
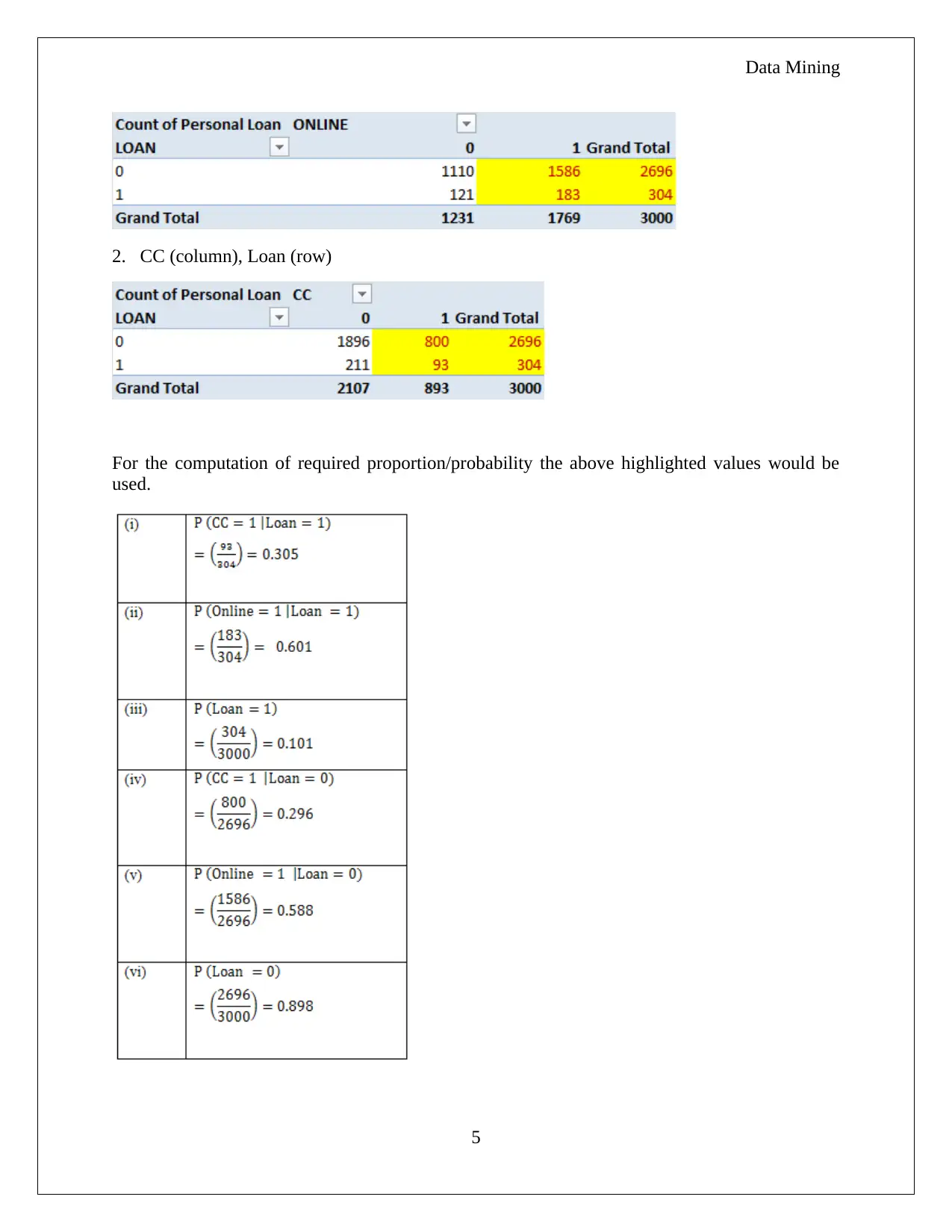
The homework assignment focuses on Principal Component Analysis (PCA) applied to utility data within a business case context. It starts by interpreting the results from a PCA run using the XLMiner Analytical Tool, discussing which components correspond to different aspects of utility performance like financial stage, operational performance, and production costs. The necessity for data normalization is also addressed, with justification based on variance contributions of variables. Part B explores both advantages and disadvantages of PCA, such as its effectiveness in linear relationships and challenges with non-linear ones or categorical data. Additionally, the assignment delves into probability calculations using a pivot table to determine customer likelihoods related to Universal Bank's credit card and loan services, employing Naïve Bayes Probability for further insights.




1 out of 7
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.