Data Analysis and Statistical Report: Coffee Shop Performance Analysis
VerifiedAdded on 2022/12/29
|7
|1648
|37
Report
AI Summary
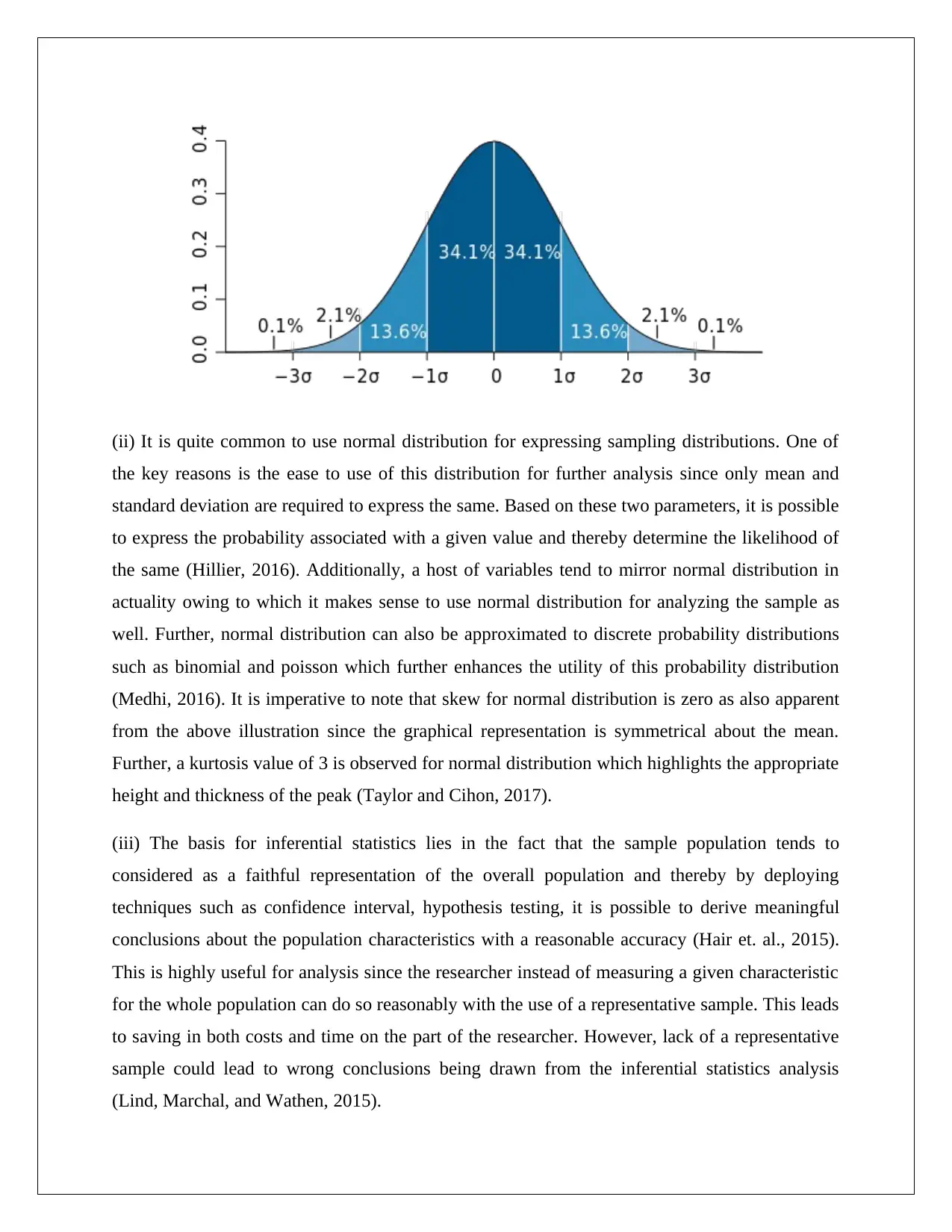
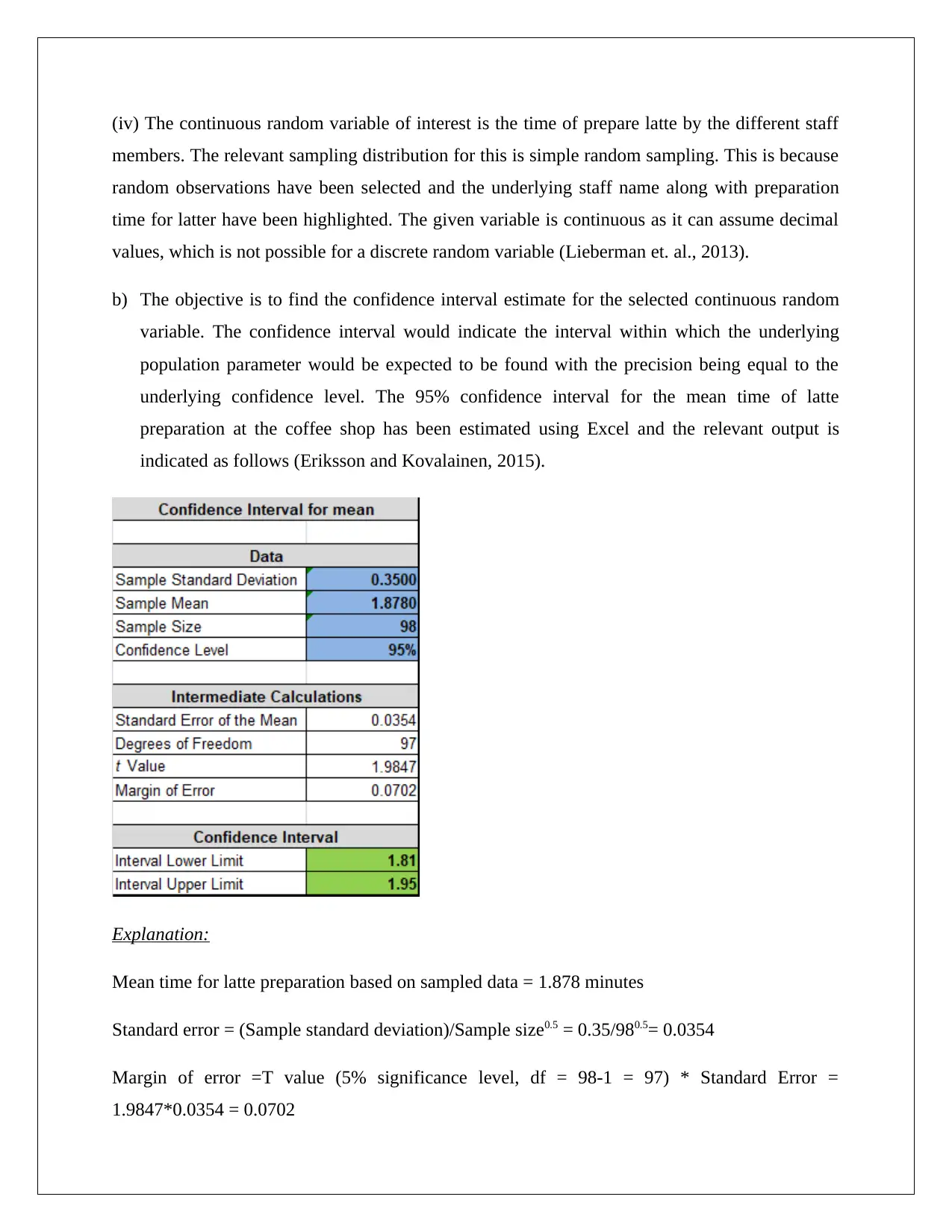
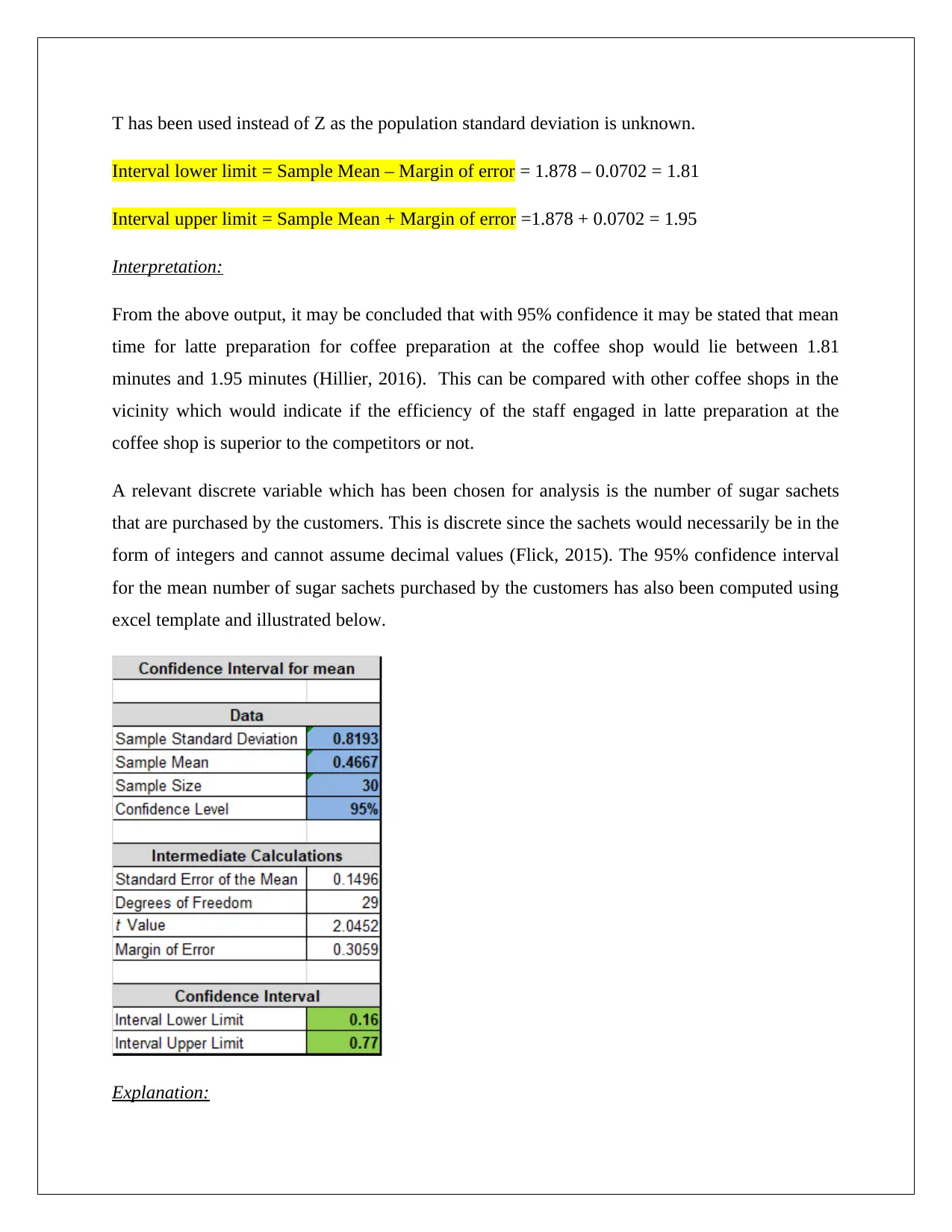
This report presents a data analysis of a coffee shop's business activities, focusing on food preparation time and customer behavior. The analysis utilizes statistical techniques, including the application of normal distribution and confidence intervals, to derive meaningful conclusions. The report examines a continuous random variable, latte preparation time, and a discrete variable, sugar sachet purchases, providing confidence interval estimates for their means. The findings suggest that the average latte preparation time falls between 1.81 and 1.95 minutes with 95% confidence, and the average sugar sachet purchase per order ranges from 0.16 to 0.77 with 95% confidence. This information can assist the coffee shop management in evaluating staff efficiency, managing inventory, and making informed business decisions. The report also provides a theoretical background on normal distribution and inferential statistics, explaining their significance in data analysis.




1 out of 7
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.