Business Data Analysis Exam: Statistical Analysis and Applications
VerifiedAdded on 2023/06/09
|24
|3321
|355
Quiz and Exam
AI Summary
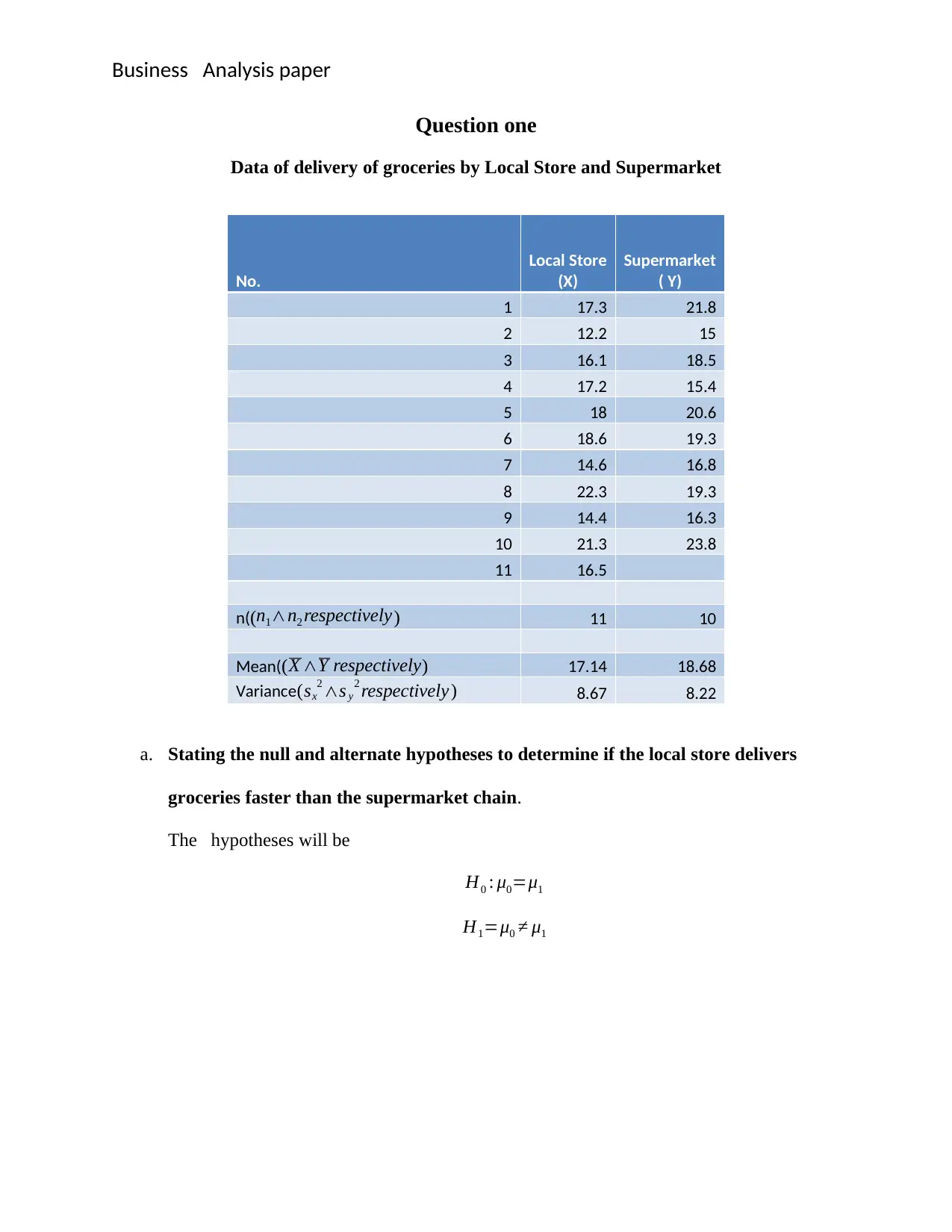
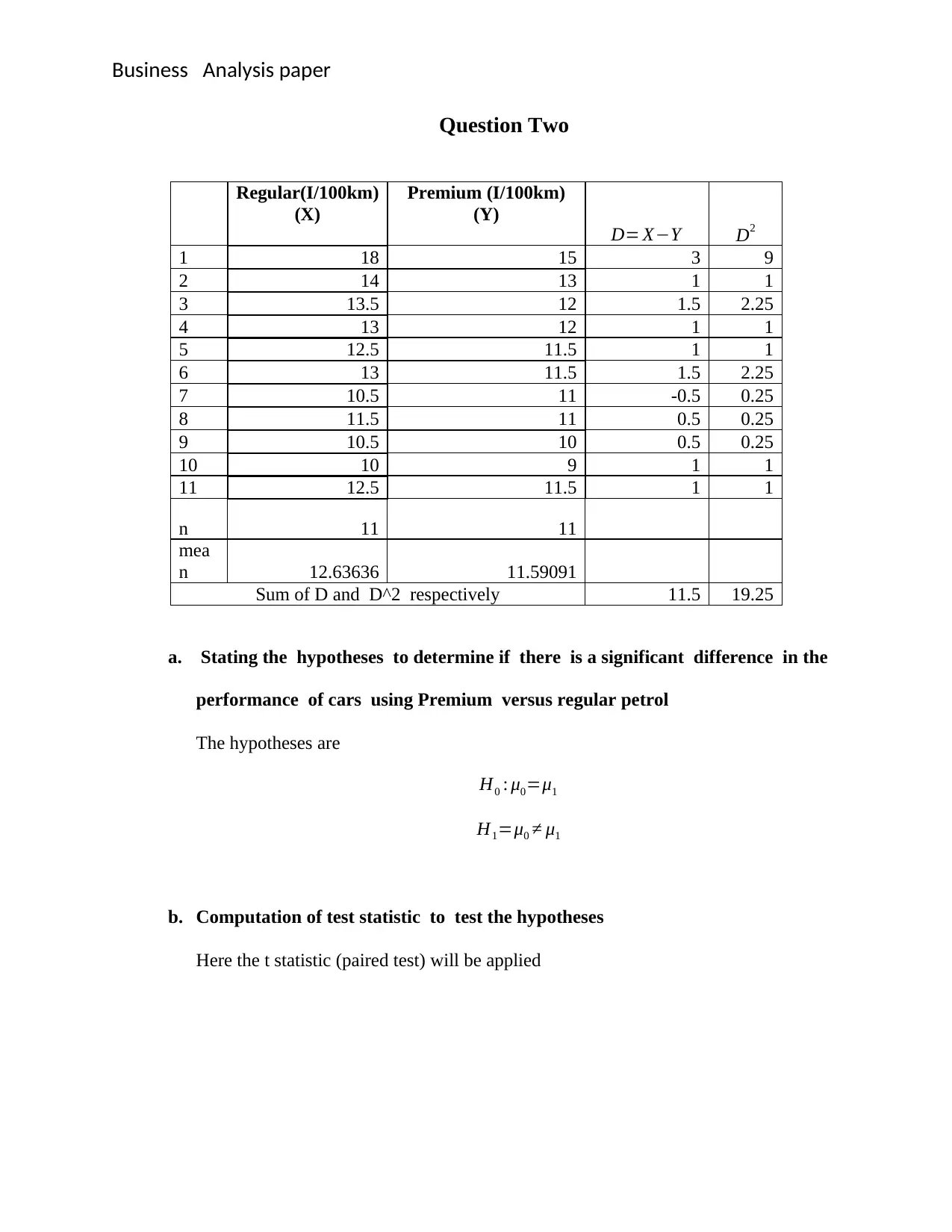
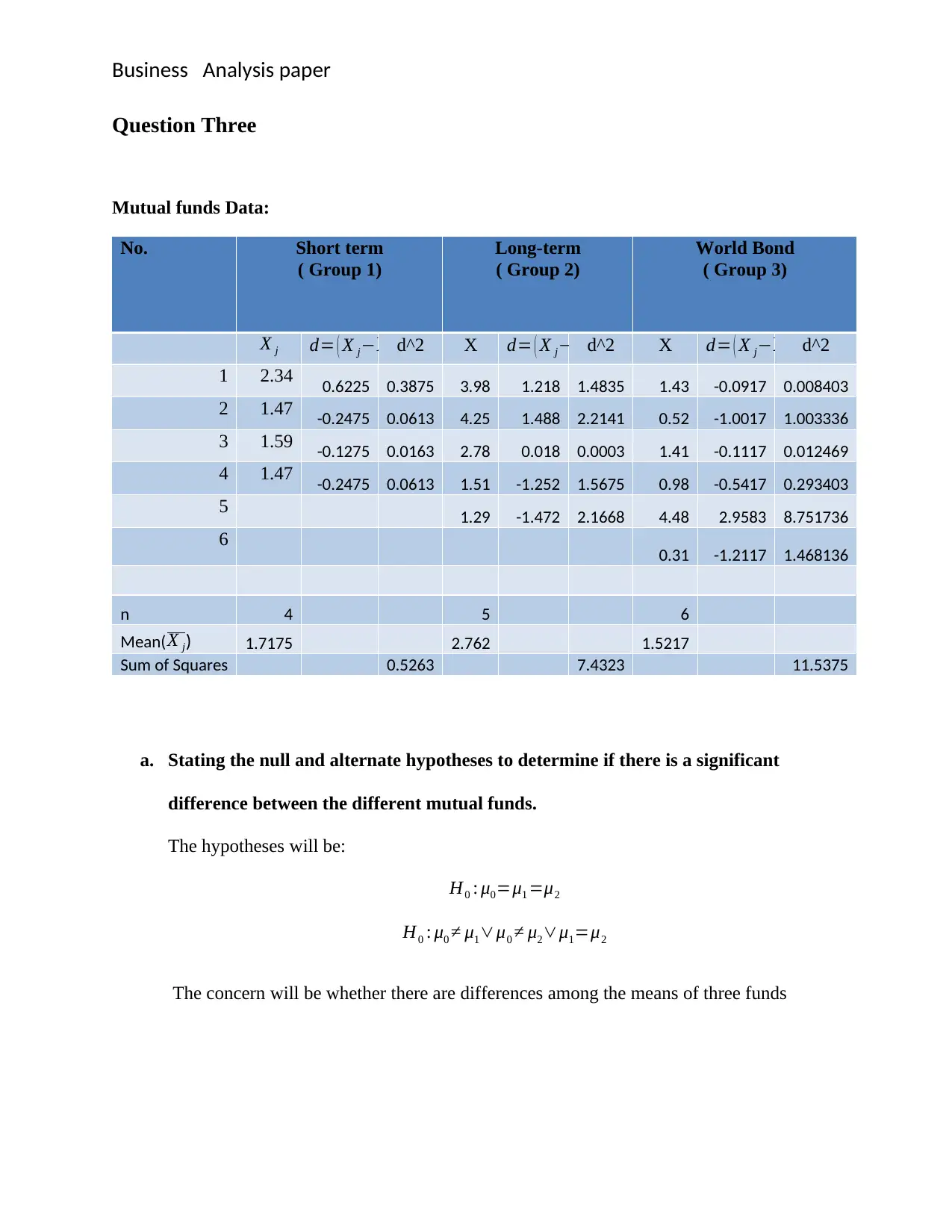
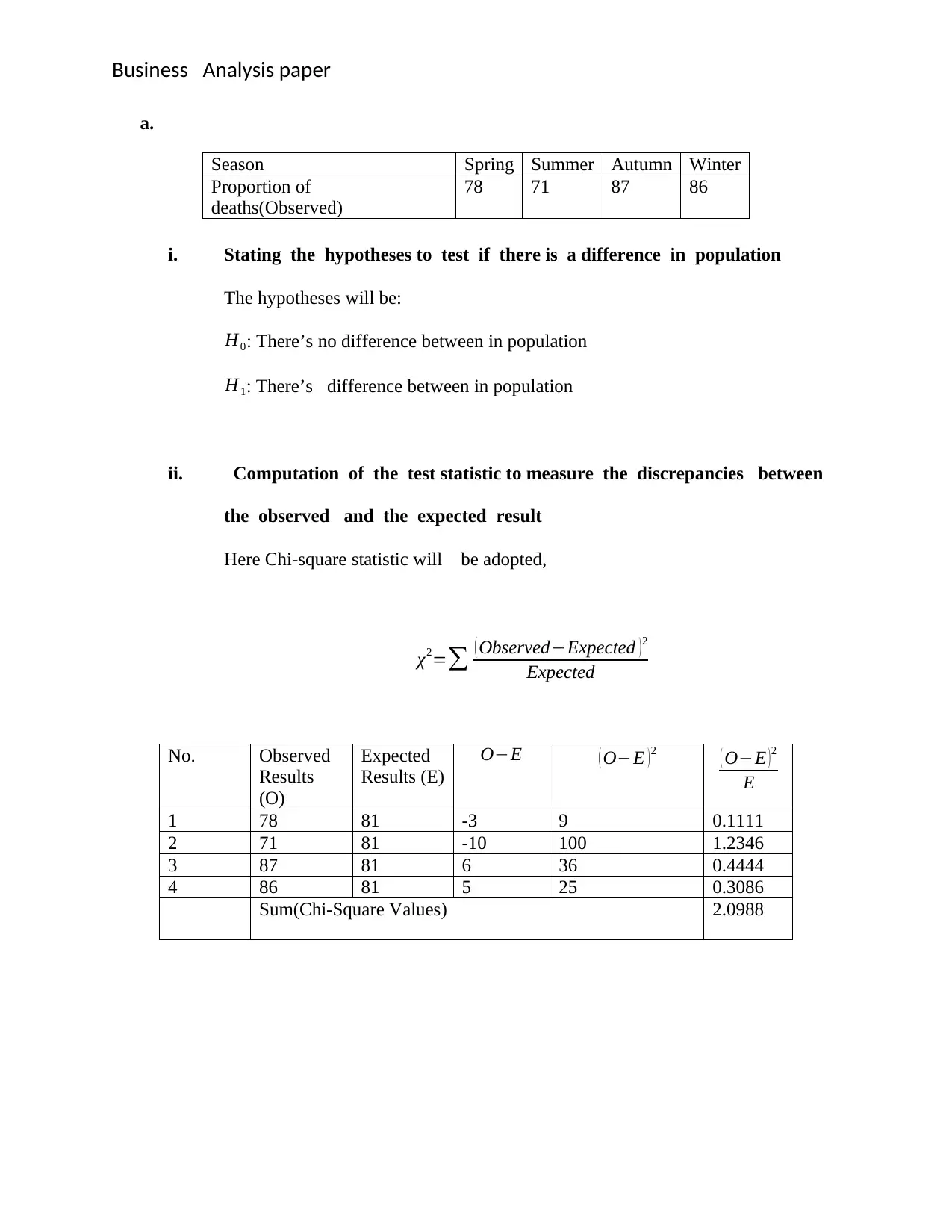
This document provides detailed solutions to a Business Data Analysis exam, covering various statistical concepts and their applications. The exam questions include hypothesis testing to compare grocery delivery times between a local store and a supermarket chain, analyzing car performance using regular versus premium petrol with paired t-tests, determining significant differences between mutual funds using one-way ANOVA, and testing population differences using the chi-square statistic. Additionally, the solutions demonstrate time series analysis techniques such as simple moving average, weighted moving average, and exponential smoothing to estimate Bitcoin closing prices. Each solution includes the null and alternative hypotheses, test statistic calculations, justification for the chosen significance level, and a clear interpretation of the results, providing a comprehensive understanding of the statistical methods applied.








1 out of 24


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.