Decision Support Tools in Business: Analysis, Simulations, and Models
VerifiedAdded on 2019/10/31
|14
|1626
|269
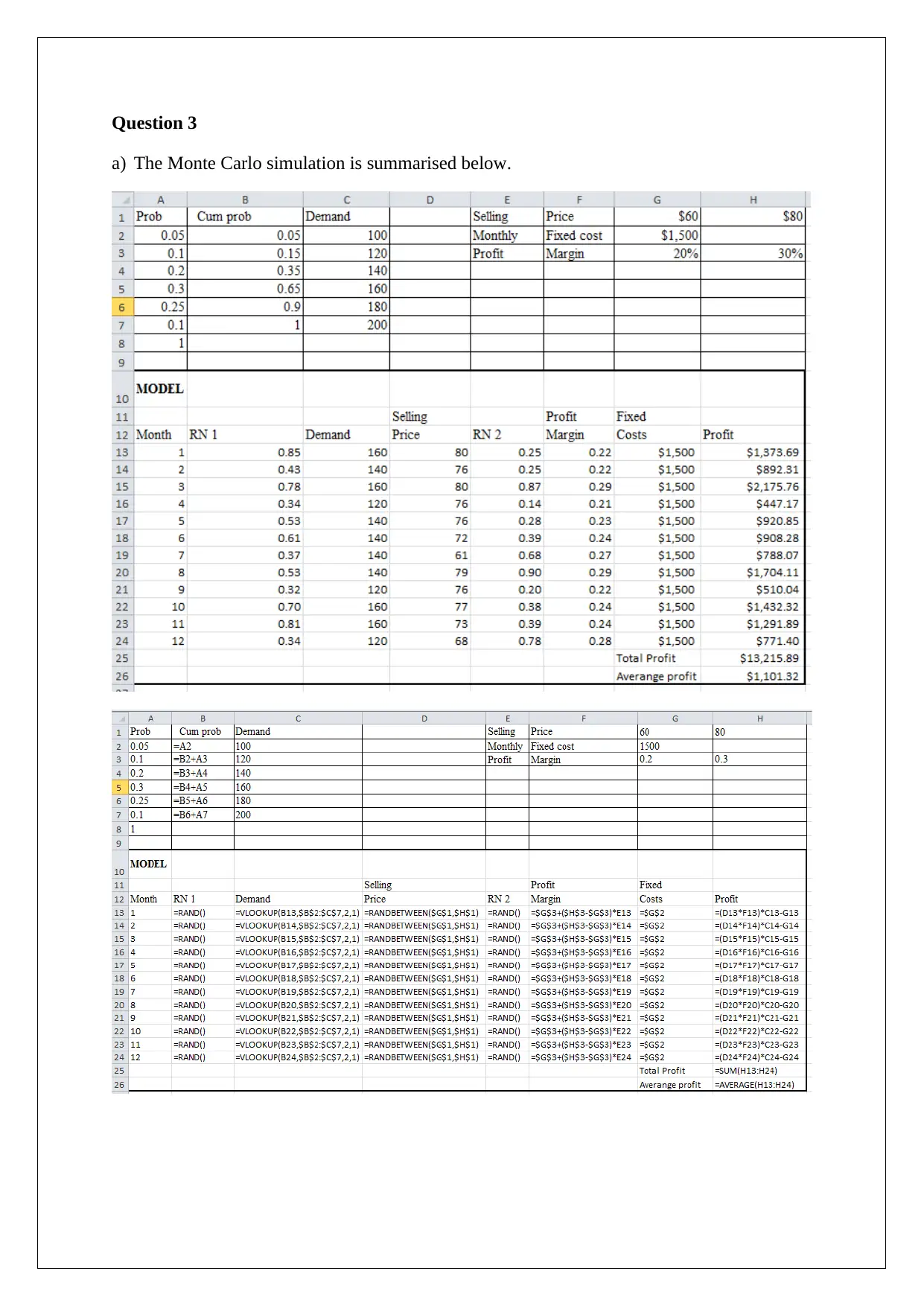
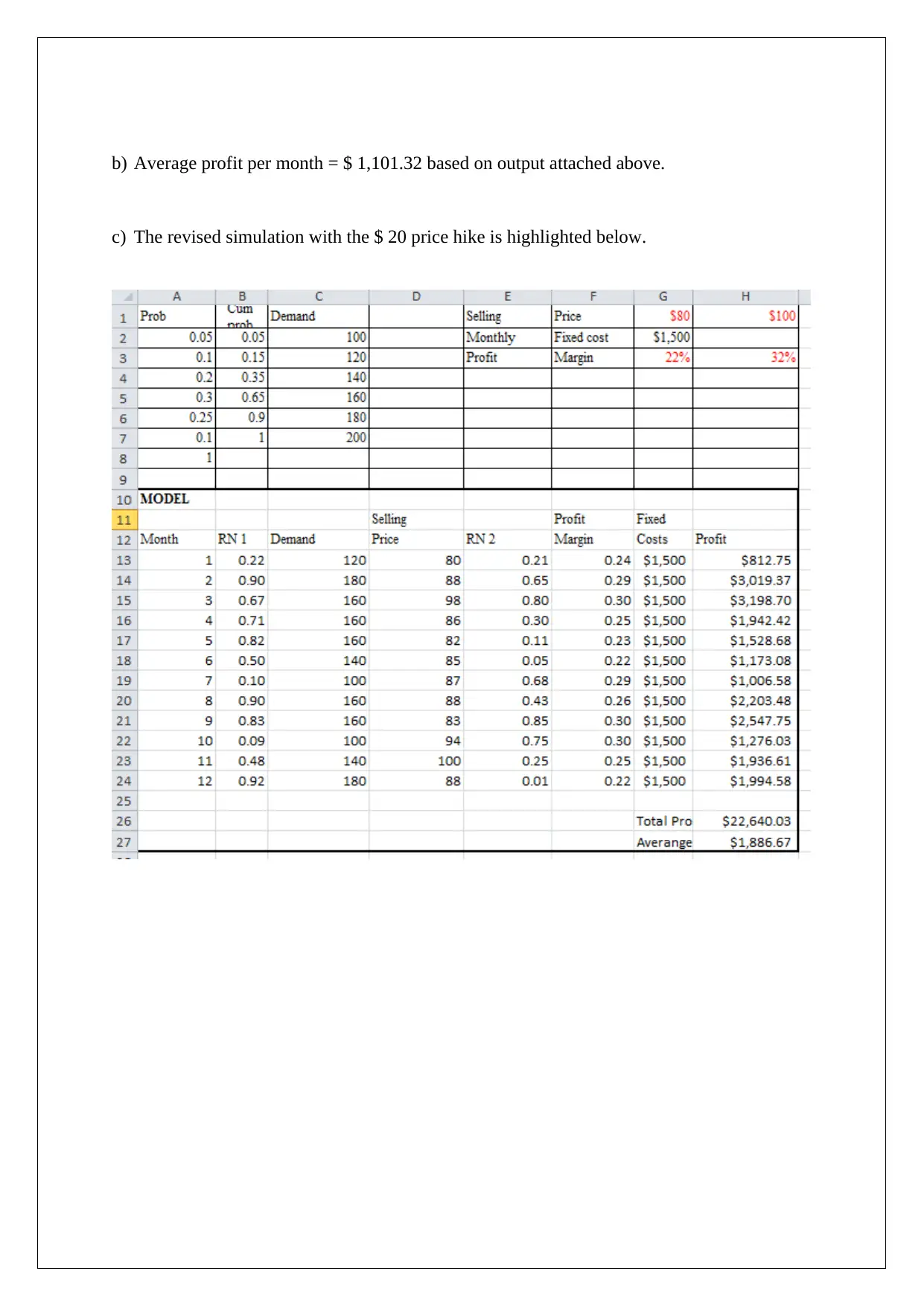
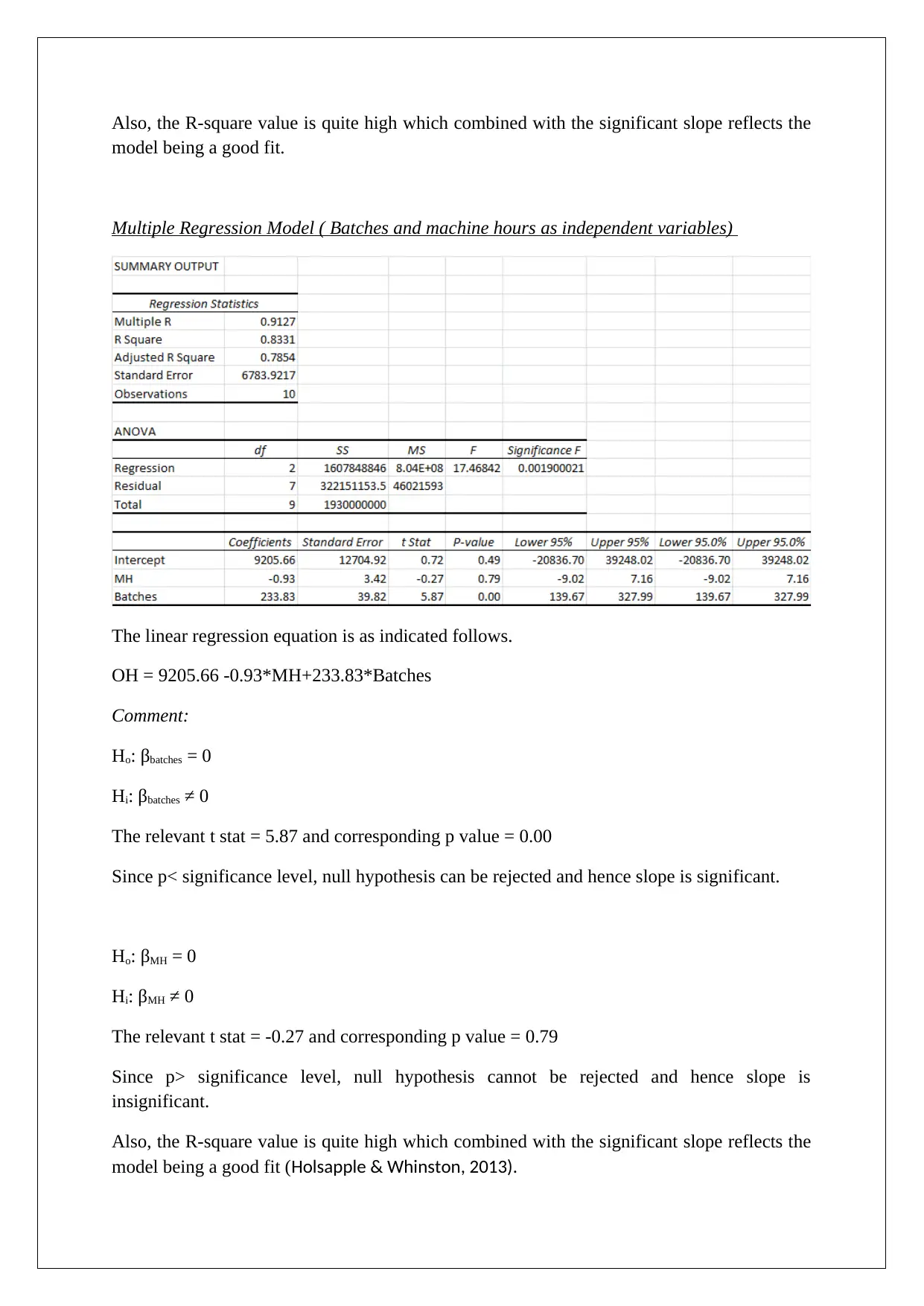
Homework Assignment
AI Summary
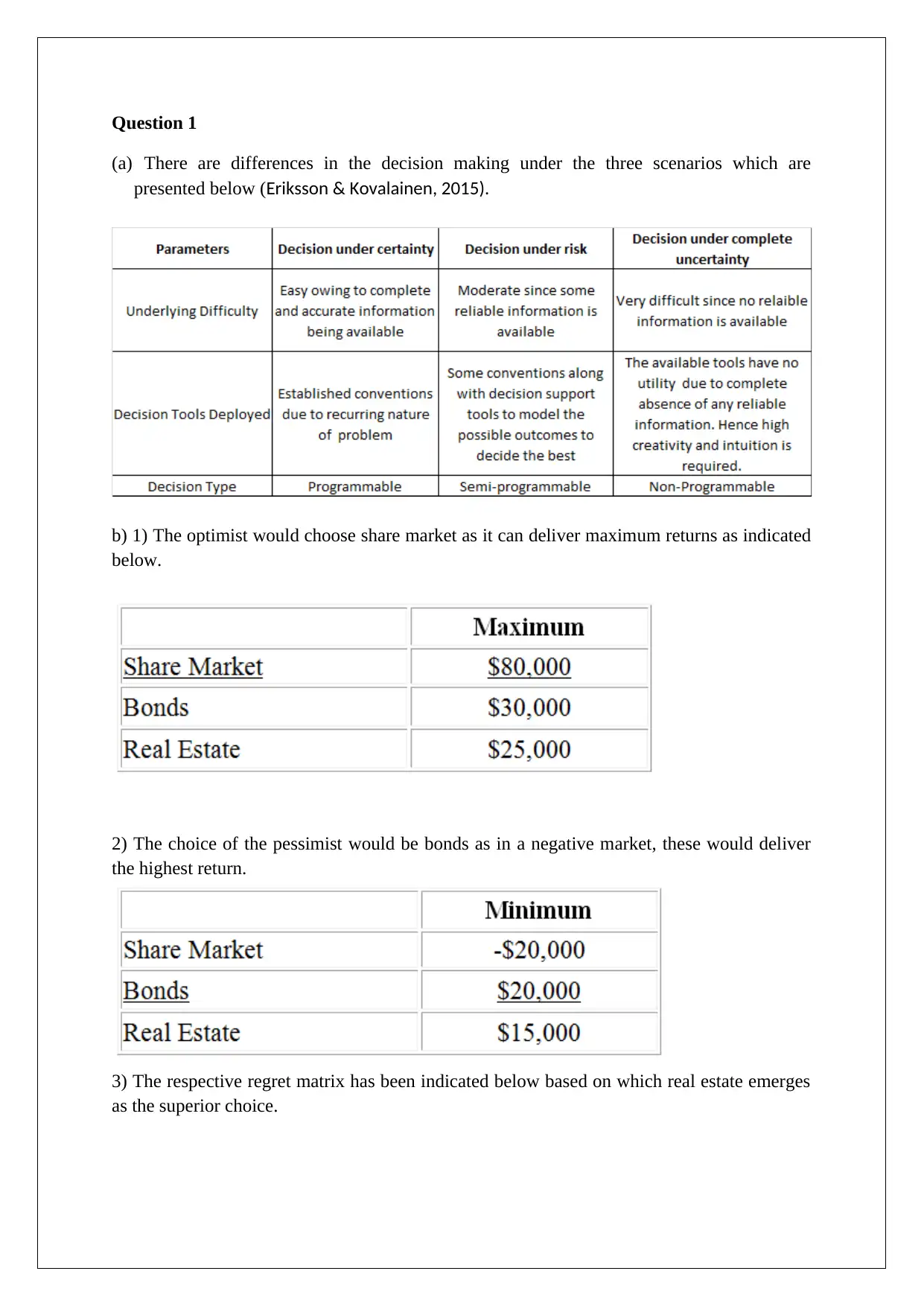
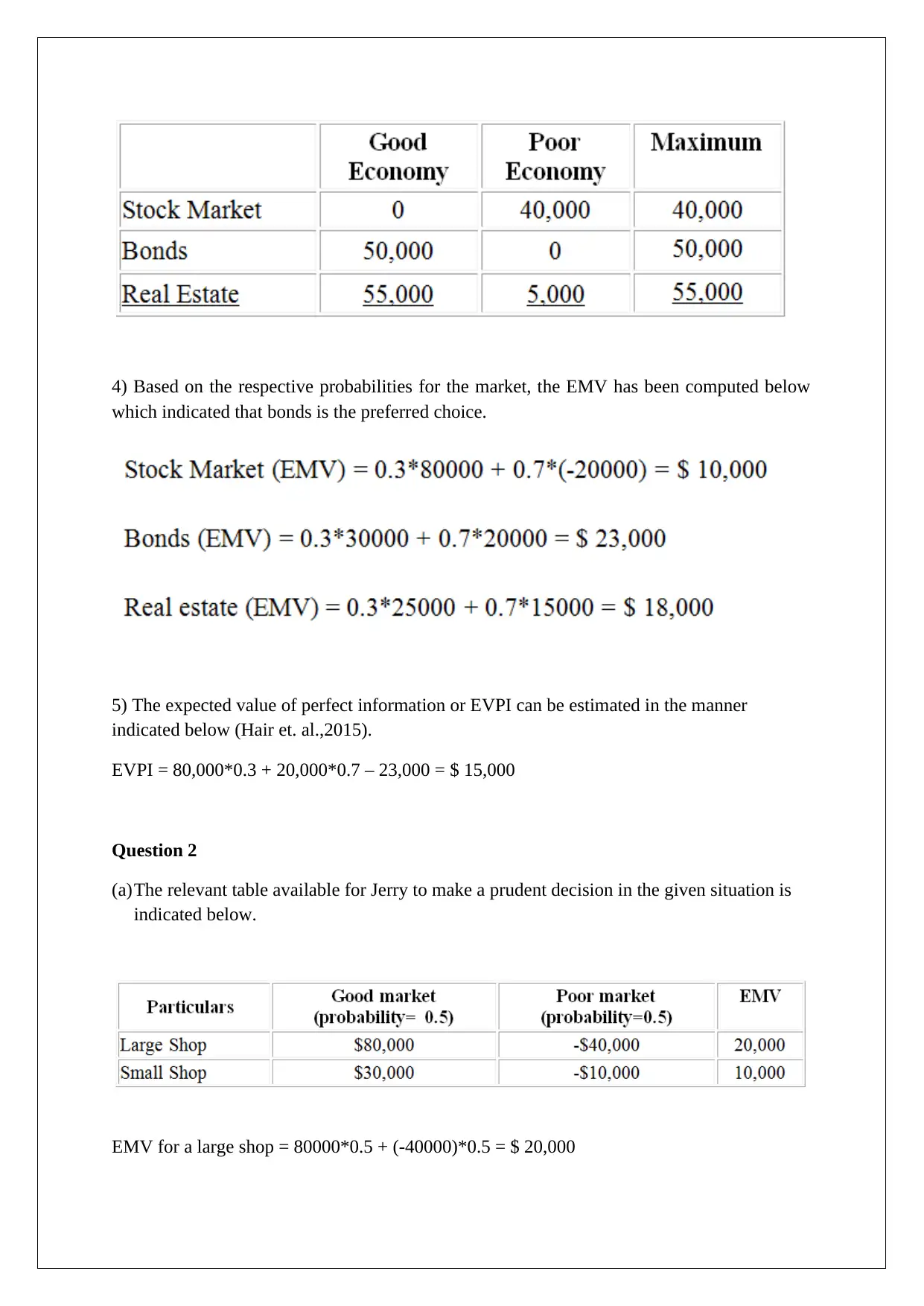
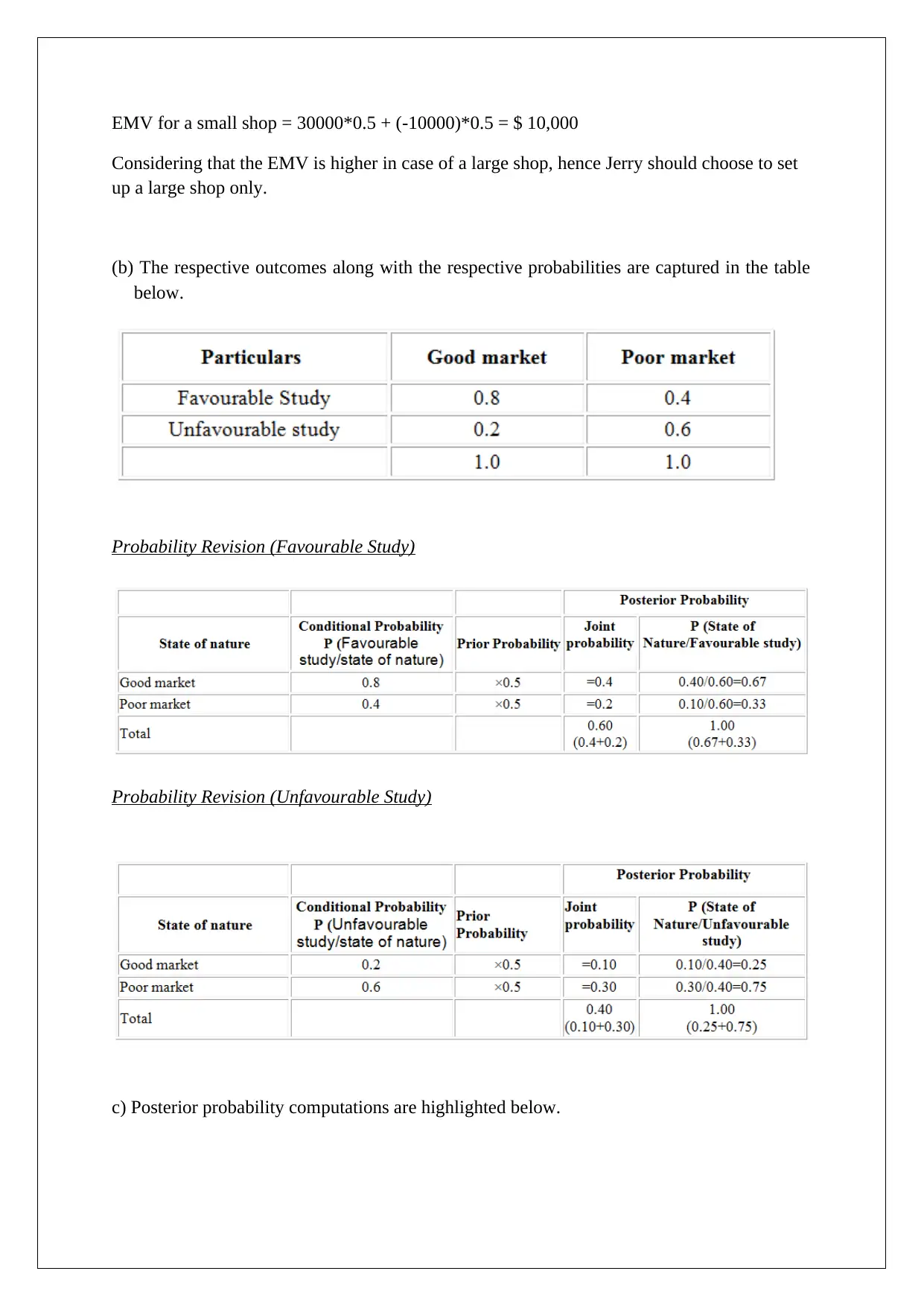
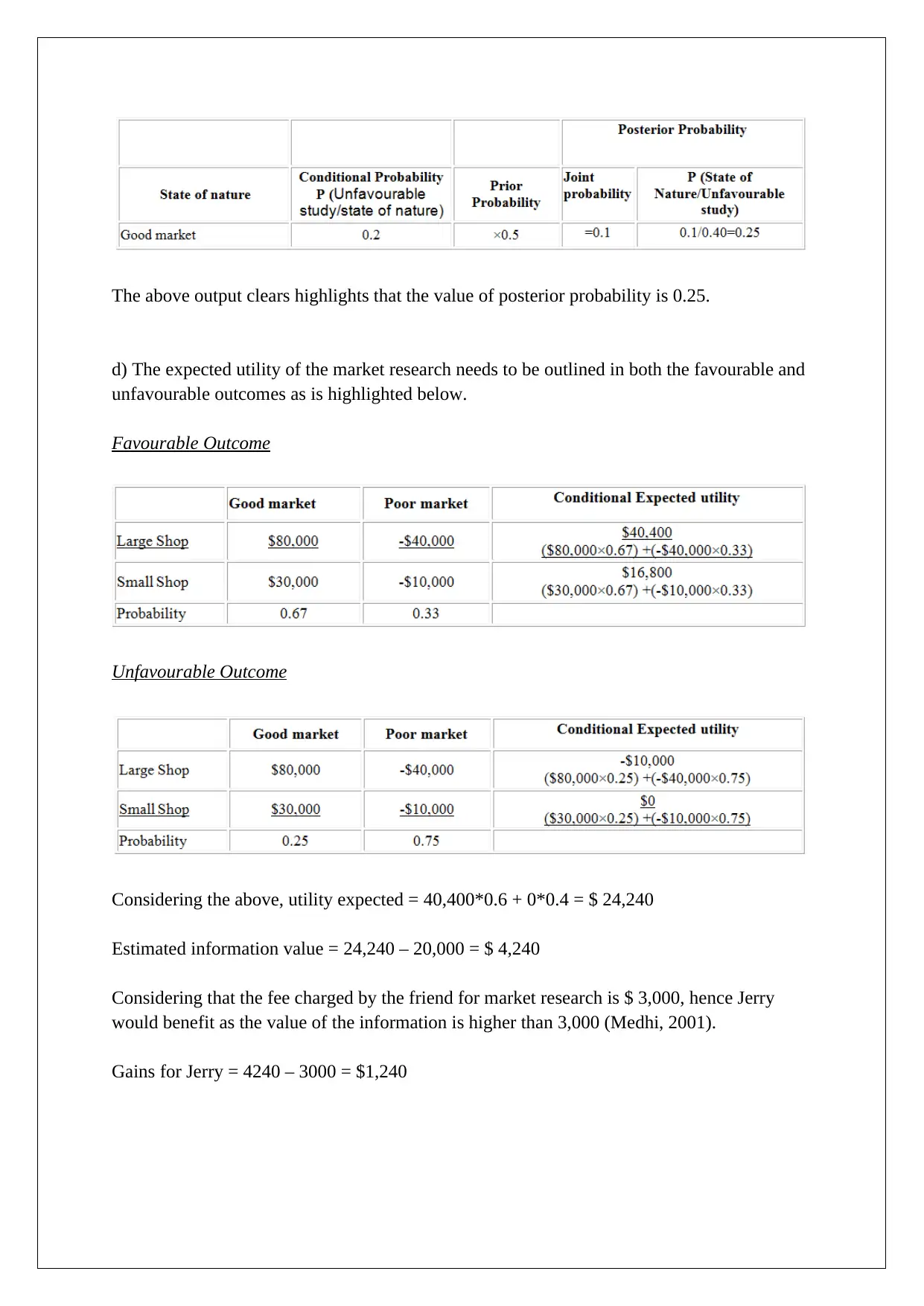
This assignment solution addresses several key concepts in decision support tools. It begins with a comparison of decision-making under different scenarios, including the application of EMV, regret matrices, and EVPI. The solution then analyzes a scenario involving market research and posterior probabilities to determine the optimal business decision. Following this, the assignment explores Monte Carlo simulation to assess the impact of price changes on profit and provides a detailed explanation of the high-low method and regression analysis, using different variables to estimate overhead costs. Finally, the solution concludes with break-even analysis for two products, considering different sales ratios and profit targets, and determining the sales volumes required to achieve specific pre- and post-tax profit levels. The assignment uses various statistical techniques and financial models to support business decision-making.





1 out of 14
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.