Semester Project: Business Intelligence Report Analysis
VerifiedAdded on 2023/04/03
|29
|3445
|100
Report
AI Summary
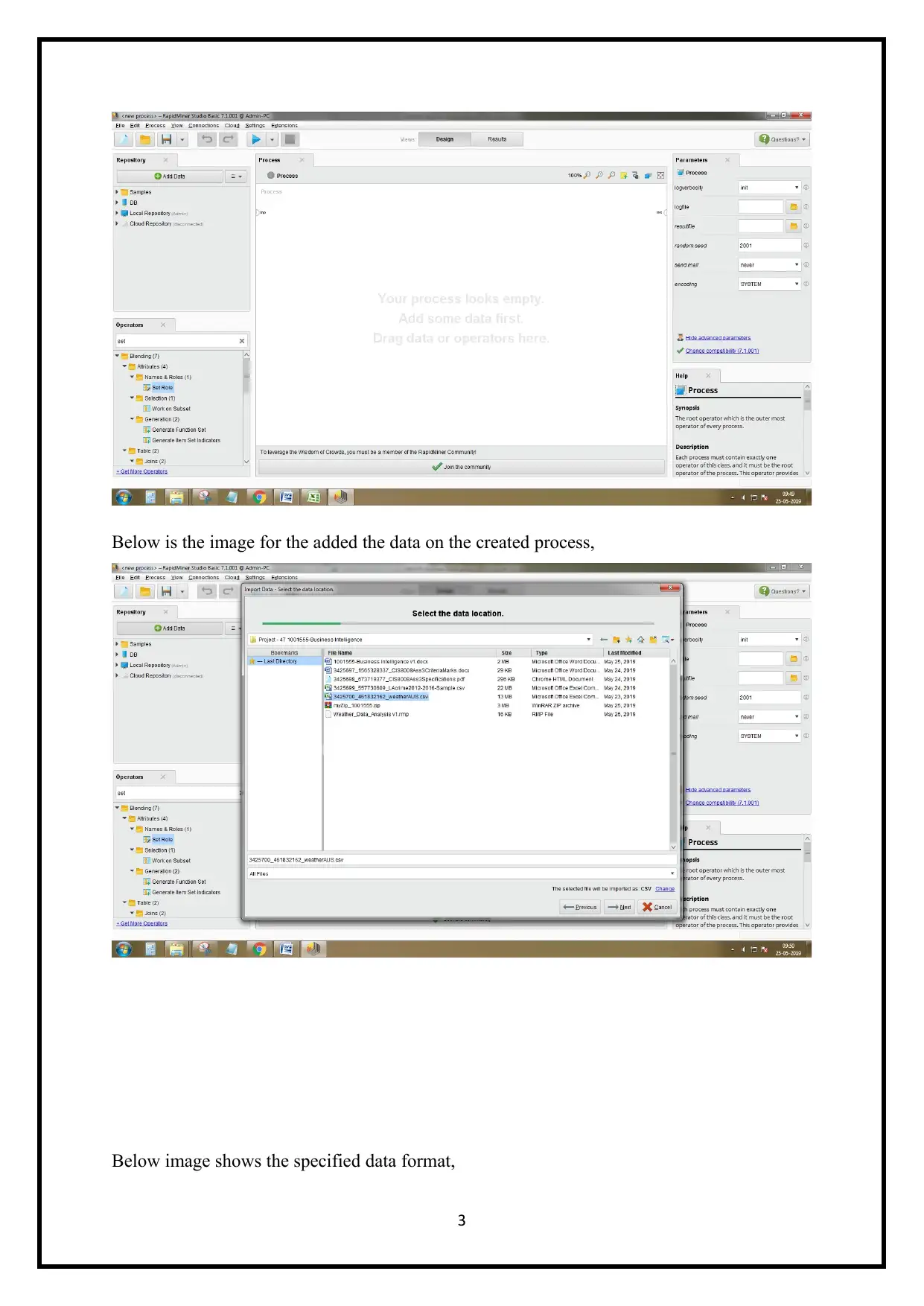
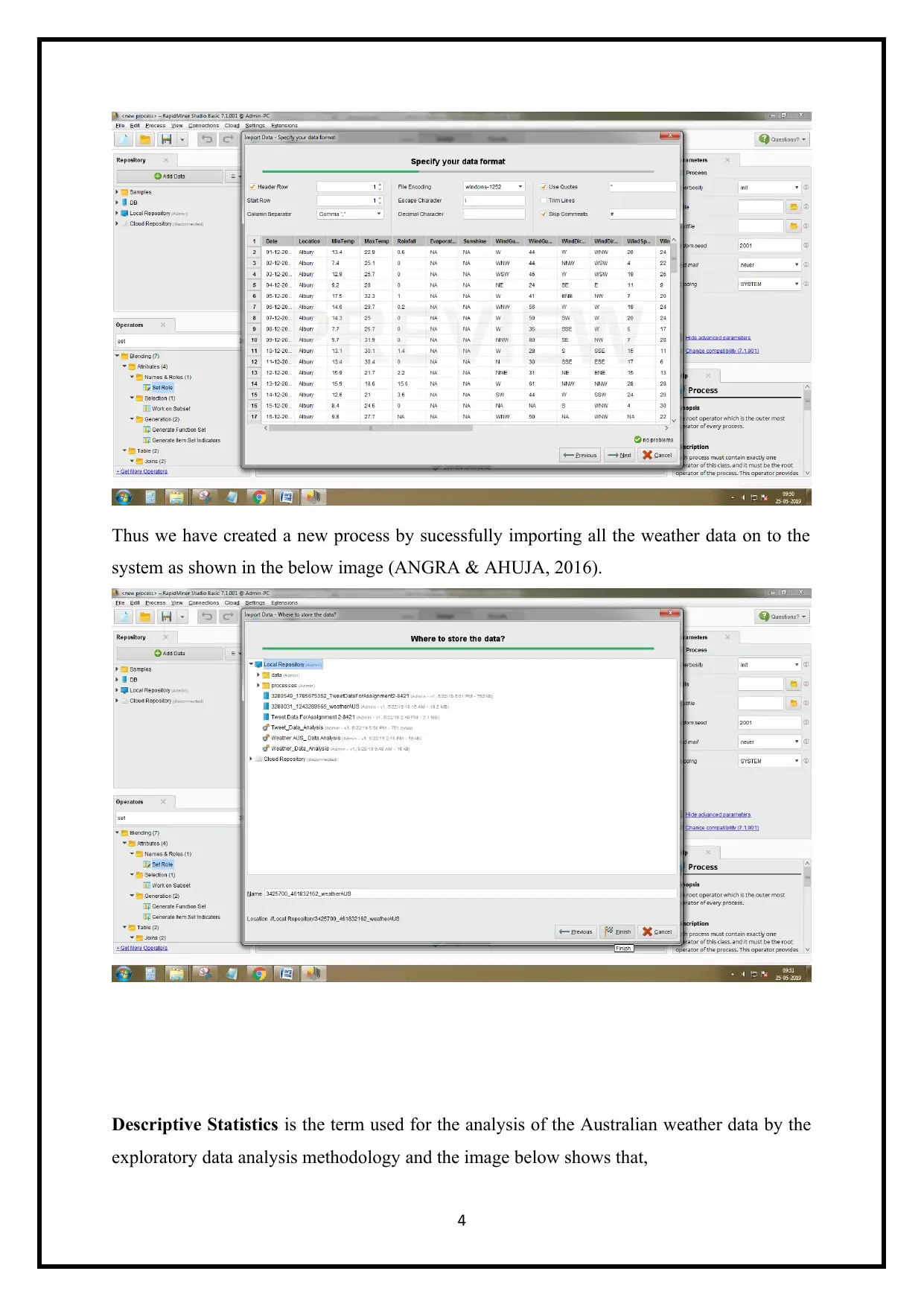
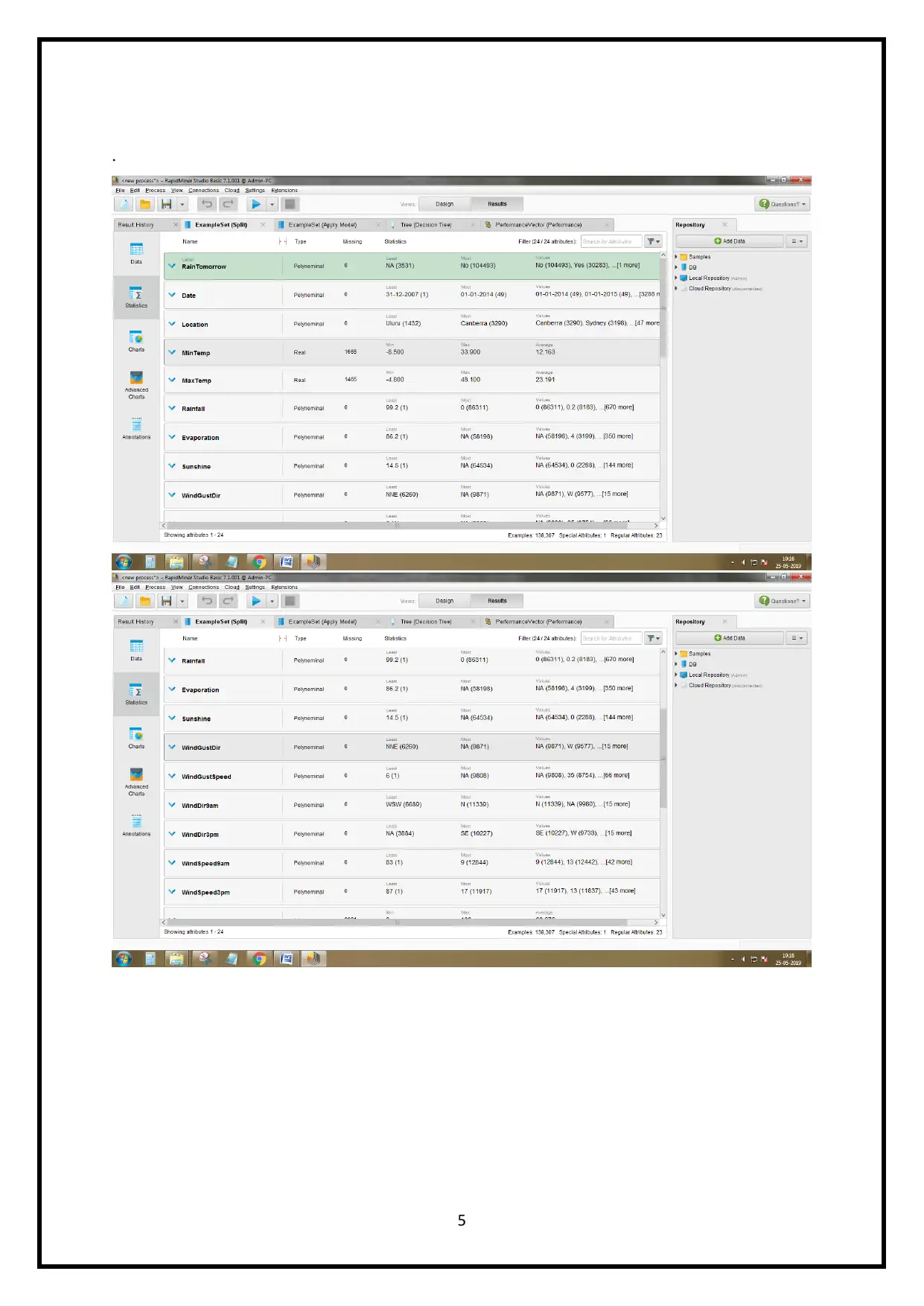
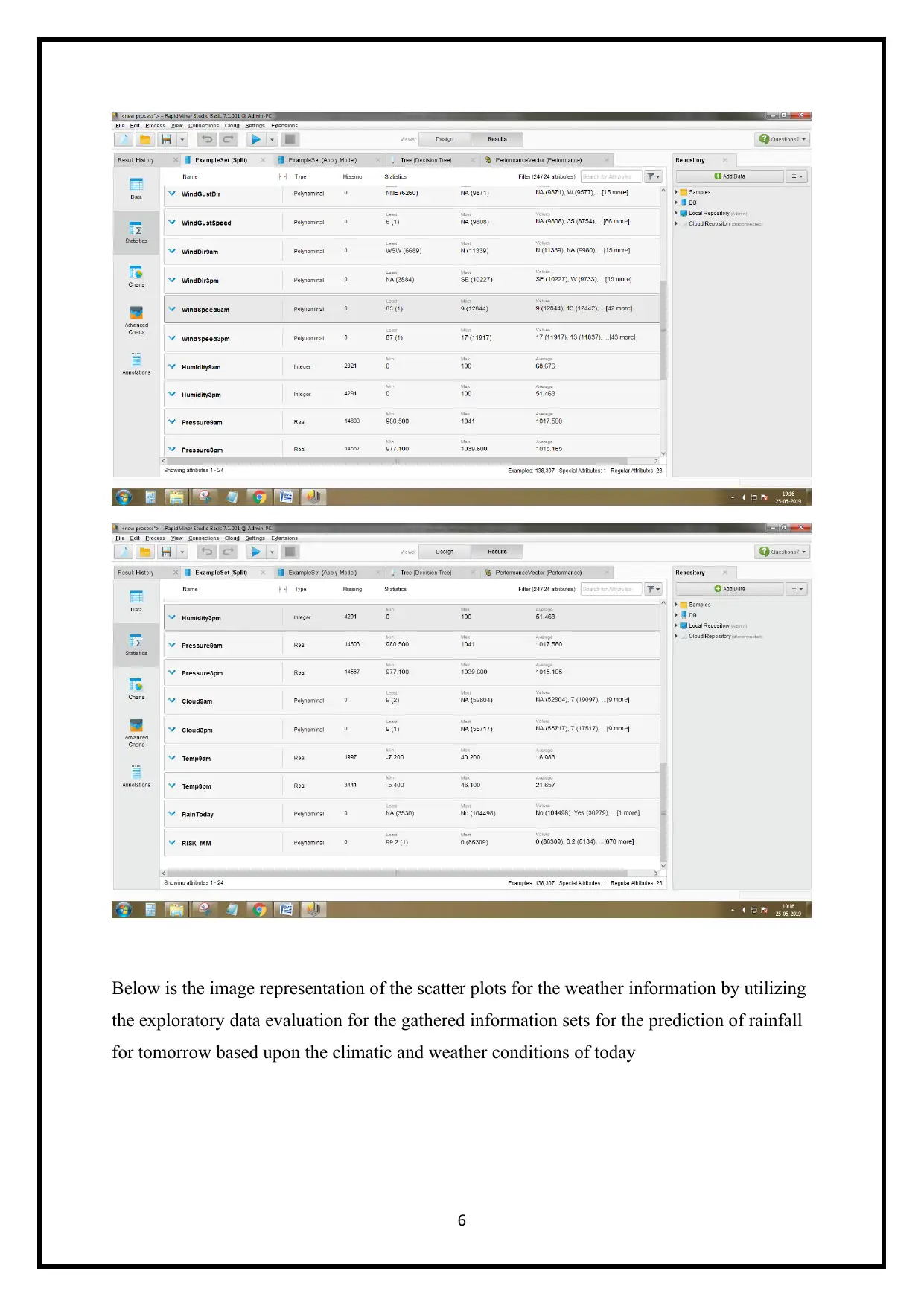
This report details a Business Intelligence project undertaken using RapidMiner to analyze Australian weather data. The project is divided into three tasks. Task 1 focuses on exploratory data analysis, decision tree modeling, and logistic regression modeling to predict rainfall. Task 2 involves researching and designing a high-level data warehouse architecture, including its main components and ethical considerations. Task 3 entails creating a crime dataset for a scenario dashboard. The report includes detailed explanations of each step, including the use of RapidMiner for data preparation, model building, and validation, as well as a discussion of data warehouse design and security concerns. The project aims to apply business intelligence techniques to solve real-world problems, demonstrating the practical application of data mining and data warehousing principles.





1 out of 29


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.