Analysis of Association Rules and Clustering Techniques in Data
VerifiedAdded on 2020/05/08
|9
|1300
|69
AI Summary
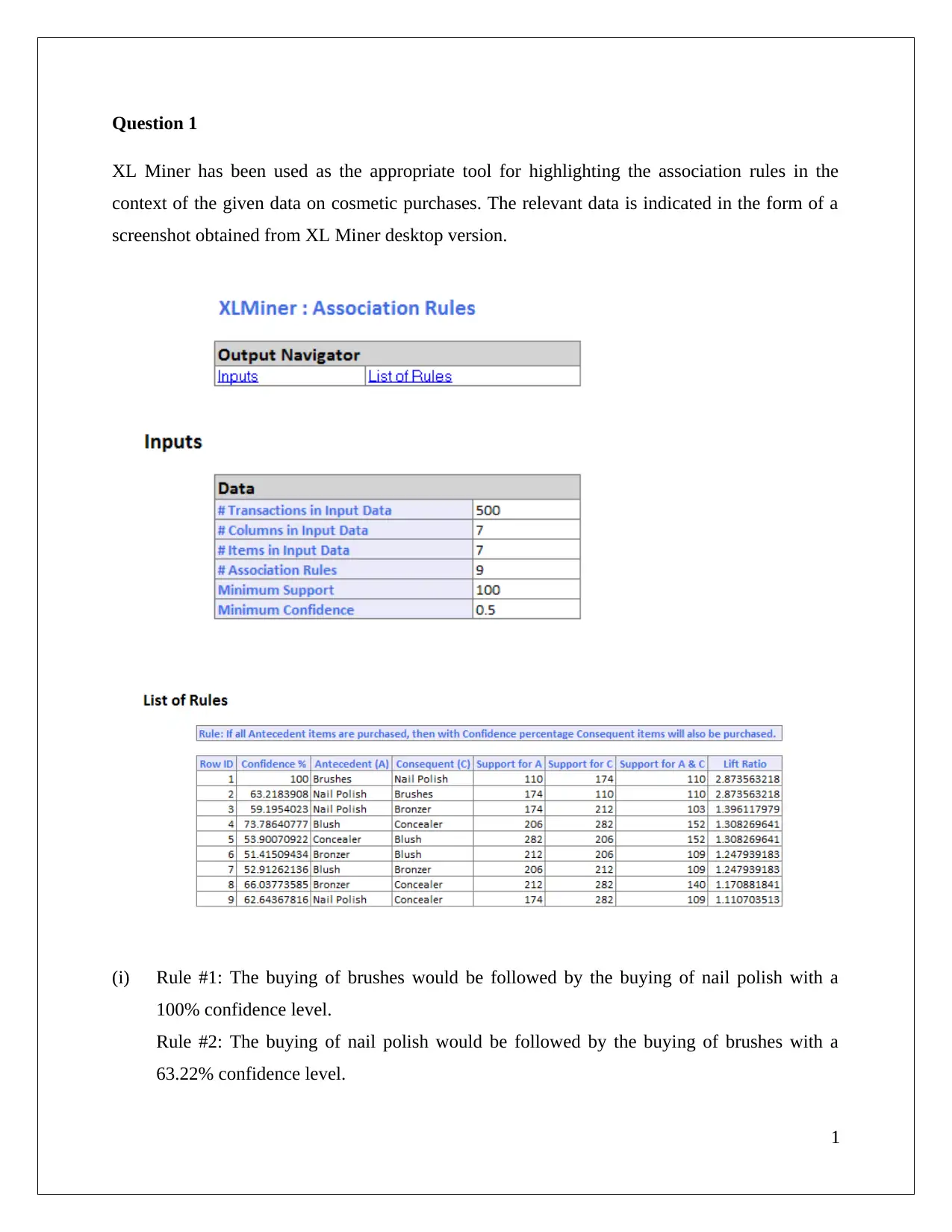
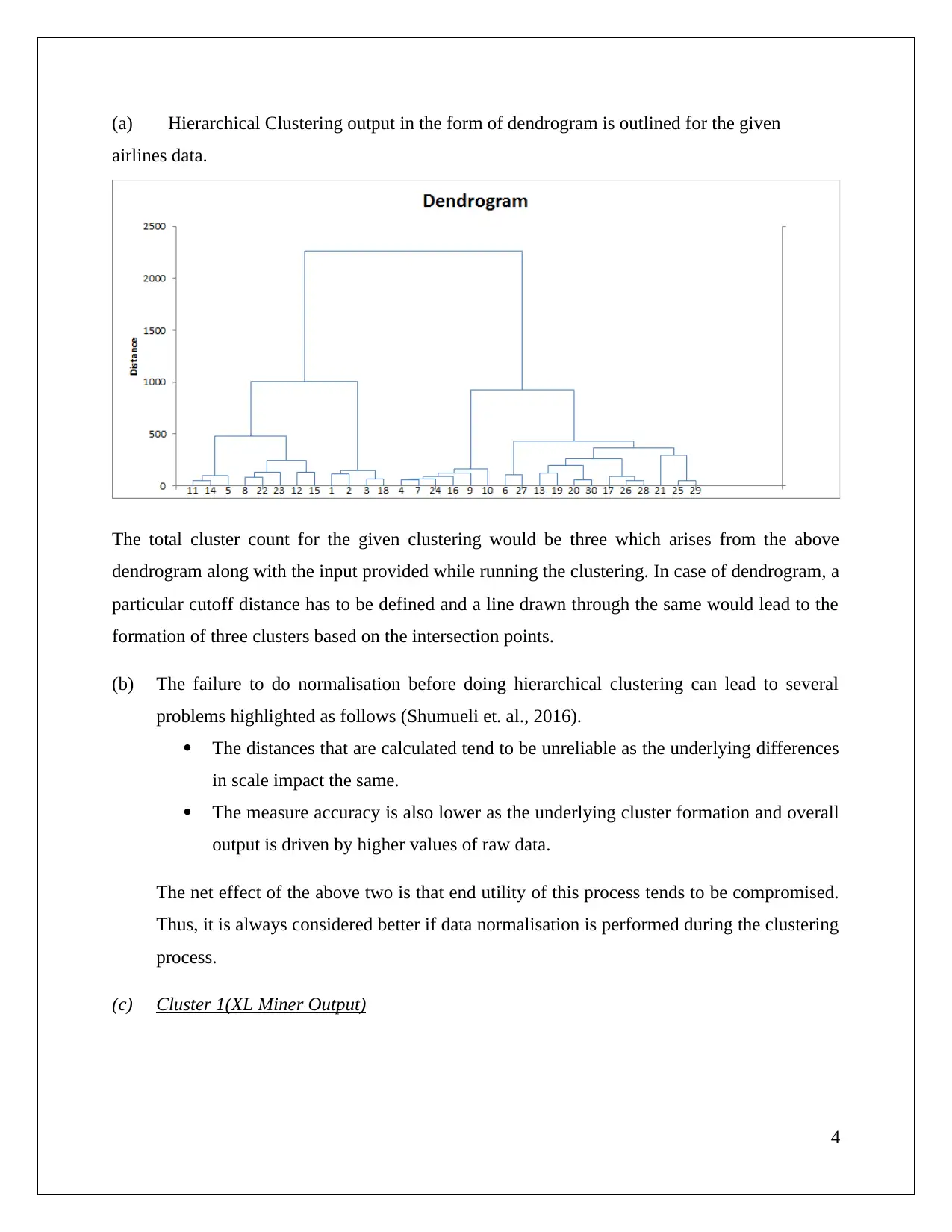
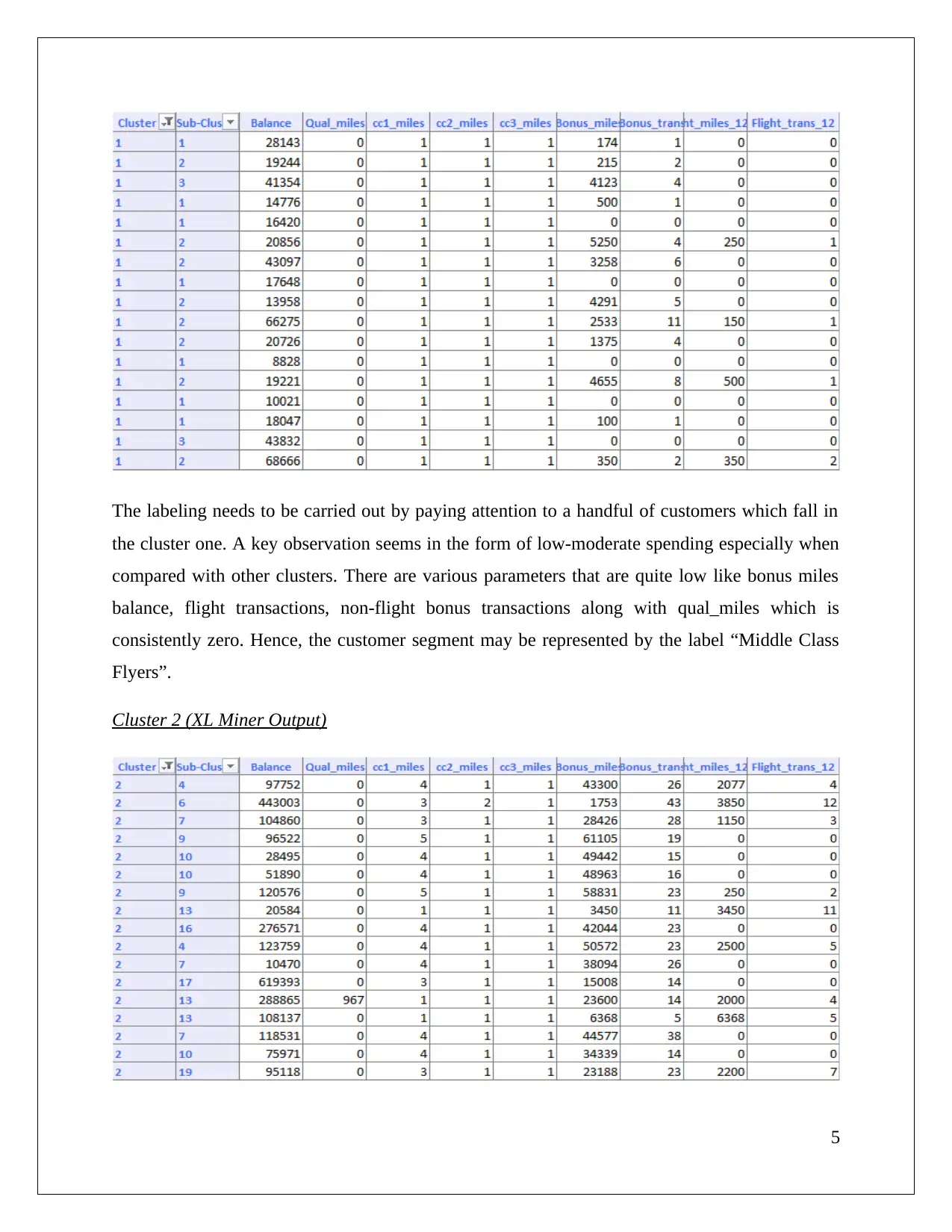
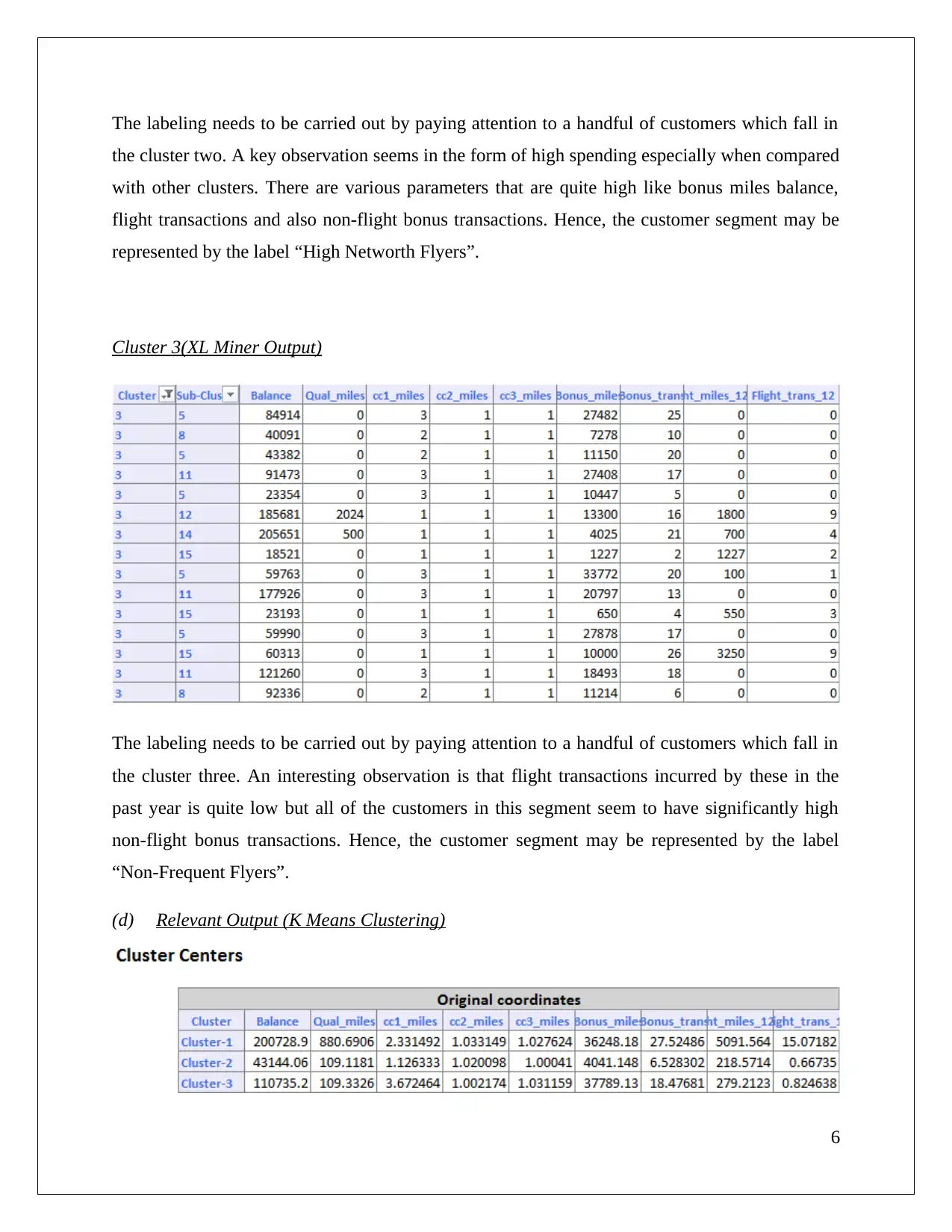
The task involves utilizing XL Miner to analyze association rules within a dataset concerning cosmetic purchases, highlighting confidence levels and redundancy in these rules. The study focuses on how different confidence thresholds impact rule generation and interpretation. Additionally, the assignment evaluates hierarchical clustering techniques on airline data, emphasizing the necessity of normalization for accurate results. It discusses the labeling of customer segments based on characteristics such as spending behavior and flight transaction frequency. Furthermore, it contrasts cluster labels derived from hierarchical methods with those obtained via K-means clustering, revealing differing insights into customer segmentation.





1 out of 9
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.