MITS6002 Business Analytics: CommBank Retail Report & Regression
VerifiedAdded on 2022/10/10
|8
|1662
|5
Homework Assignment
AI Summary
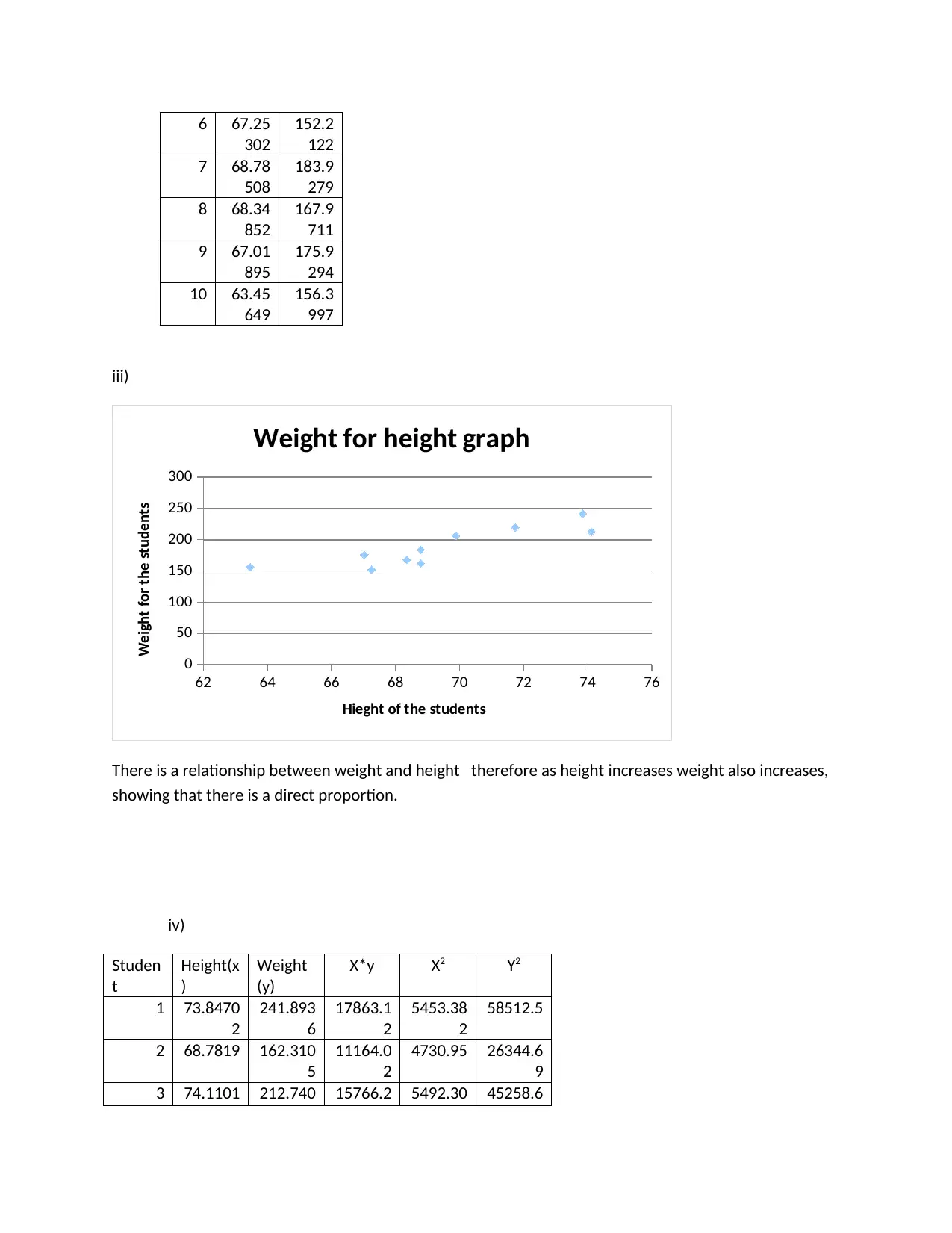
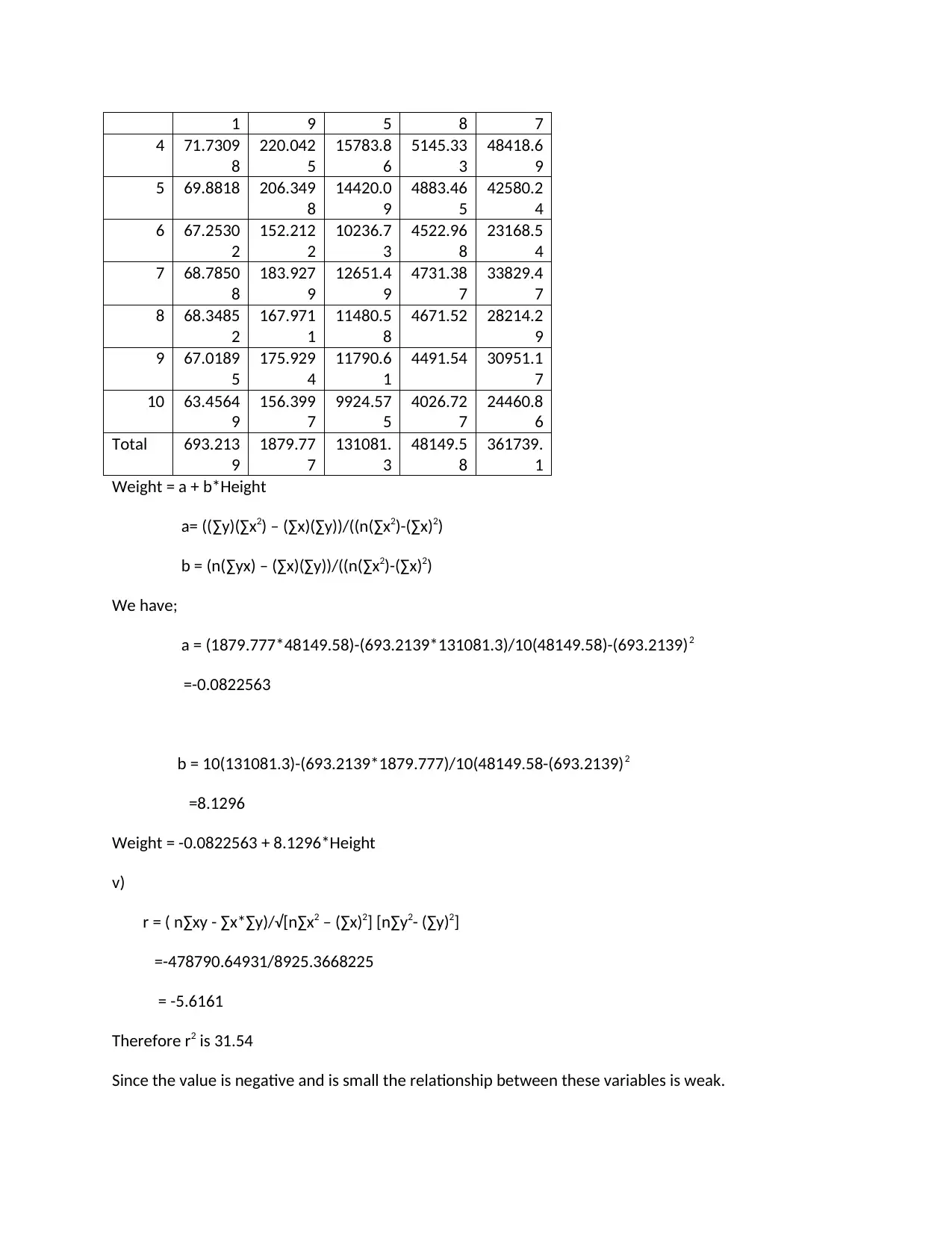
This assignment solution provides an analysis of the CommBank Retail Business Insights Report, focusing on visualization quality, presentability, and information relevance for decision-making. It summarizes the report's key findings regarding innovation in the retail sector and suggests improvements for future reports. Additionally, the solution includes a regression analysis using provided height and weight data, computing the regression line equation, R-squared value, and interpreting the relationship between the variables. The assignment further explores classification and prediction concepts, including neural networks, and provides examples of clustering applications in retail and IT sectors. The solution also provides an algebraic equation for a neural network with one hidden layer.






1 out of 8
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.