CR2030 Project One: Analyzing Depression and Anxiety with Statistics
VerifiedAdded on 2023/01/13
|17
|3625
|1
Project
AI Summary
This project delves into statistical analysis, covering descriptive and inferential statistics, and various statistical tests including t-tests, ANOVA, Levene's test, Kolmogorov-Smirnov test, correlation, linear regression, and Chi-square tests. The assignment explores the differences between descriptive and inferential statistics, the assumptions of sphericity and parametric tests, and the application of different statistical tests to compare groups and analyze relationships between variables. The project includes calculations of statistical measures like mean, standard deviation, and range, and interprets the results in the context of depression, anxiety, and gender. The student also designs questions for a study and provides a detailed analysis of the data.

CR2030 Project One
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Table of Contents
INTRODUCTION...........................................................................................................................3
MAIN BODY..................................................................................................................................3
1. Explain difference between descriptive & inferential statistics along with suitable example
and explain why they constitute descriptive / inferential statistics..............................................3
2. Explain the assumption of sphericity and evaluate their own research scenario for the
assumption, also identify that how these assumption is similar or different from homogeneity
of variance assumption................................................................................................................5
3. Explain the differences between one-way and two-way experimental designs along with
suitable example and also define the two-way design advantages..............................................5
4. Explain the assumptions of parametric and provide a suitable example for this.....................6
5. Conduct a series of test or compare two groups of participants..............................................6
6. Calculation...............................................................................................................................8
7. Appropriate statistical test determines whether male or female participants are more
depressed....................................................................................................................................10
8) Appropriate statistical test to determine whether participants’ socioeconomic status impacts
on their anxiety scores...............................................................................................................12
9) Appropriate statistical test to determine whether participants’ depression and anxiety scores
significantly differ.....................................................................................................................14
10) Design of a question to the study........................................................................................15
CONCLUSION..............................................................................................................................16
REFERENCES..............................................................................................................................17
INTRODUCTION...........................................................................................................................3
MAIN BODY..................................................................................................................................3
1. Explain difference between descriptive & inferential statistics along with suitable example
and explain why they constitute descriptive / inferential statistics..............................................3
2. Explain the assumption of sphericity and evaluate their own research scenario for the
assumption, also identify that how these assumption is similar or different from homogeneity
of variance assumption................................................................................................................5
3. Explain the differences between one-way and two-way experimental designs along with
suitable example and also define the two-way design advantages..............................................5
4. Explain the assumptions of parametric and provide a suitable example for this.....................6
5. Conduct a series of test or compare two groups of participants..............................................6
6. Calculation...............................................................................................................................8
7. Appropriate statistical test determines whether male or female participants are more
depressed....................................................................................................................................10
8) Appropriate statistical test to determine whether participants’ socioeconomic status impacts
on their anxiety scores...............................................................................................................12
9) Appropriate statistical test to determine whether participants’ depression and anxiety scores
significantly differ.....................................................................................................................14
10) Design of a question to the study........................................................................................15
CONCLUSION..............................................................................................................................16
REFERENCES..............................................................................................................................17

INTRODUCTION
Statistical analysis is used to arrange data or produce some results which helps for the
further analysis or formulate strategies accordingly (Cooper and Sommer, 2018). There are
various tools and techniques which is used by the individuals to find accurate results and modify
data as per the requirement. This project cover the various types of statistical methodologies and
done different types of test as per the requirement of data.
MAIN BODY
1. Explain difference between descriptive & inferential statistics along with suitable example and
explain why they constitute descriptive / inferential statistics
Descriptive statistics: In this method, data used to summarise on the graph and this
process allow to understand the set of observation. It describes the data such as sample that is
very common and they does not have uncertainly because large population data not used. There
are some common tools which is used in the descriptive statistics such as central tendency,
dispersion, skewness etc.
For example: We collect 30 sample that is test score of students and calculate the
summary statistics to produce graph.
Statistical analysis is used to arrange data or produce some results which helps for the
further analysis or formulate strategies accordingly (Cooper and Sommer, 2018). There are
various tools and techniques which is used by the individuals to find accurate results and modify
data as per the requirement. This project cover the various types of statistical methodologies and
done different types of test as per the requirement of data.
MAIN BODY
1. Explain difference between descriptive & inferential statistics along with suitable example and
explain why they constitute descriptive / inferential statistics
Descriptive statistics: In this method, data used to summarise on the graph and this
process allow to understand the set of observation. It describes the data such as sample that is
very common and they does not have uncertainly because large population data not used. There
are some common tools which is used in the descriptive statistics such as central tendency,
dispersion, skewness etc.
For example: We collect 30 sample that is test score of students and calculate the
summary statistics to produce graph.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
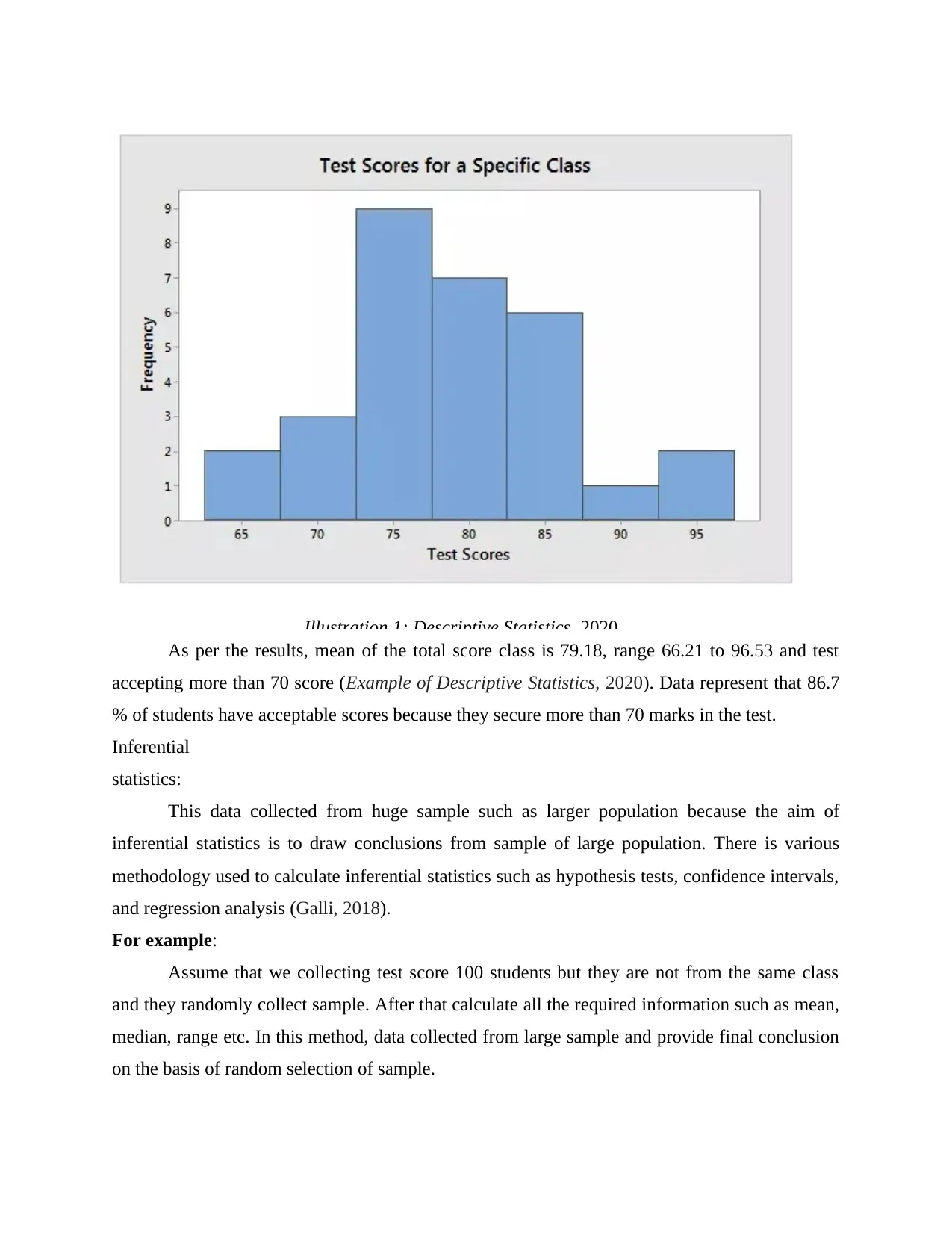
Illustration 1: Descriptive Statistics, 2020.
As per the results, mean of the total score class is 79.18, range 66.21 to 96.53 and test
accepting more than 70 score (Example of Descriptive Statistics, 2020). Data represent that 86.7
% of students have acceptable scores because they secure more than 70 marks in the test.
Inferential
statistics:
This data collected from huge sample such as larger population because the aim of
inferential statistics is to draw conclusions from sample of large population. There is various
methodology used to calculate inferential statistics such as hypothesis tests, confidence intervals,
and regression analysis (Galli, 2018).
For example:
Assume that we collecting test score 100 students but they are not from the same class
and they randomly collect sample. After that calculate all the required information such as mean,
median, range etc. In this method, data collected from large sample and provide final conclusion
on the basis of random selection of sample.
As per the results, mean of the total score class is 79.18, range 66.21 to 96.53 and test
accepting more than 70 score (Example of Descriptive Statistics, 2020). Data represent that 86.7
% of students have acceptable scores because they secure more than 70 marks in the test.
Inferential
statistics:
This data collected from huge sample such as larger population because the aim of
inferential statistics is to draw conclusions from sample of large population. There is various
methodology used to calculate inferential statistics such as hypothesis tests, confidence intervals,
and regression analysis (Galli, 2018).
For example:
Assume that we collecting test score 100 students but they are not from the same class
and they randomly collect sample. After that calculate all the required information such as mean,
median, range etc. In this method, data collected from large sample and provide final conclusion
on the basis of random selection of sample.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

It is very difficult to say that which statistical method is better because use of both
methodologies based on the types of data. Descriptive statistics is the most suitable approach
because it provides accuracy and the other hand, in order to solve complex data which, affect
large population than use inferential statistics.
2. Explain the assumption of sphericity and evaluate their own research scenario for the
assumption, also identify that how these assumption is similar or different from
homogeneity of variance assumption
Sphericity is the assumption of repetitive measures of ANOVA but there are various
conditions such as:
All the independent variables should be equal
Difference between combinations of the conditions are equal.
If sphericity is desecrated, then variance calculations may be distorted.
Sphericity refer to the equality of variances that is repeated measures ANOVA and it also
measure the homogeneity of the variances. It is quite similar to the homogeneity of variant
among the groups where ANOVA is univariate. This is denoted with this “ε” symbol refer to the
“circularity”.
Homogeneity of variance assumption implicit F test or T test from the population
variances where more than two sample consider equal. There is some assumption which
mentioned below:
T-test and ANOVA required independent samples where each group comparison will be done
with the same variance (Kerzner, 2018).
T- test and ANOVA use the independent samples as per the t- test or F -test statistics.
3. Explain the differences between one-way and two-way experimental designs along with
suitable example and also define the two-way design advantages
One-way experimental design means one-way ANOVA and it is the statistical test
which is used to compare variance within sample and include the independent factor or variance.
It is a hypothesis based test and its aims to measure the multiple reciprocally exclusive theories
regarding collected data.
For example: Group of randomly selected individual data divide into multiple small
groups and perform different task. So in this case, individual learn the effect of tea and how it
helps in weight loss such as green tea, black tea or no tea.
methodologies based on the types of data. Descriptive statistics is the most suitable approach
because it provides accuracy and the other hand, in order to solve complex data which, affect
large population than use inferential statistics.
2. Explain the assumption of sphericity and evaluate their own research scenario for the
assumption, also identify that how these assumption is similar or different from
homogeneity of variance assumption
Sphericity is the assumption of repetitive measures of ANOVA but there are various
conditions such as:
All the independent variables should be equal
Difference between combinations of the conditions are equal.
If sphericity is desecrated, then variance calculations may be distorted.
Sphericity refer to the equality of variances that is repeated measures ANOVA and it also
measure the homogeneity of the variances. It is quite similar to the homogeneity of variant
among the groups where ANOVA is univariate. This is denoted with this “ε” symbol refer to the
“circularity”.
Homogeneity of variance assumption implicit F test or T test from the population
variances where more than two sample consider equal. There is some assumption which
mentioned below:
T-test and ANOVA required independent samples where each group comparison will be done
with the same variance (Kerzner, 2018).
T- test and ANOVA use the independent samples as per the t- test or F -test statistics.
3. Explain the differences between one-way and two-way experimental designs along with
suitable example and also define the two-way design advantages
One-way experimental design means one-way ANOVA and it is the statistical test
which is used to compare variance within sample and include the independent factor or variance.
It is a hypothesis based test and its aims to measure the multiple reciprocally exclusive theories
regarding collected data.
For example: Group of randomly selected individual data divide into multiple small
groups and perform different task. So in this case, individual learn the effect of tea and how it
helps in weight loss such as green tea, black tea or no tea.

Two-way experimental design called two-way ANOVA, where in one-way independent
variable affecting dependent variable. In the tow way, there are two independent variable affect
the other factors. If any research has quantitative results than two collection instructive variables
available than implement two-way ANOVA.
For example:
If individual wanted to find interaction among income and gender for emotion level at job
interviews. So emotional level of an individual is the actual outcome and the other side factor
can be measured. There are two factors identified such as income & gender and consider as
variables. Both factors are independent variables and it can say that Two Way ANOVA.
Some of the advantage of two-way ANOVA:
Two-way experimental design is more cost effective in comparison to one-way design.
It helps in analysing the interaction among two factors.
It helps in understanding the combination of different factors and how they influence the
behaviour.
Two-way ANOVA allow to analyse synergistic effects among two different independent
variables on dependent variable.
4. Explain the assumptions of parametric and provide a suitable example for this
Parametric term refers to the statistics which is the procedure of hypothesis testing and
this test based on the various assumptions which is collected with the help of observations of
data. At the time of conduction parametric test, research need to ensure that all the assumptions
should be fulfilled such as:
Normal distribution of data where value of p depends upon normal sampling distribution.
Homogeneity of variance mean data need to be similar throughout the sample (Brookes, N.,
Butler, Dey and Clark, 2014).
Data should be independent from each other’s.
5. Conduct a series of test or compare two groups of participants
(a) Levene's test is being used for testing of “K” samples which have equal variances. In the
aspect of comparison of cognitive ability score of two groups, this can be find out that
Levene's test is 0.02. In these two groups' cognitive score data, this can be find out that there
is no variability. It is so because for variability between the data set of two groups, the
variable affecting dependent variable. In the tow way, there are two independent variable affect
the other factors. If any research has quantitative results than two collection instructive variables
available than implement two-way ANOVA.
For example:
If individual wanted to find interaction among income and gender for emotion level at job
interviews. So emotional level of an individual is the actual outcome and the other side factor
can be measured. There are two factors identified such as income & gender and consider as
variables. Both factors are independent variables and it can say that Two Way ANOVA.
Some of the advantage of two-way ANOVA:
Two-way experimental design is more cost effective in comparison to one-way design.
It helps in analysing the interaction among two factors.
It helps in understanding the combination of different factors and how they influence the
behaviour.
Two-way ANOVA allow to analyse synergistic effects among two different independent
variables on dependent variable.
4. Explain the assumptions of parametric and provide a suitable example for this
Parametric term refers to the statistics which is the procedure of hypothesis testing and
this test based on the various assumptions which is collected with the help of observations of
data. At the time of conduction parametric test, research need to ensure that all the assumptions
should be fulfilled such as:
Normal distribution of data where value of p depends upon normal sampling distribution.
Homogeneity of variance mean data need to be similar throughout the sample (Brookes, N.,
Butler, Dey and Clark, 2014).
Data should be independent from each other’s.
5. Conduct a series of test or compare two groups of participants
(a) Levene's test is being used for testing of “K” samples which have equal variances. In the
aspect of comparison of cognitive ability score of two groups, this can be find out that
Levene's test is 0.02. In these two groups' cognitive score data, this can be find out that there
is no variability. It is so because for variability between the data set of two groups, the
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

Levene's test should be of 0.05. For this purpose, T-test can be used in order to find out
variables between these two groups of offender and non offender.
(b) The Kolmogorov-Smirnov test is used to find out distinction between the empirical
distribution functioning of sample and cumulative distribution function of reference
distribution of two different samples. In the sense of test of two groups, this can be find out
that value is 0.3 which shows that there is no variability in the data set of neuroticism scores.
Apart from the Kolmogorov-Smirnov test, there is an another alternative which may be
used for finding variances. The another test can be Chi-square test that will be suitable.
(c) In order to find out association between gender of participants and crime history, the suitable
test will be correlation test. It is a type of test which is applied in order to evaluate
association between two or more variables. This test is done on the basis of two methods
which are Pearson correlation and parametric correlation test. In regards to find out relation
between gender and crime history, the parametric correlation test will be suitable. As well as
interpretation of this correlation can be done in accordance of calculated value of data. The
reason of applying this test is that it can make best relation between two set of variables. As
well as there is not any other test that can be applied instead of correlation test.
(d) For making comparison between to data set, one of the best test is T – test which makes
better outcome. In the context of making comparison of offenders' anxiety score pre and post
counselling, this test will be suitable. As well as under descriptive statistics calculation of
mean will be suitable.
(e) In order to do test of interaction between gender's with pre and post counselling depression
score, best test will be linear regression. It is so because by help of this users can find out each
variables relation with another group's variable (Brocke and Lippe, 2015).
(f) For finding impact of age on anxiety scores, the best suitable test is Chi-square test. In the
case when test will produce value of 0.14 then it can be concluded that there will be a
variable. In addition, age group of 26-40 will be variable.
variables between these two groups of offender and non offender.
(b) The Kolmogorov-Smirnov test is used to find out distinction between the empirical
distribution functioning of sample and cumulative distribution function of reference
distribution of two different samples. In the sense of test of two groups, this can be find out
that value is 0.3 which shows that there is no variability in the data set of neuroticism scores.
Apart from the Kolmogorov-Smirnov test, there is an another alternative which may be
used for finding variances. The another test can be Chi-square test that will be suitable.
(c) In order to find out association between gender of participants and crime history, the suitable
test will be correlation test. It is a type of test which is applied in order to evaluate
association between two or more variables. This test is done on the basis of two methods
which are Pearson correlation and parametric correlation test. In regards to find out relation
between gender and crime history, the parametric correlation test will be suitable. As well as
interpretation of this correlation can be done in accordance of calculated value of data. The
reason of applying this test is that it can make best relation between two set of variables. As
well as there is not any other test that can be applied instead of correlation test.
(d) For making comparison between to data set, one of the best test is T – test which makes
better outcome. In the context of making comparison of offenders' anxiety score pre and post
counselling, this test will be suitable. As well as under descriptive statistics calculation of
mean will be suitable.
(e) In order to do test of interaction between gender's with pre and post counselling depression
score, best test will be linear regression. It is so because by help of this users can find out each
variables relation with another group's variable (Brocke and Lippe, 2015).
(f) For finding impact of age on anxiety scores, the best suitable test is Chi-square test. In the
case when test will produce value of 0.14 then it can be concluded that there will be a
variable. In addition, age group of 26-40 will be variable.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

6. Calculation
Depression score of ten participants:
Serial number Depression score
1 12
2 6
3 1
4 5
5 8
6 6
7 8
8 15
9 6
10 14
Mean= Σx/N
Depression score
12
6
1
5
8
6
8
15
6
Depression score of ten participants:
Serial number Depression score
1 12
2 6
3 1
4 5
5 8
6 6
7 8
8 15
9 6
10 14
Mean= Σx/N
Depression score
12
6
1
5
8
6
8
15
6

14
Total= 90
Mean= 90/10
9
Standard deviation= ∑(x−x¯)²/N−1
x x¯ (x-x¯) (x−x¯)²
12 9 3 9
6 9 -3 9
1 9 -8 64
5 9 -4 16
8 9 -1 1
6 9 -3 9
8 9 -1 1
15 9 6 36
6 9 -3 9
14 9 5 25
179
Standard deviation= 179/(10-1)
= 179/9
= 19.88
Range= Higher value-minimum value
Higher value= 15
Minimum value= 1
Range= 15-1
= 14
Total= 90
Mean= 90/10
9
Standard deviation= ∑(x−x¯)²/N−1
x x¯ (x-x¯) (x−x¯)²
12 9 3 9
6 9 -3 9
1 9 -8 64
5 9 -4 16
8 9 -1 1
6 9 -3 9
8 9 -1 1
15 9 6 36
6 9 -3 9
14 9 5 25
179
Standard deviation= 179/(10-1)
= 179/9
= 19.88
Range= Higher value-minimum value
Higher value= 15
Minimum value= 1
Range= 15-1
= 14
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
Explanation of what result means:
Mean- On the basis of data of depression score of ten respondents, this can be find out that value
of mean is of 9. This is so because total score of depression is of 90 and number of respondents
are 10.
Standard deviation- As per the value of mean, further standard deviation is calculated that is of
19.88.
Range- The range is difference between higher and lower values. In the aspect of above data set,
higher value is of 15 and lower value is of 1. Thus, the range is 14.
7. Appropriate statistical test determines whether male or female participants are more depressed
In order to determine the relationship among the variable i.e gender and depression liner
regression statistical test have been performed. The results are listed below:
Descriptive Statistics
Mean Std.
Deviation
N
Gender 1.4625 .50174 80
Depression score
(possible range 0-21) 8.7000 4.50148 80
Model Summaryb
Model R R Square Adjusted R
Square
Std. Error of the Estimate
1 .100a .010 -.003 .50240
a. Predictors: (Constant), Depression score (possible range 0-21)
b. Dependent Variable: Gender
ANOVAa
Model Sum of
Squares
df Mean
Square
F Sig.
1
Regression .200 1 .200 .793 .376b
Residual 19.687 78 .252
Total 19.887 79
a. Dependent Variable: Gender
b. Predictors: (Constant), Depression score (possible range 0-21)
Coefficientsa
Mean- On the basis of data of depression score of ten respondents, this can be find out that value
of mean is of 9. This is so because total score of depression is of 90 and number of respondents
are 10.
Standard deviation- As per the value of mean, further standard deviation is calculated that is of
19.88.
Range- The range is difference between higher and lower values. In the aspect of above data set,
higher value is of 15 and lower value is of 1. Thus, the range is 14.
7. Appropriate statistical test determines whether male or female participants are more depressed
In order to determine the relationship among the variable i.e gender and depression liner
regression statistical test have been performed. The results are listed below:
Descriptive Statistics
Mean Std.
Deviation
N
Gender 1.4625 .50174 80
Depression score
(possible range 0-21) 8.7000 4.50148 80
Model Summaryb
Model R R Square Adjusted R
Square
Std. Error of the Estimate
1 .100a .010 -.003 .50240
a. Predictors: (Constant), Depression score (possible range 0-21)
b. Dependent Variable: Gender
ANOVAa
Model Sum of
Squares
df Mean
Square
F Sig.
1
Regression .200 1 .200 .793 .376b
Residual 19.687 78 .252
Total 19.887 79
a. Dependent Variable: Gender
b. Predictors: (Constant), Depression score (possible range 0-21)
Coefficientsa
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
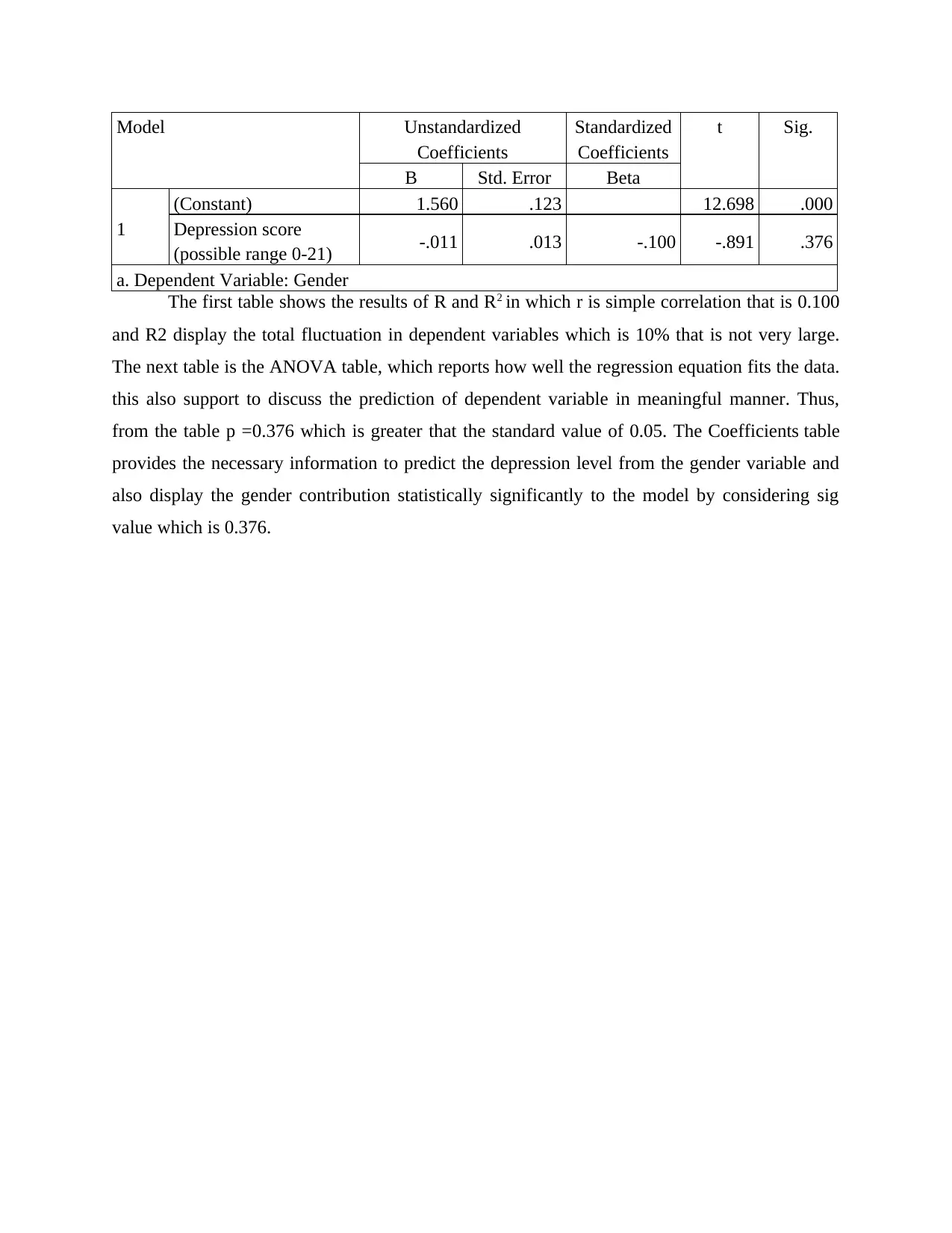
Model Unstandardized
Coefficients
Standardized
Coefficients
t Sig.
B Std. Error Beta
1
(Constant) 1.560 .123 12.698 .000
Depression score
(possible range 0-21) -.011 .013 -.100 -.891 .376
a. Dependent Variable: Gender
The first table shows the results of R and R2 in which r is simple correlation that is 0.100
and R2 display the total fluctuation in dependent variables which is 10% that is not very large.
The next table is the ANOVA table, which reports how well the regression equation fits the data.
this also support to discuss the prediction of dependent variable in meaningful manner. Thus,
from the table p =0.376 which is greater that the standard value of 0.05. The Coefficients table
provides the necessary information to predict the depression level from the gender variable and
also display the gender contribution statistically significantly to the model by considering sig
value which is 0.376.
Coefficients
Standardized
Coefficients
t Sig.
B Std. Error Beta
1
(Constant) 1.560 .123 12.698 .000
Depression score
(possible range 0-21) -.011 .013 -.100 -.891 .376
a. Dependent Variable: Gender
The first table shows the results of R and R2 in which r is simple correlation that is 0.100
and R2 display the total fluctuation in dependent variables which is 10% that is not very large.
The next table is the ANOVA table, which reports how well the regression equation fits the data.
this also support to discuss the prediction of dependent variable in meaningful manner. Thus,
from the table p =0.376 which is greater that the standard value of 0.05. The Coefficients table
provides the necessary information to predict the depression level from the gender variable and
also display the gender contribution statistically significantly to the model by considering sig
value which is 0.376.
8) Appropriate statistical test to determine whether participants’ socioeconomic status impacts on
their anxiety scores.
Chi square test is considering to be an effective statistical test which support to define the
socioeconomic status impacts on their anxiety scores.
Case Processing Summary
Cases
Valid Missing Total
N Percent N Percent N Percent
their anxiety scores.
Chi square test is considering to be an effective statistical test which support to define the
socioeconomic status impacts on their anxiety scores.
Case Processing Summary
Cases
Valid Missing Total
N Percent N Percent N Percent
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 17
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.