Business Statistics Assignment: Analysis, Probability, and Solutions
VerifiedAdded on 2020/02/24
|17
|2130
|368
Homework Assignment
AI Summary
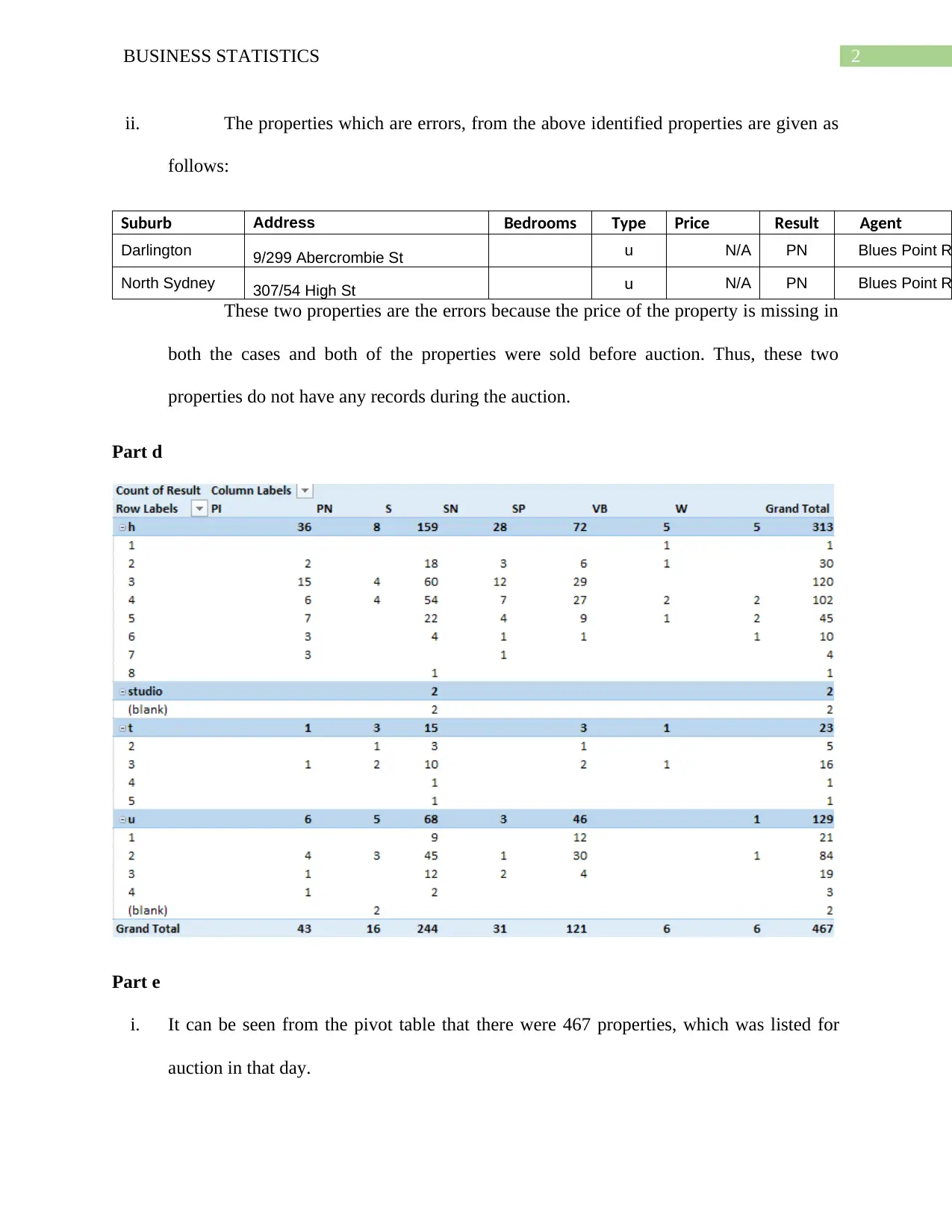
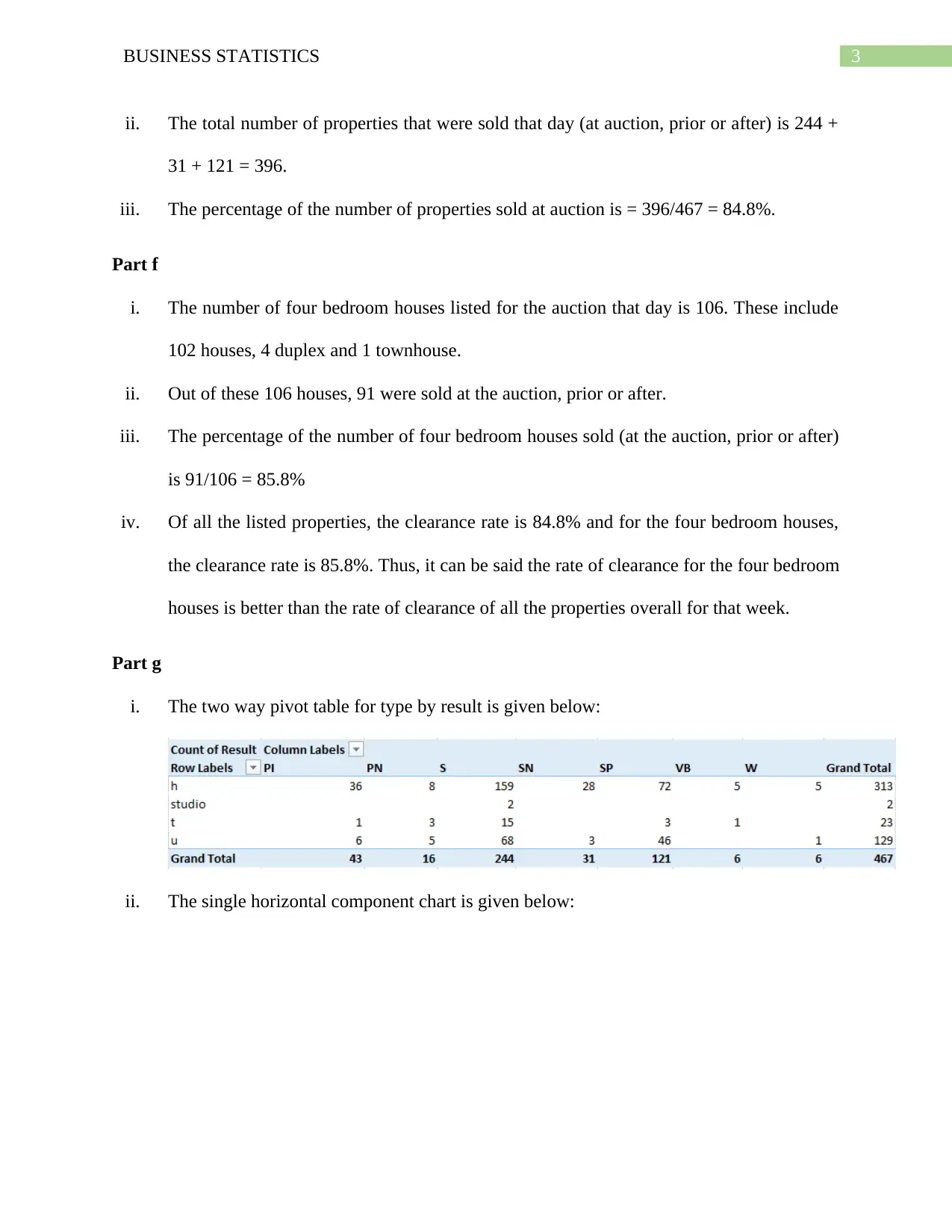
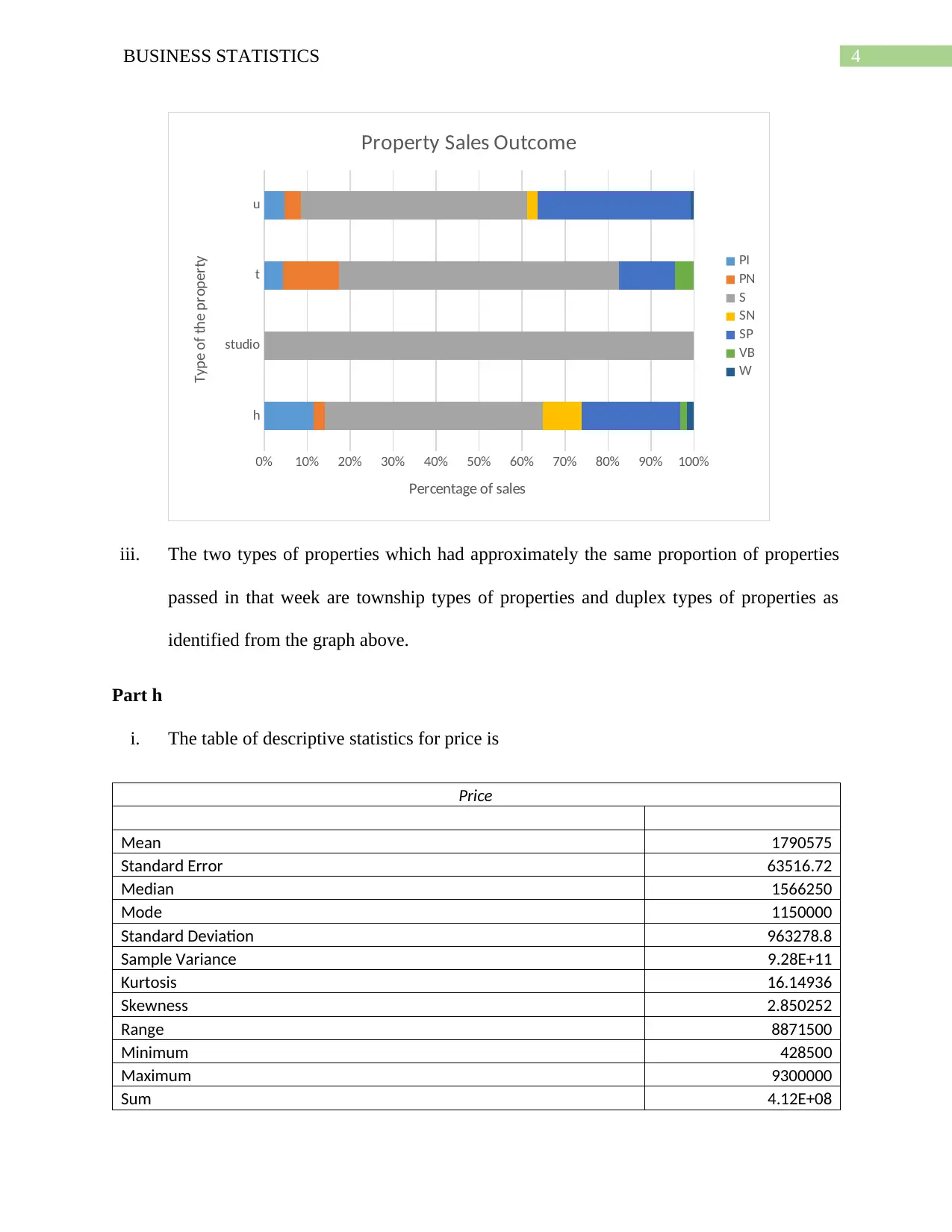
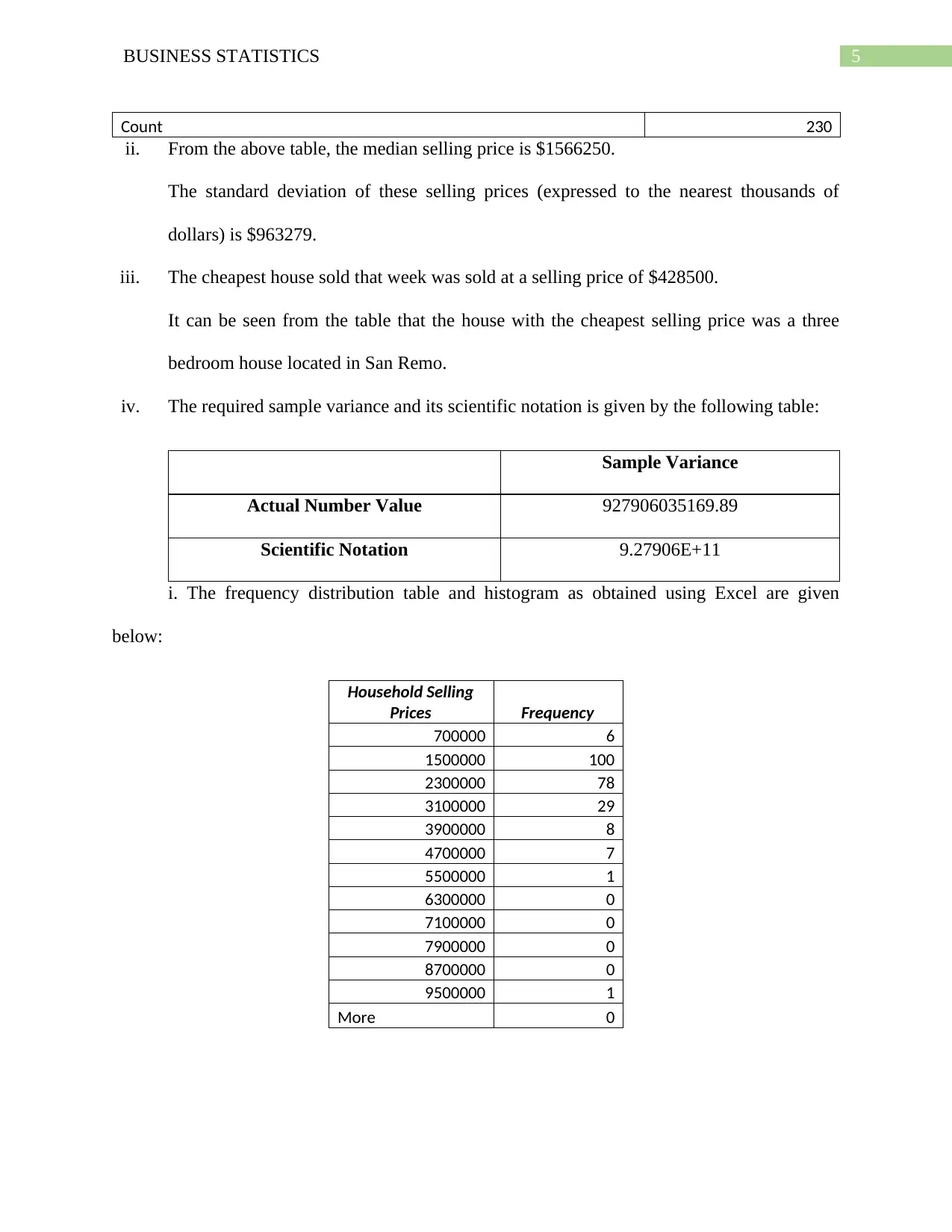
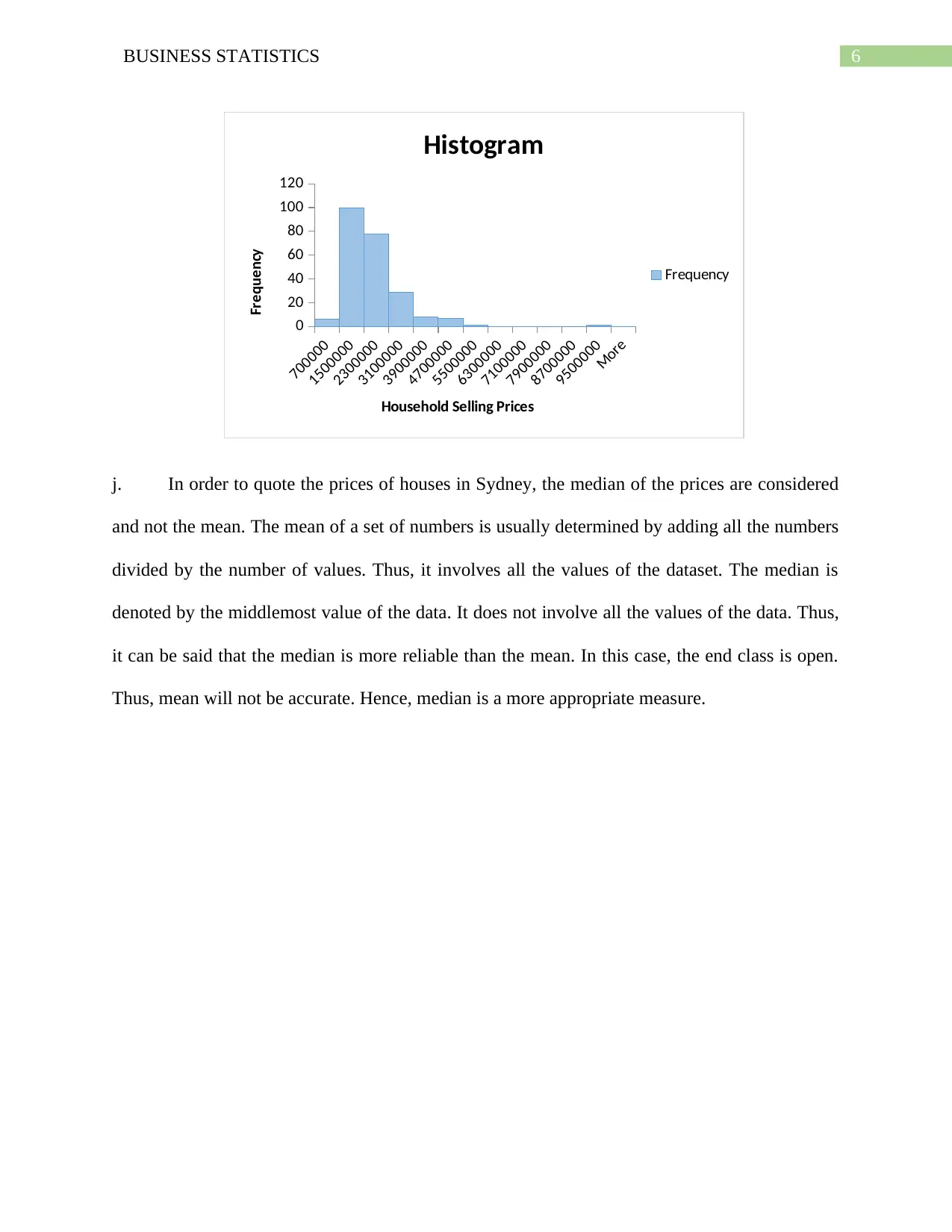
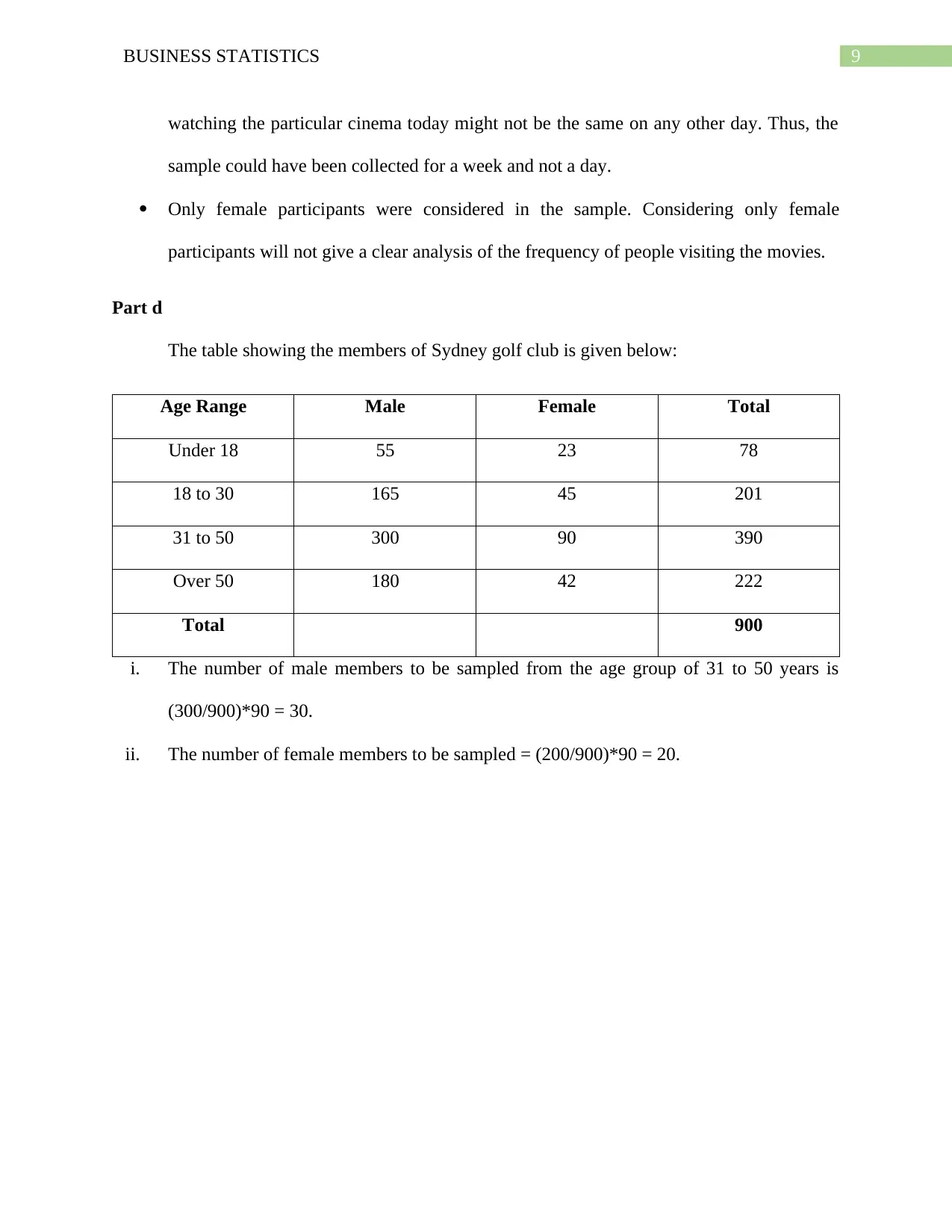
This business statistics assignment solution covers a range of topics, including data analysis, probability, and statistical distributions. The assignment begins with an analysis of qualitative and quantitative variables from a dataset, including identifying errors and calculating clearance rates for properties. It then delves into probability calculations using binomial and Poisson distributions, analyzing scenarios such as car repairs and emergency calls. Furthermore, the assignment explores normal distributions, calculating probabilities related to tire lifespan and customer satisfaction. The solution provides detailed explanations and calculations for each problem, including pivot tables, frequency distributions, and the application of statistical formulas. The assignment also provides a comparison between the mean and the median in quoting prices of houses in Sydney, as well as an analysis of the bias in a sample of people who watch movies. The document also includes the application of probability trees and the analysis of the independence of events. The solution encompasses a wide array of statistical concepts, offering a comprehensive understanding of the subject matter.






1 out of 17


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.