King's Own Institute BUS105 Business Statistics Assignment
VerifiedAdded on 2023/03/17
|8
|1861
|83
Homework Assignment
AI Summary
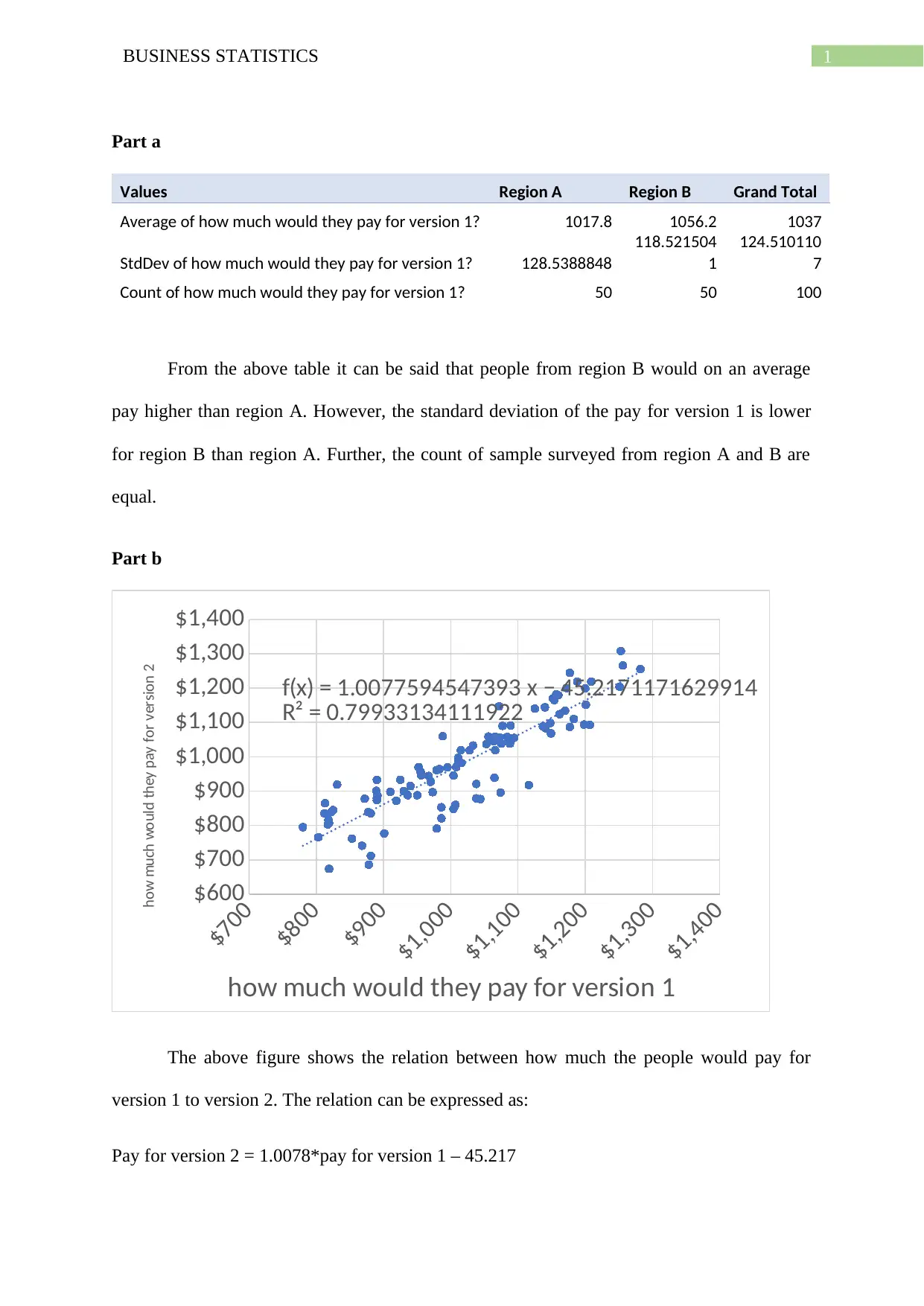
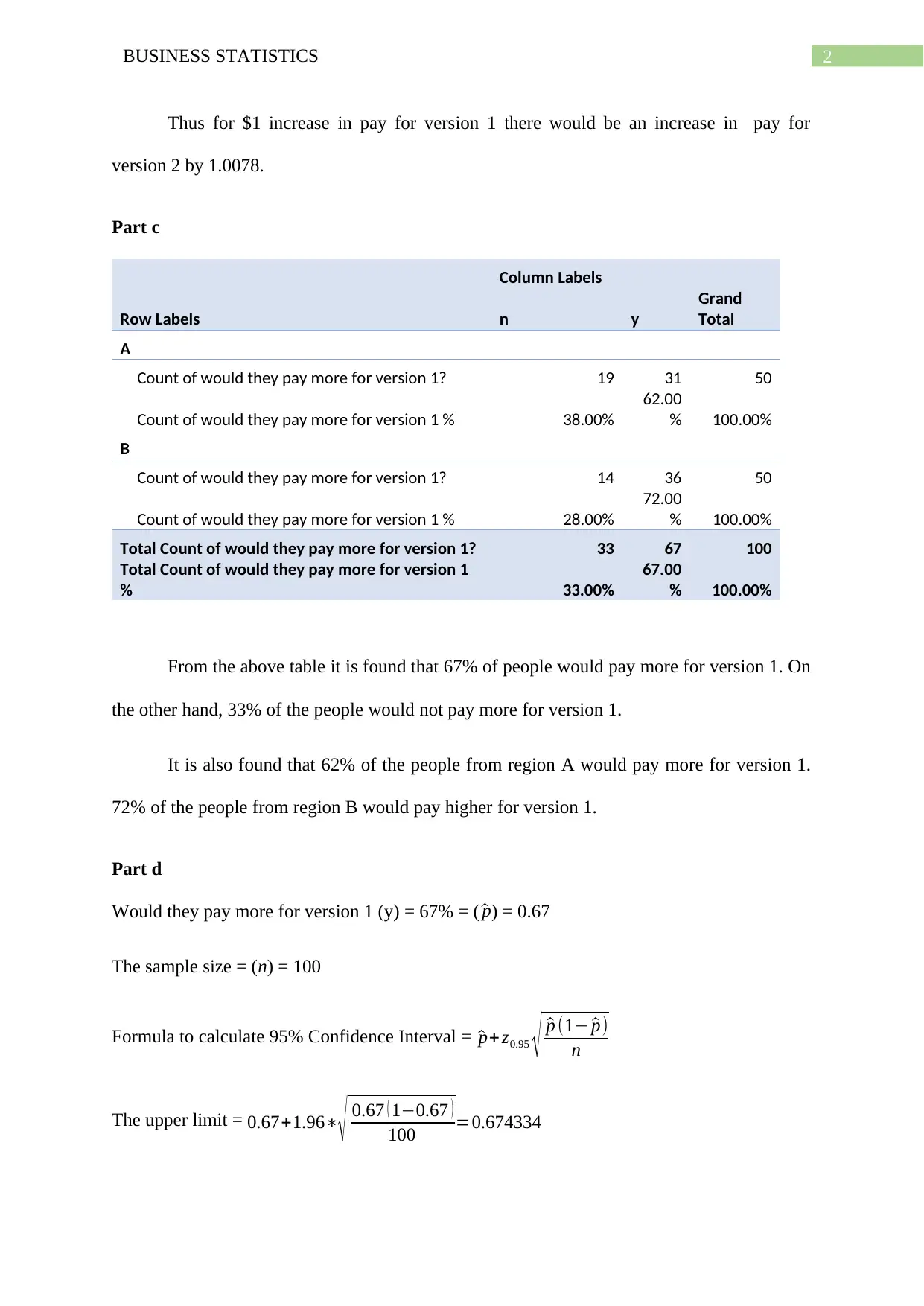
This business statistics assignment analyzes market research data on laptop preferences, examining how much potential buyers would pay for different versions of a laptop across two regions. The analysis includes descriptive statistics (averages, standard deviations), a regression analysis of price relationships, and hypothesis testing to compare willingness to pay between regions. The assignment investigates the relationship between paying more for version 1 and version 2. It also explores confidence intervals, p-values, and the impact of lurking variables on the observed relationships. The solution also discusses how to formulate research questions, methodologies, and data analysis approaches for a business report. The assignment also covers the identification of various variable types, like independent and dependent variables and their impact on the study. Finally, it delves into the process of creating a business report based on the statistical analysis conducted.






1 out of 8
Related Documents




Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.