KOI ICT201: Computer Organization and Architecture Deadlock Analysis
VerifiedAdded on 2022/09/27
|9
|1651
|25
Homework Assignment
AI Summary
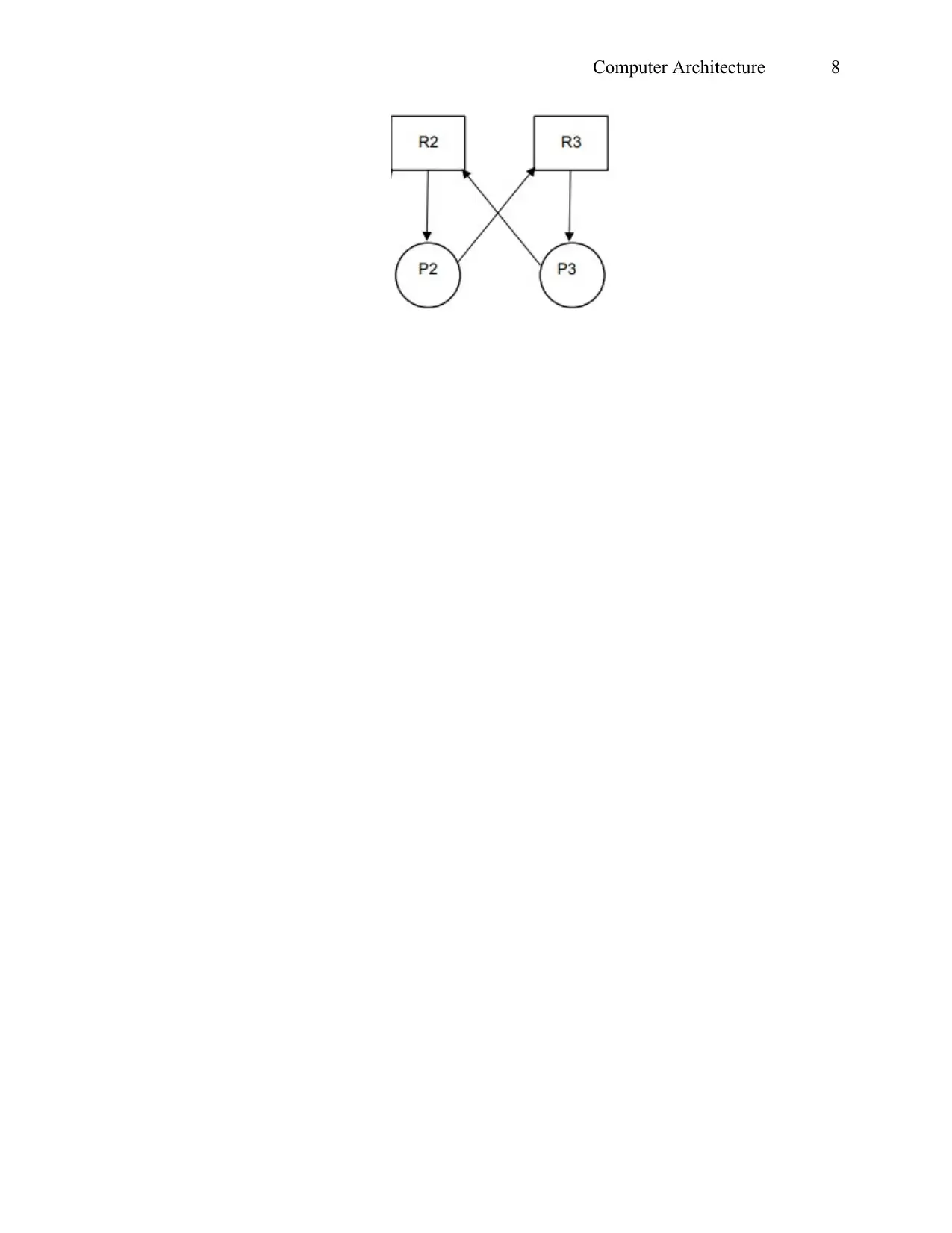
This assignment delves into the critical aspects of computer organization and architecture, specifically focusing on the concept of deadlocks. It explores various strategies for handling deadlocks, including detection, prevention, and avoidance, detailing how these methods are applied in different contexts such as CPU, main memory, and file management systems. The assignment analyzes the banking algorithm to illustrate deadlock prevention and discusses key metrics like turnaround time and waiting time in the context of scheduling algorithms. Several scheduling algorithms, including First Come First Serve (FCFS), Shortest Job Next (SJN), Shortest Remaining Time (SRT), and Round Robin, are examined with their timelines and characteristics. Furthermore, the assignment includes an analysis of a directed resource graph to demonstrate deadlock situations. The document also provides references to relevant research papers.








1 out of 9
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.