Regression Analysis Report: Purchase Intention and CRM Study
VerifiedAdded on 2023/04/21
|8
|1747
|189
Report
AI Summary
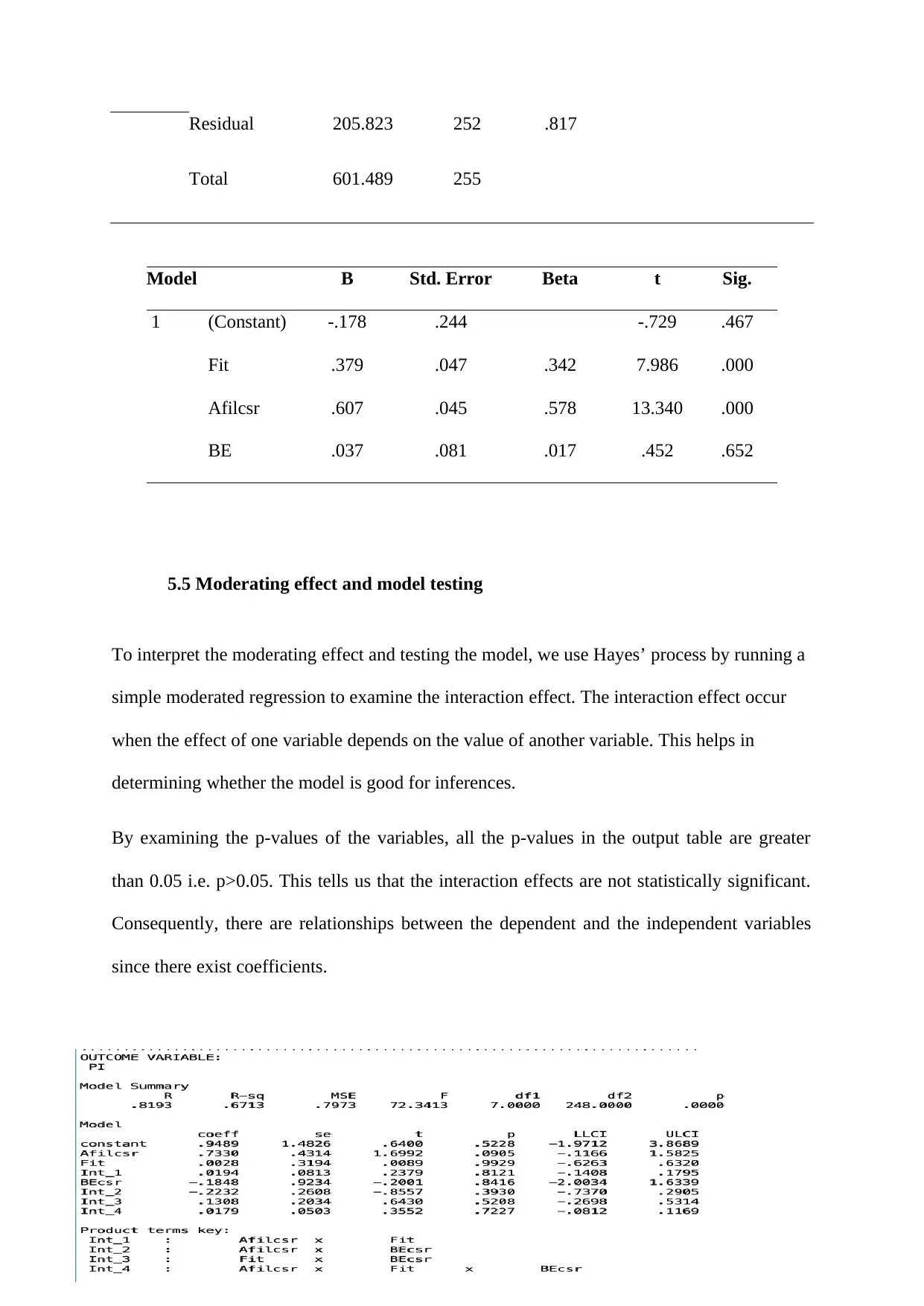
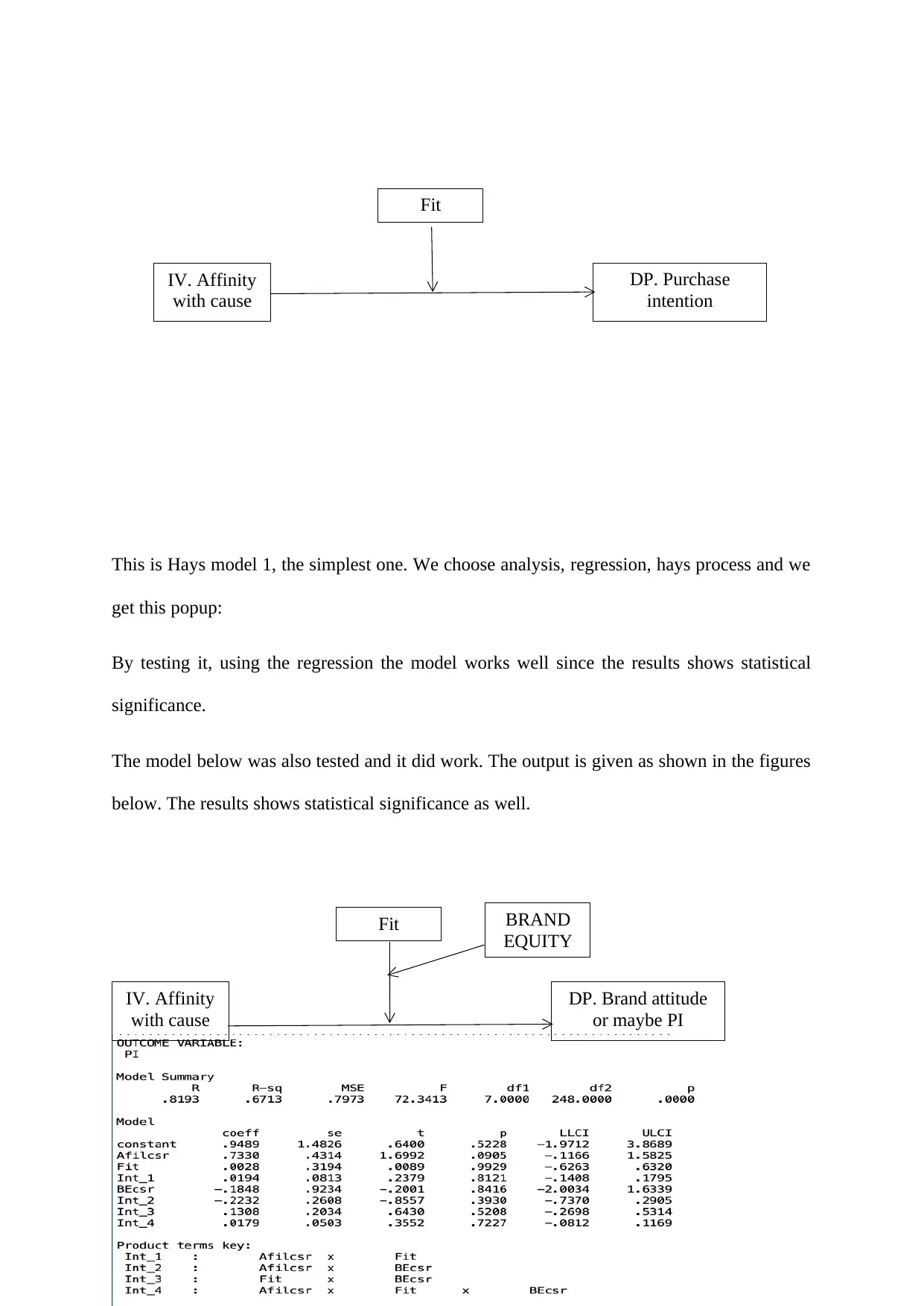
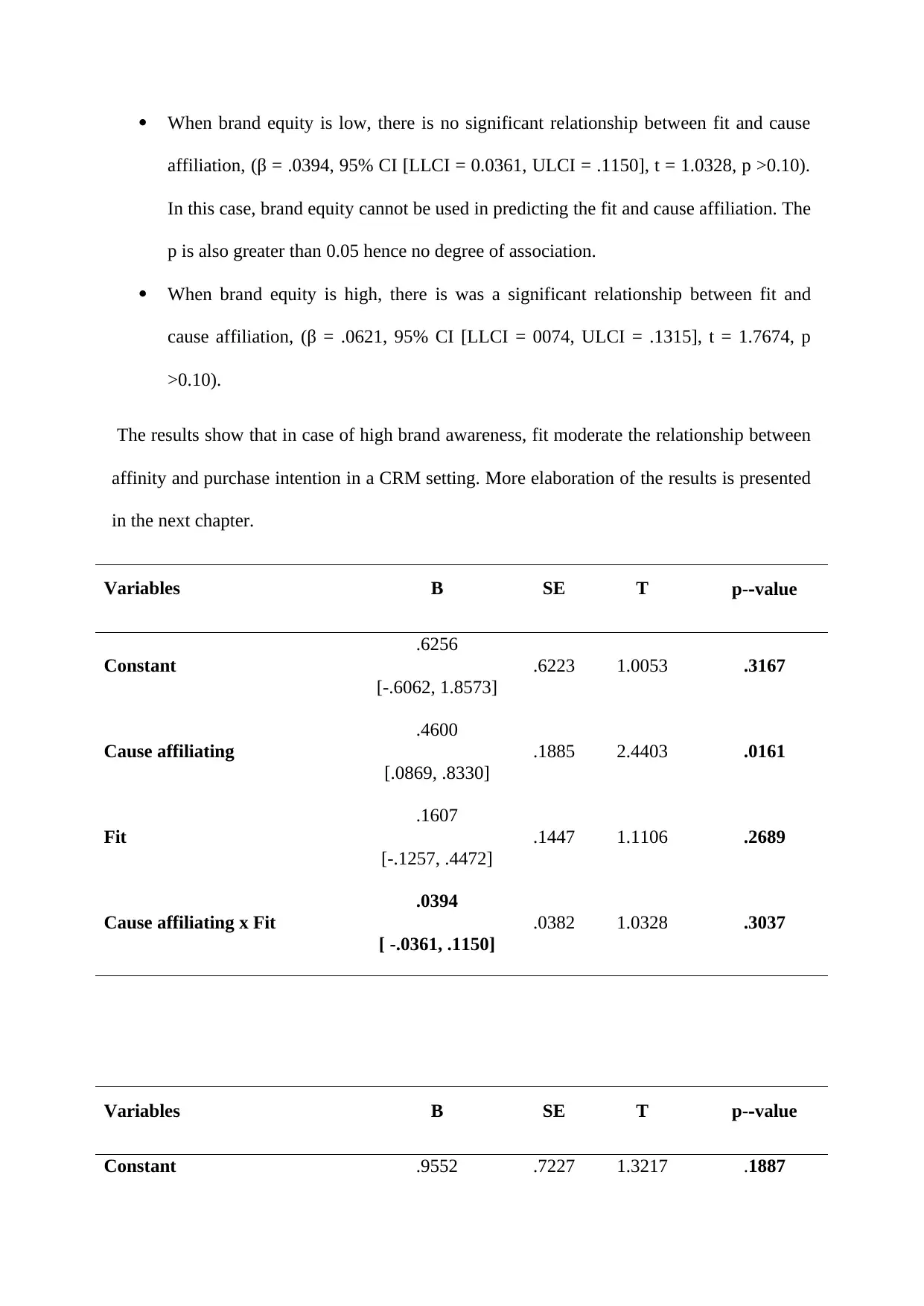
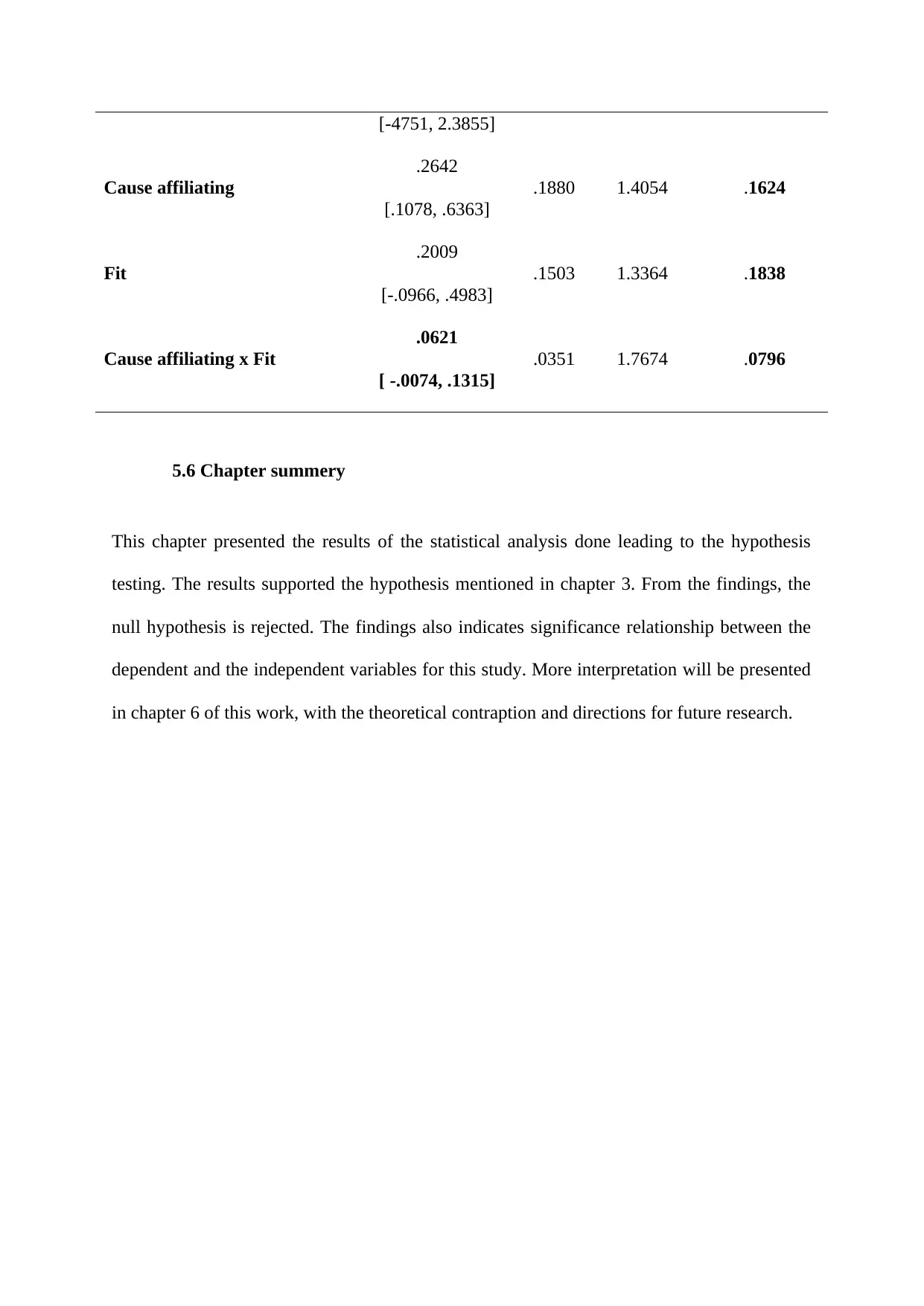
This report presents the results of a statistical analysis focusing on hypothesis testing related to purchase intention within a marketing context. The study employed OLS hierarchical regression and moderation analysis to examine the relationships between variables such as fit, cause affiliation, and brand equity. The analysis included multiple regression to predict purchase intention, with findings indicating a significant relationship between independent variables and the dependent variable. The report details the use of Hayes’ process model for moderation analysis to understand variable interactions, and examines the moderating effects of brand equity. The results support the study's hypothesis, with significant findings and the rejection of the null hypothesis. The report also includes multiple tables displaying statistical values and p-values, and discusses the implications of the findings, including the statistical significance of the regression model. The chapter concludes by summarizing the key findings and alludes to further interpretation and discussion in subsequent chapters.




1 out of 8
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.