ACC73002 Business Analytics: Simple and Multiple Regression Analysis
VerifiedAdded on 2022/11/17
|16
|1447
|243
Homework Assignment
AI Summary
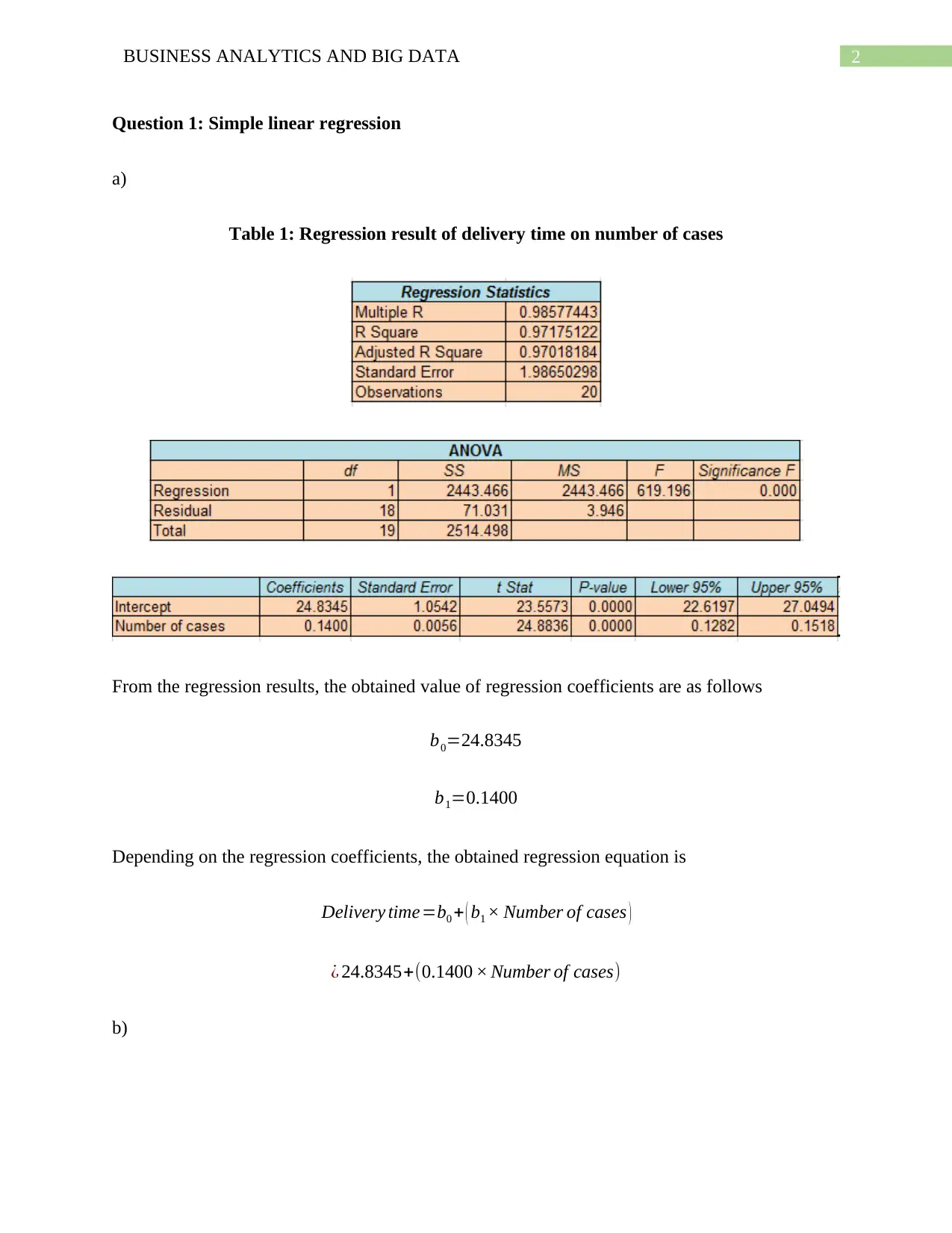
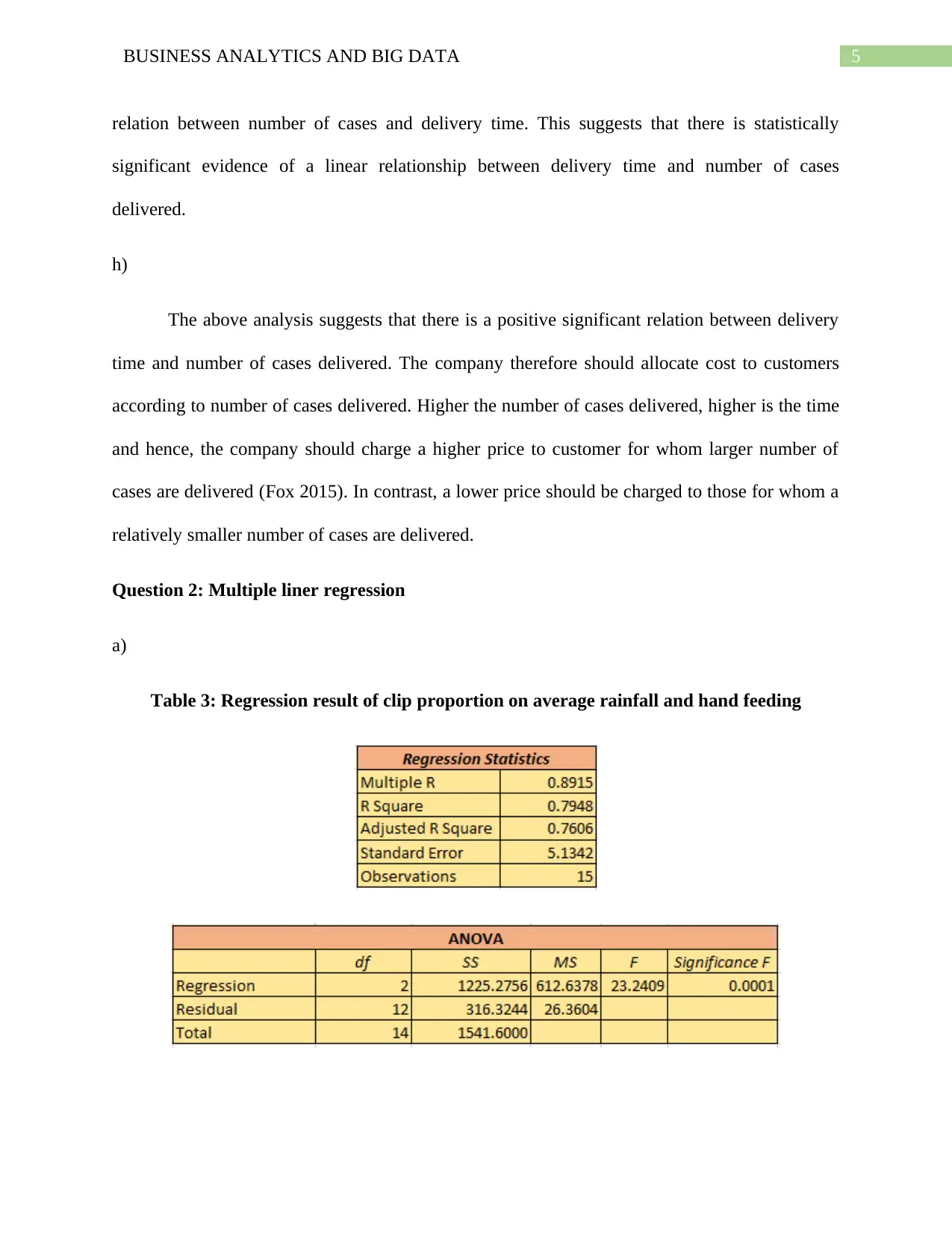
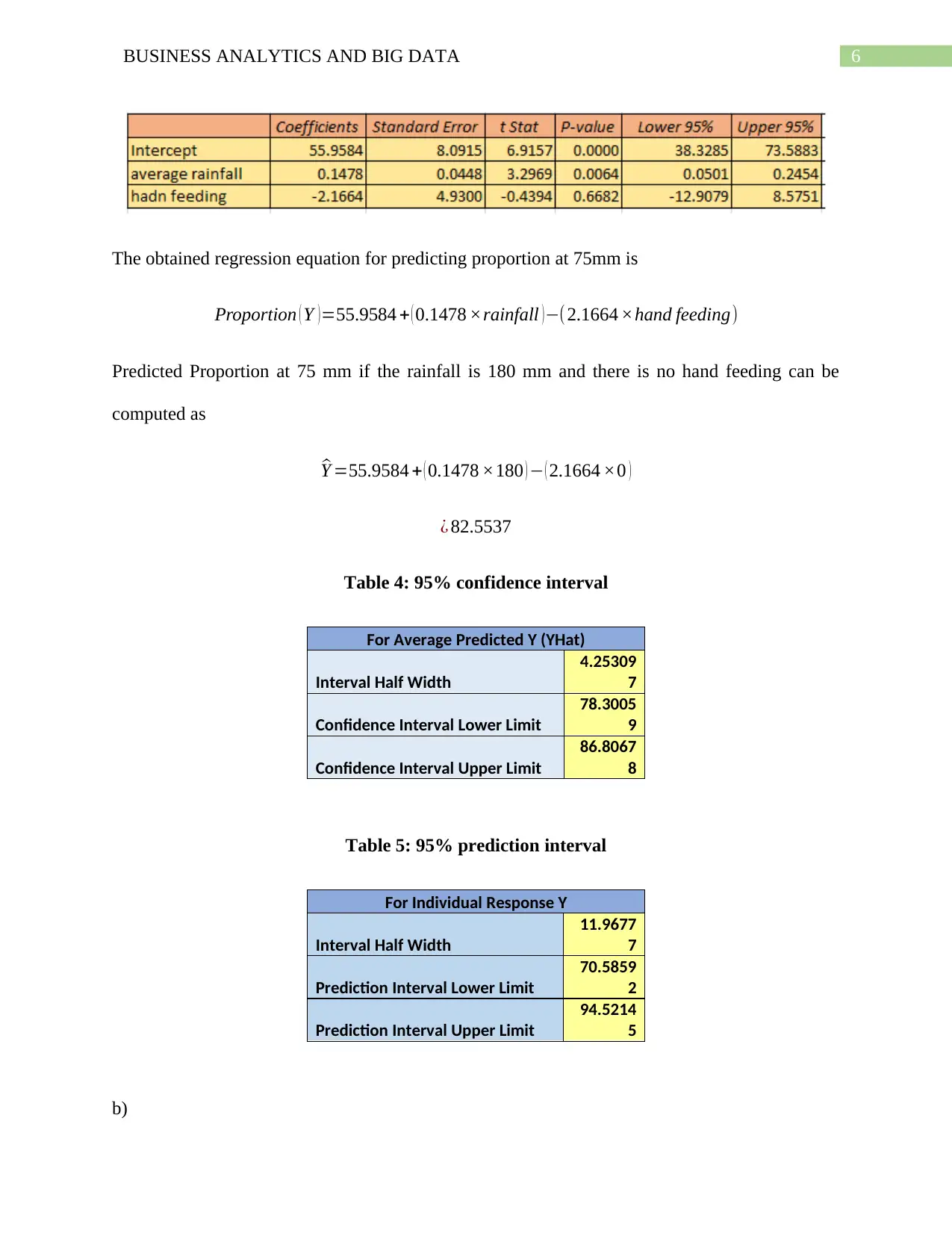
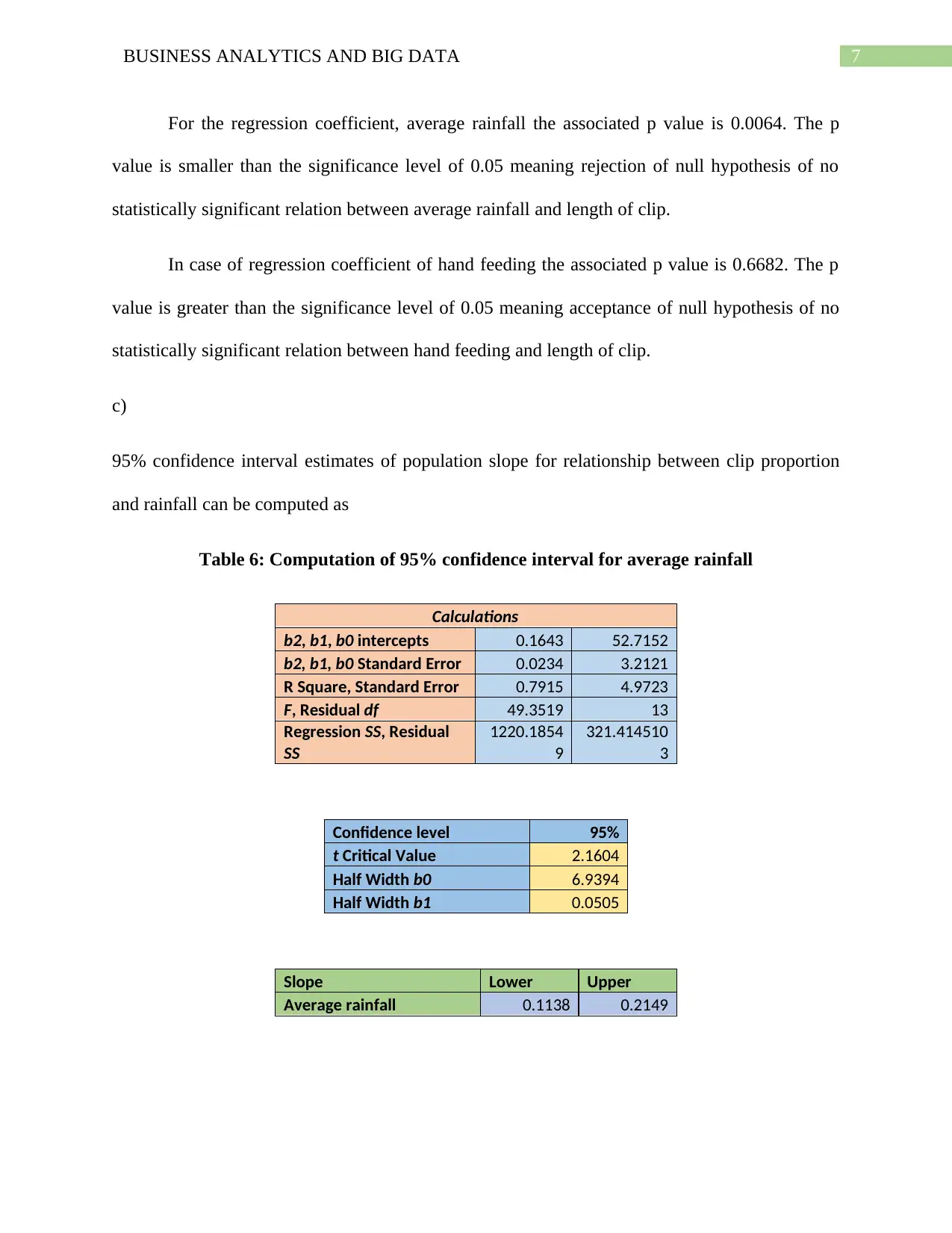
This document presents a comprehensive solution to a Business Analytics and Big Data assignment, focusing on regression analysis and business forecasting. The assignment includes three main questions. The first question explores simple linear regression, calculating regression coefficients, interpreting their meaning, predicting delivery time, and evaluating the model's suitability for different scenarios. The second question delves into multiple linear regression, examining the impact of multiple variables on clip proportion, calculating confidence intervals, and interpreting coefficients of partial determination. The third question focuses on business forecasting using linear trend equations to forecast employment figures. The solution provides detailed calculations, interpretations, and graphical representations to support the analysis, offering a thorough understanding of regression techniques and their application in business contexts.




1 out of 16
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.