Credit Scoring Model Development and Analysis - [Course Name]
VerifiedAdded on 2022/08/28
|7
|1899
|25
Practical Assignment
AI Summary
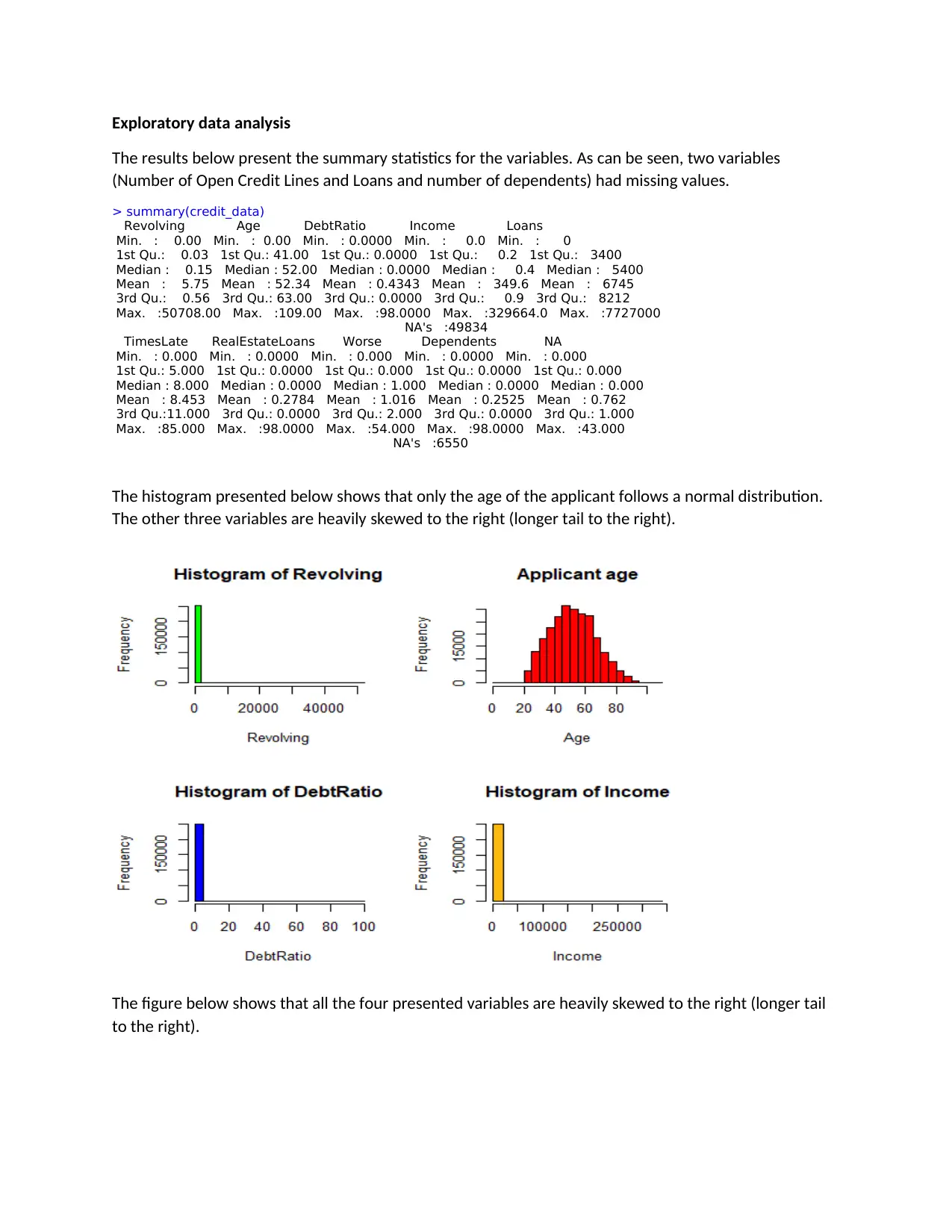
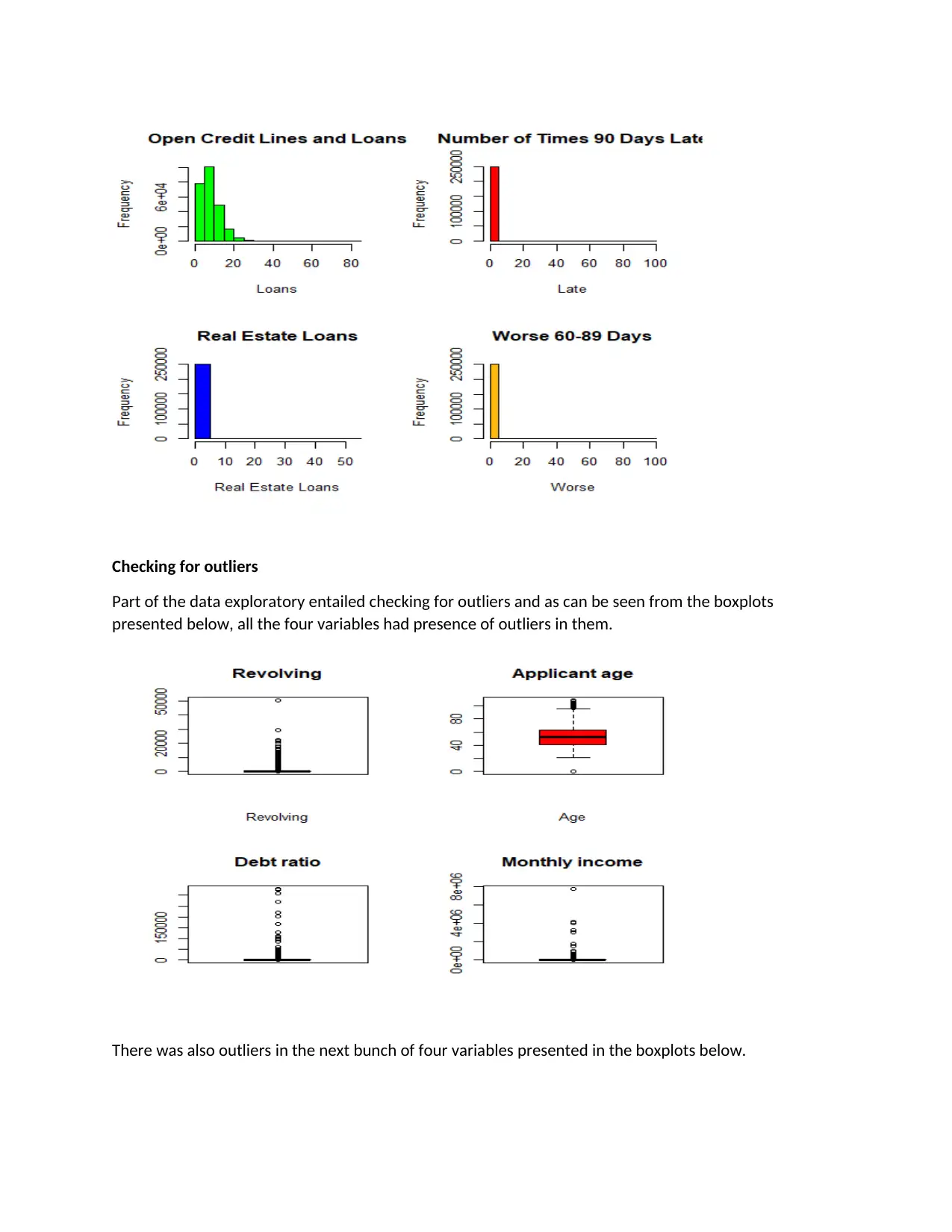
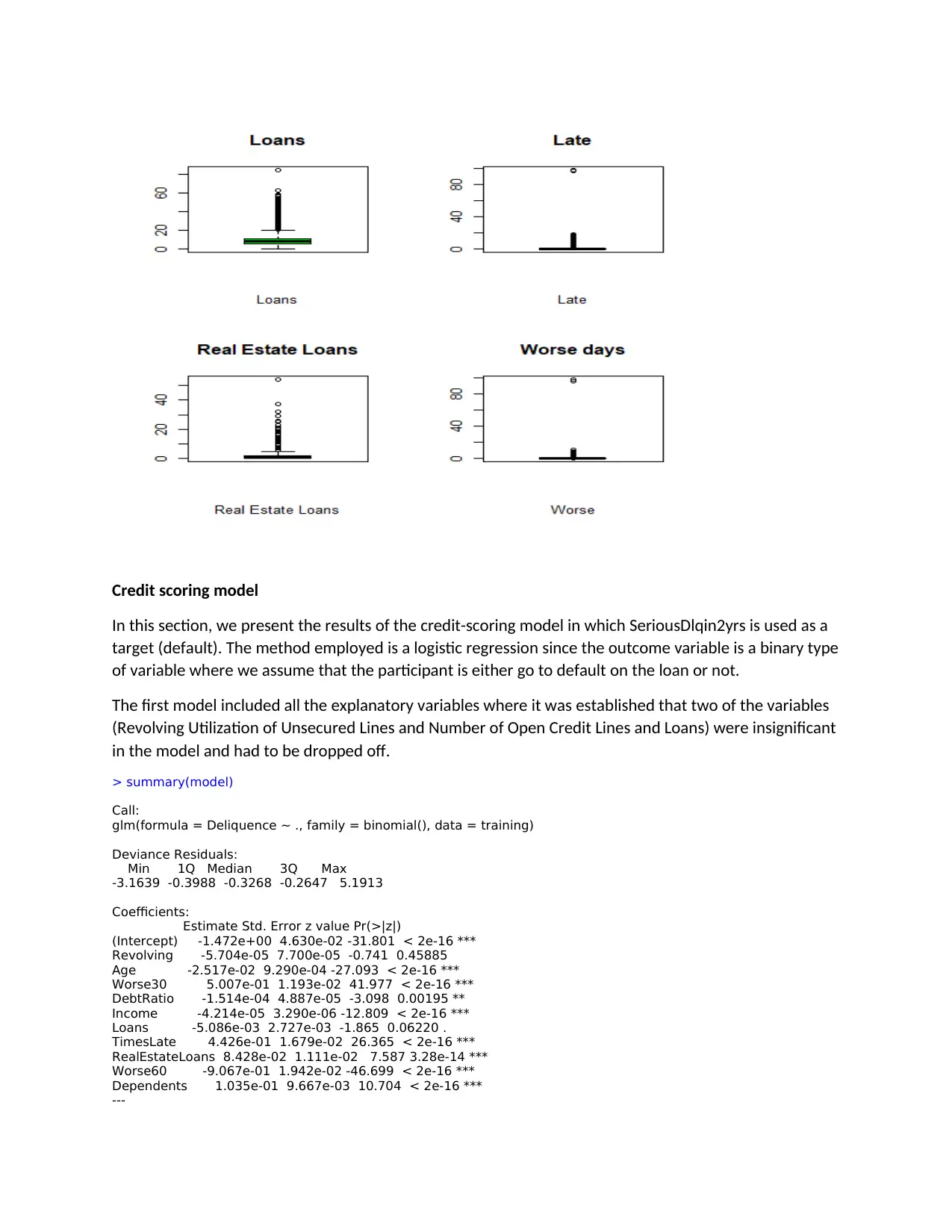
This assignment presents a credit scoring model developed using a dataset of 150,000 borrowers. The analysis begins with exploratory data analysis (EDA) to understand the distribution of variables, identify missing values, and detect outliers. The EDA reveals that some variables are heavily skewed and contain outliers. A logistic regression model is then built to predict the probability of default (SeriousDlqin2yrs). The initial model includes all explanatory variables, but insignificant variables are dropped in the second model. The results show that certain variables (age, debt ratio, monthly income, and past due) have a positive impact on the likelihood of default, while others have a negative impact. The model's overall accuracy is 67.28%. The R code used for data loading, preprocessing, model building, and evaluation is also provided. The assignment demonstrates the application of data mining techniques in credit risk assessment.




1 out of 7
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.