Business Analytics and Decision Modelling Report: Predicting Profits
VerifiedAdded on 2021/04/21
|20
|2395
|21
Report
AI Summary
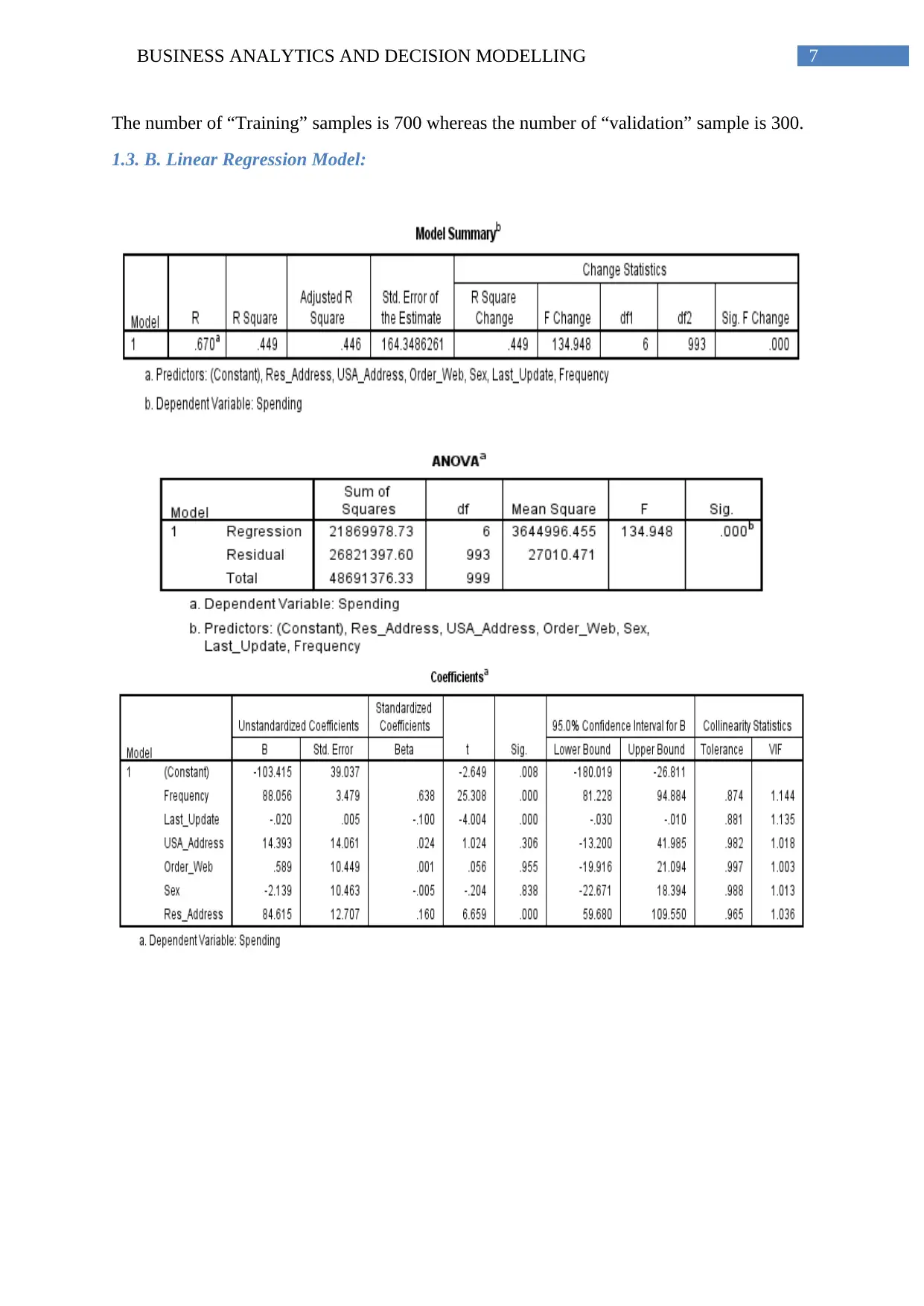
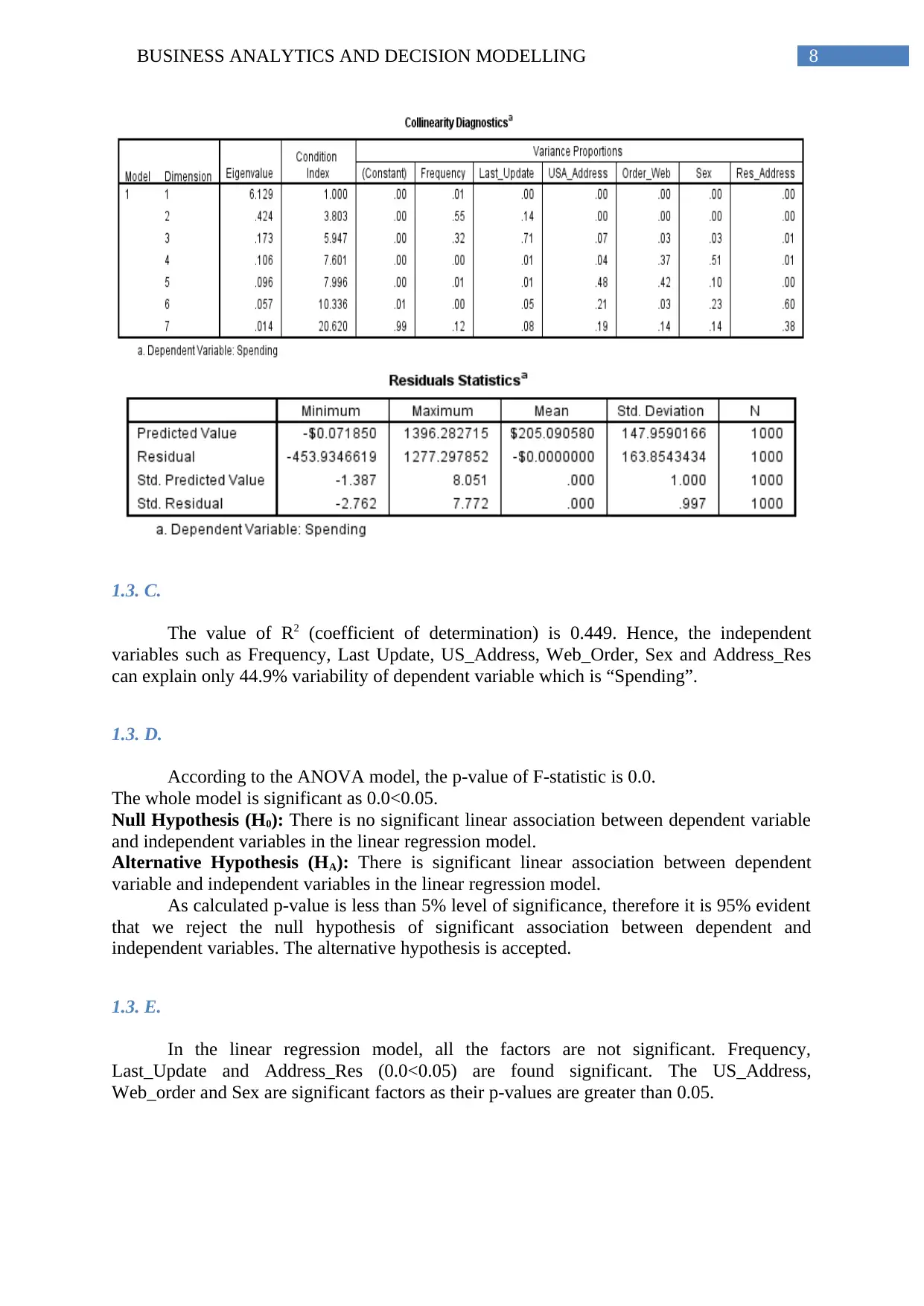
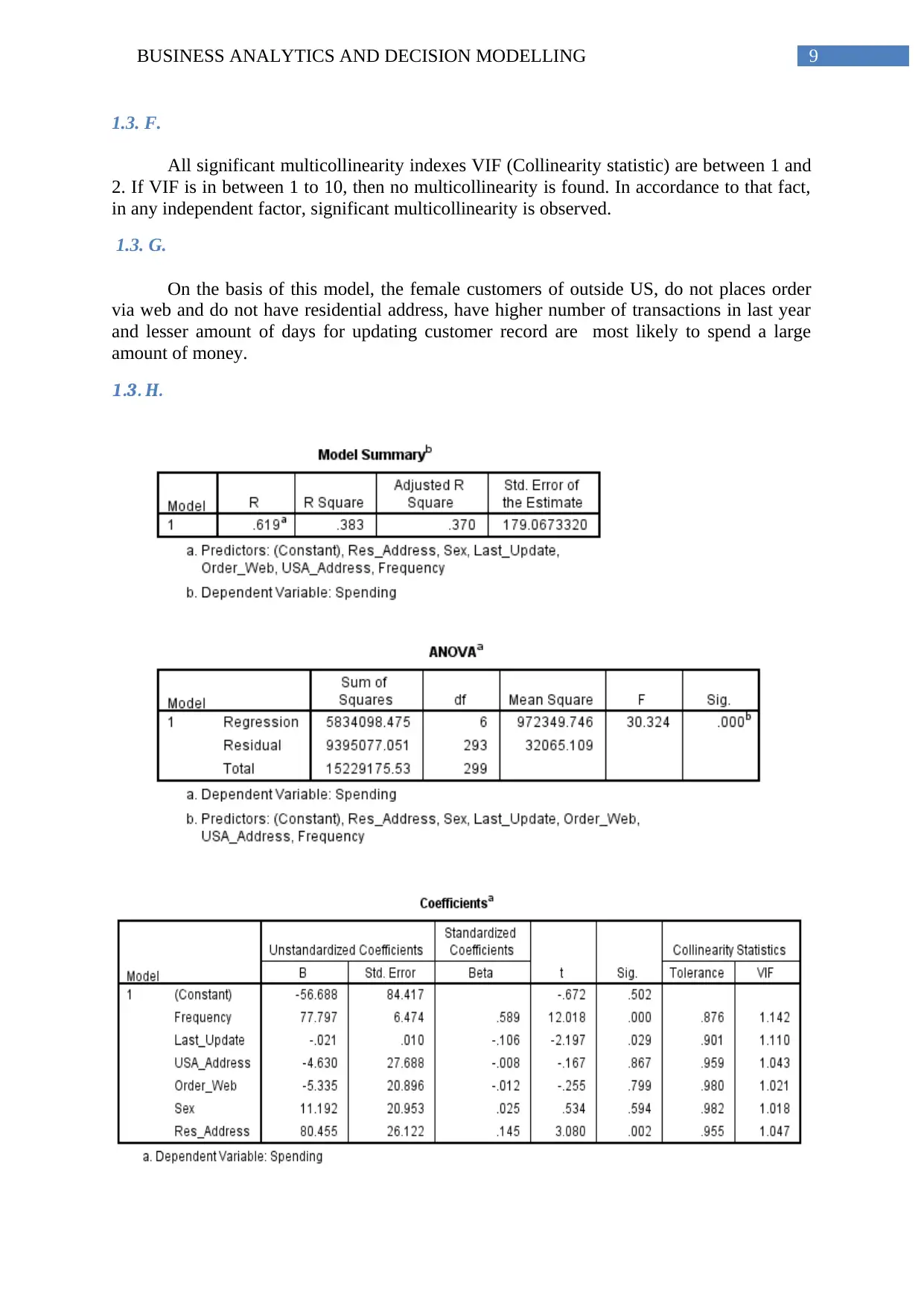
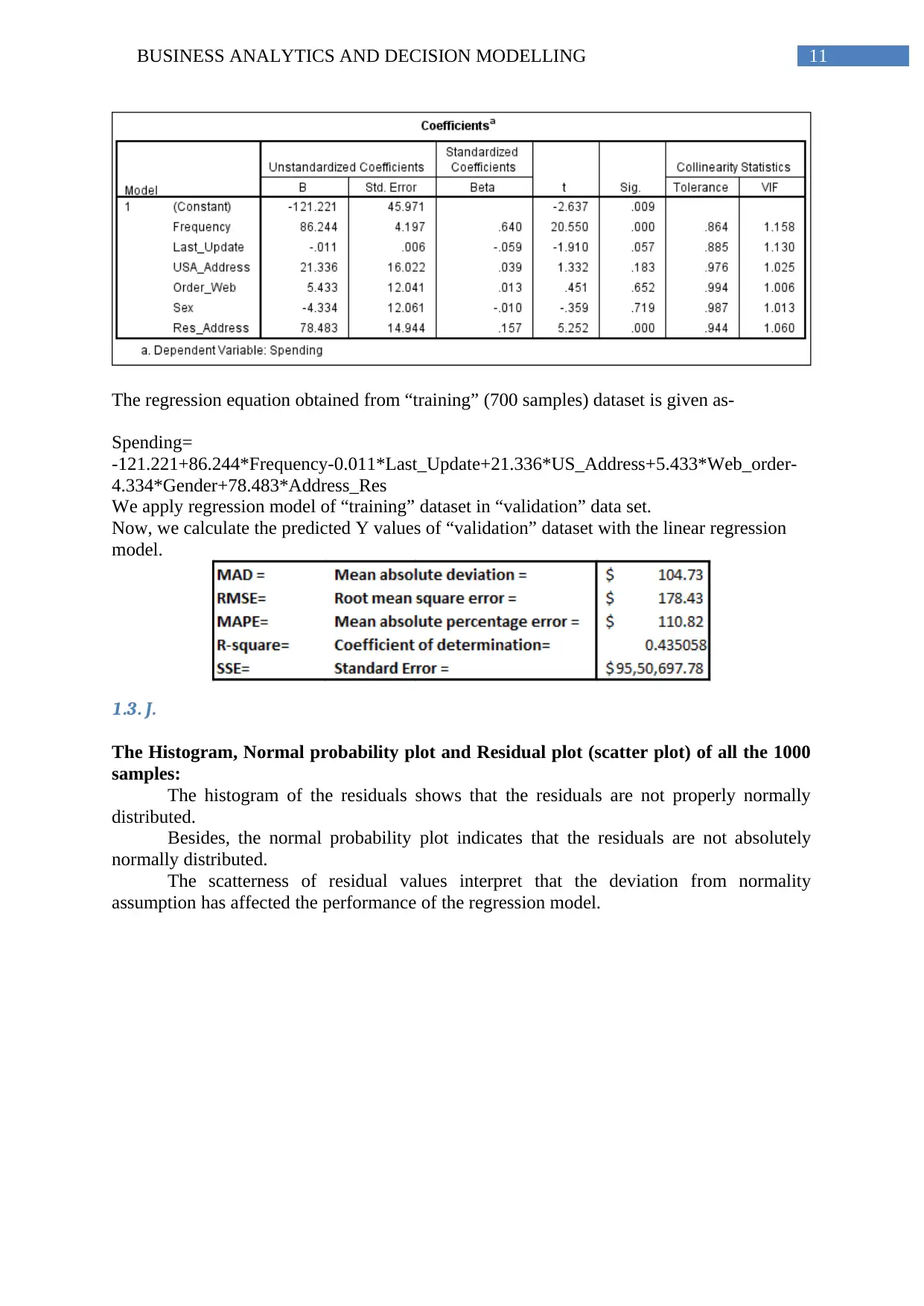
This report, focusing on Business Analytics and Decision Modeling, presents an analysis of two key areas: predicting software reselling profits and examining housing price structures. The profit prediction section employs exploratory statistics, scatter plots, and linear regression models to determine factors influencing customer spending. The analysis includes randomization, preprocessing of categorical variables, and evaluation of model significance, multicollinearity, and predictive accuracy. The second part investigates housing price structures in a specific township using one-sample and two-sample t-tests to assess premium prices for brick houses and different neighborhoods. The report explores hypotheses, test results, and interpretations, including the transformation of neighborhood levels for estimation purposes. The analysis uses statistical tools to evaluate the relationship between different variables and their impact on business decisions.




1 out of 20
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.