Business Intelligence Report: Data Mining, AI, and Weka Analysis
VerifiedAdded on 2021/06/18
|20
|3036
|86
Report
AI Summary
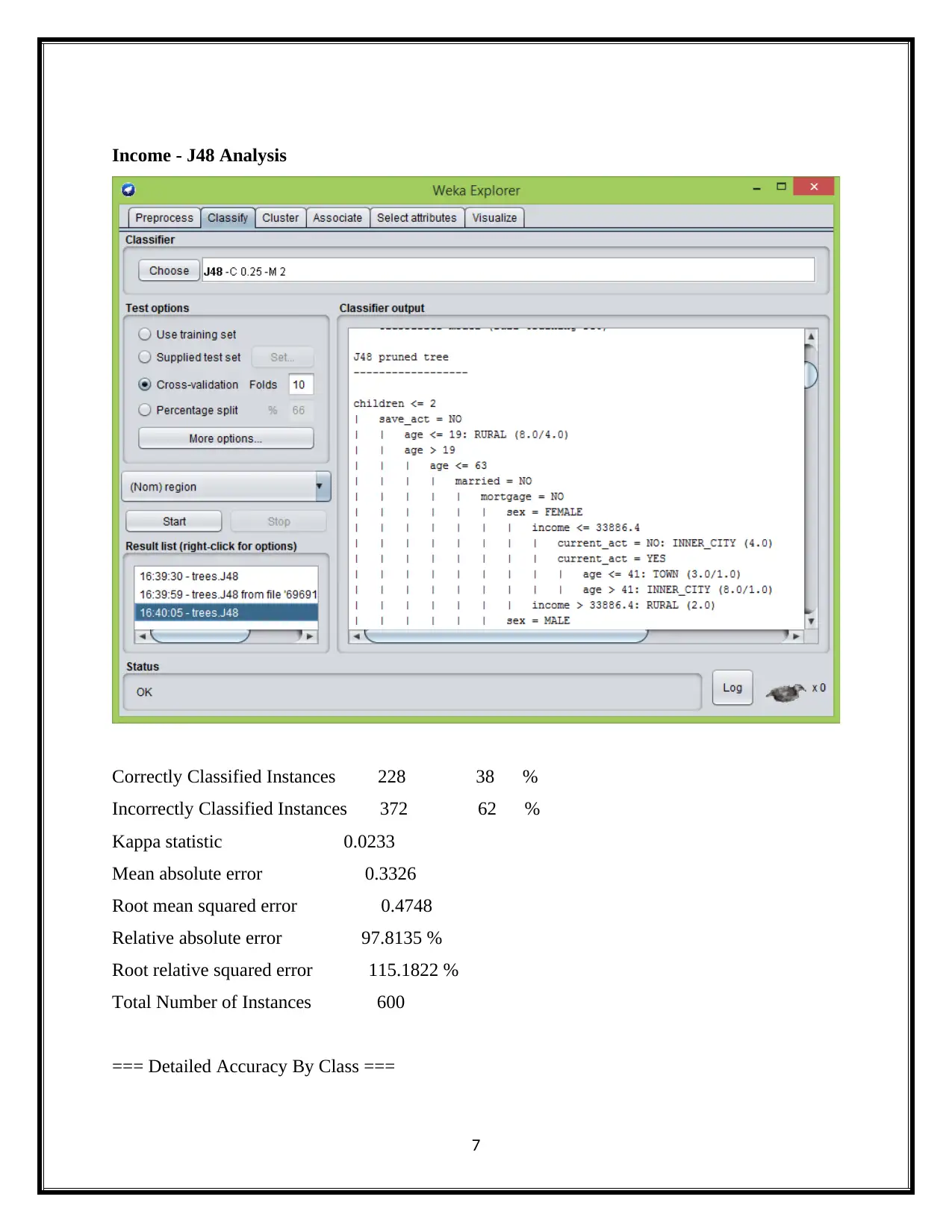
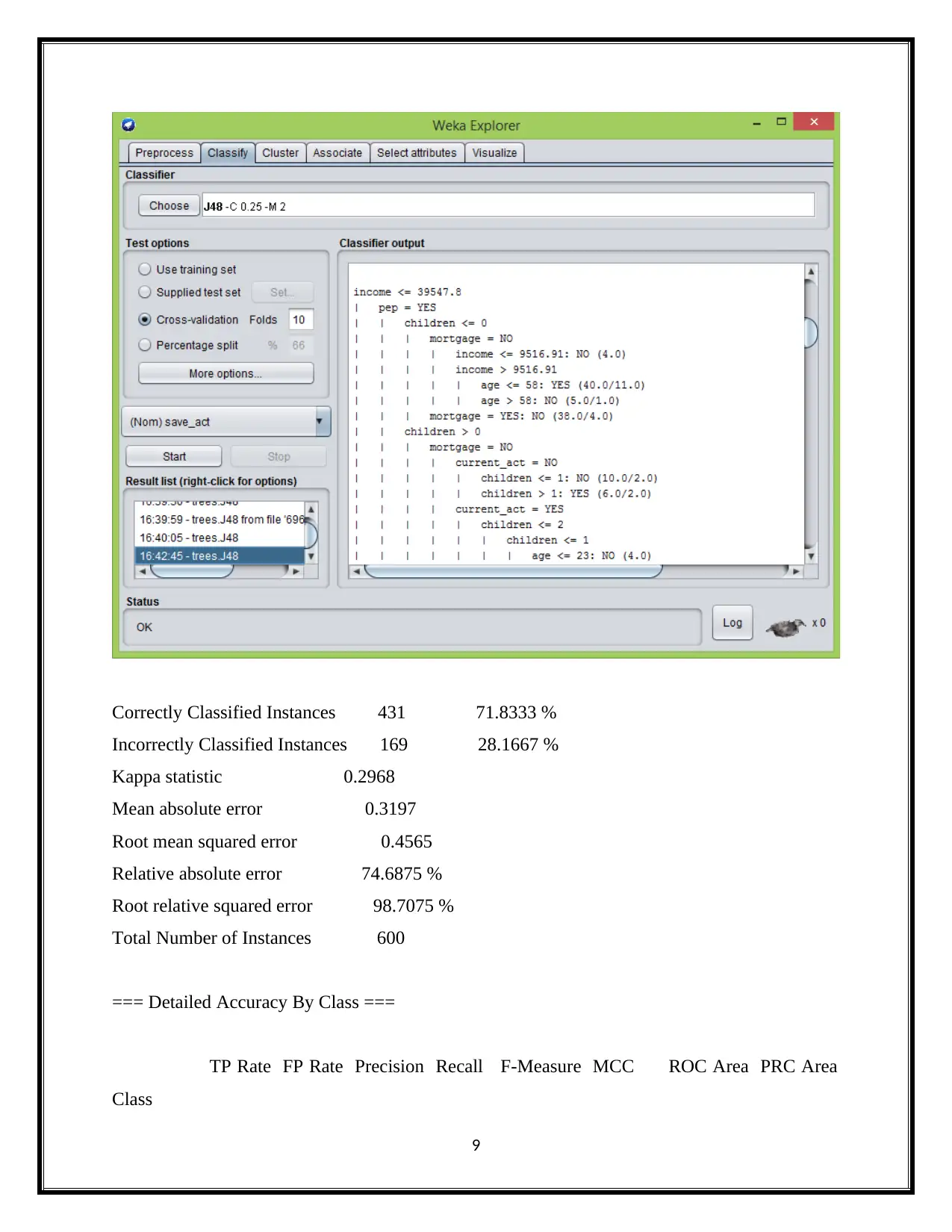
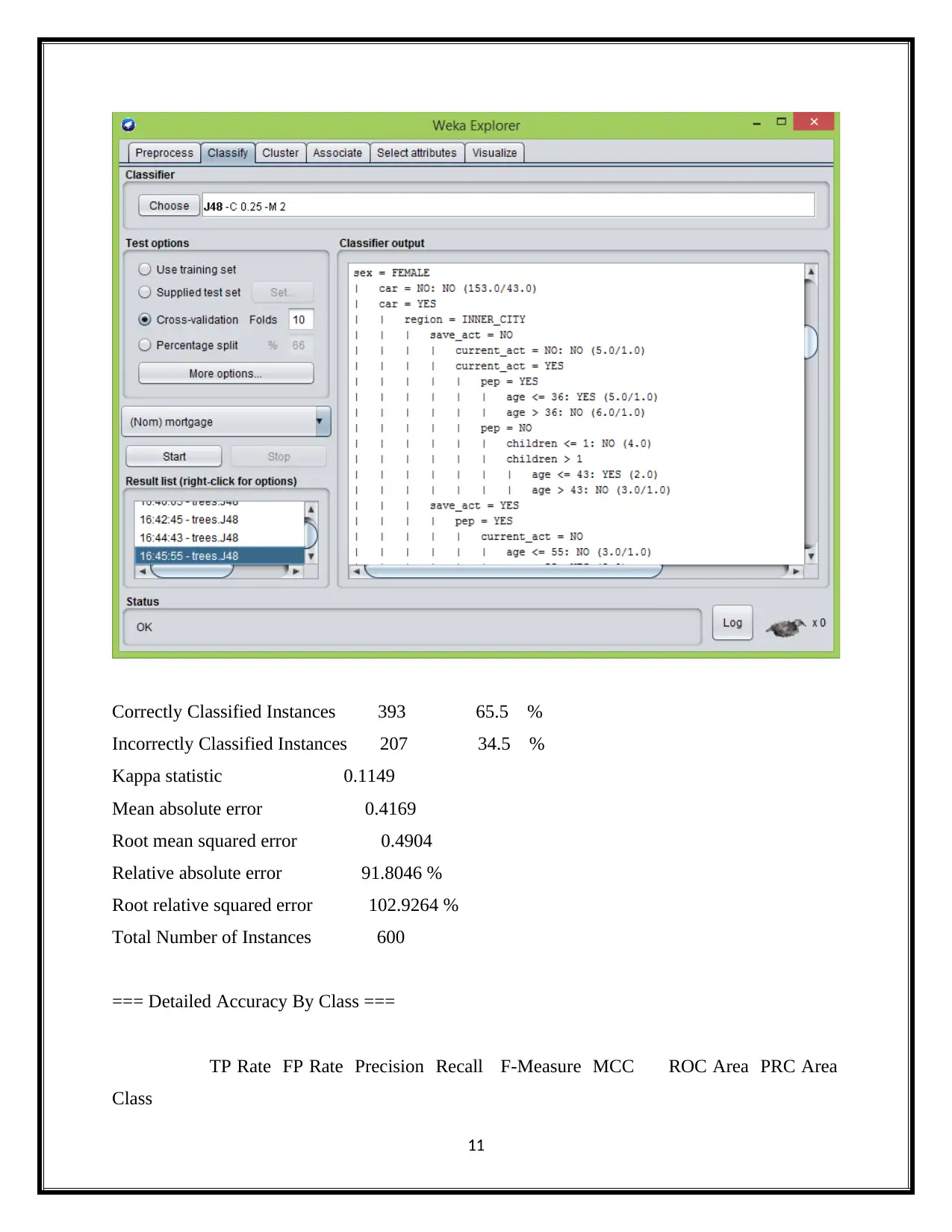
This report delves into the realm of business intelligence, commencing with a comprehensive definition of text mining and text analytics, highlighting their role in extracting valuable insights from unstructured data. It then differentiates text mining from data mining, elucidating their distinct methodologies and applications. The report further explores the application of Artificial Intelligence (AI) in business transformation, emphasizing its capacity to automate tasks, enhance existing systems, and drive data-driven decision-making. A significant portion of the report is dedicated to data analysis, utilizing the Weka data mining tool and the J48 algorithm to analyze bank data, including attributes like income, savings, current accounts, mortgage, and sex. The analysis provides detailed insights into these attributes, supported by the J48 algorithm's classification results, confusion matrices, and accuracy metrics. Finally, the report touches upon the importance of dashboards in visualizing and interpreting the analyzed data, providing a holistic overview of business intelligence concepts and techniques. The report provides a detailed overview of the data analysis process, including data pre-processing, model selection, and evaluation, with specific attention to the J48 decision tree algorithm and its application to the bank data.







1 out of 20
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.