Data Analysis and Digital Operations: Customer Churn Report
VerifiedAdded on 2022/10/19
|18
|2711
|438
Report
AI Summary
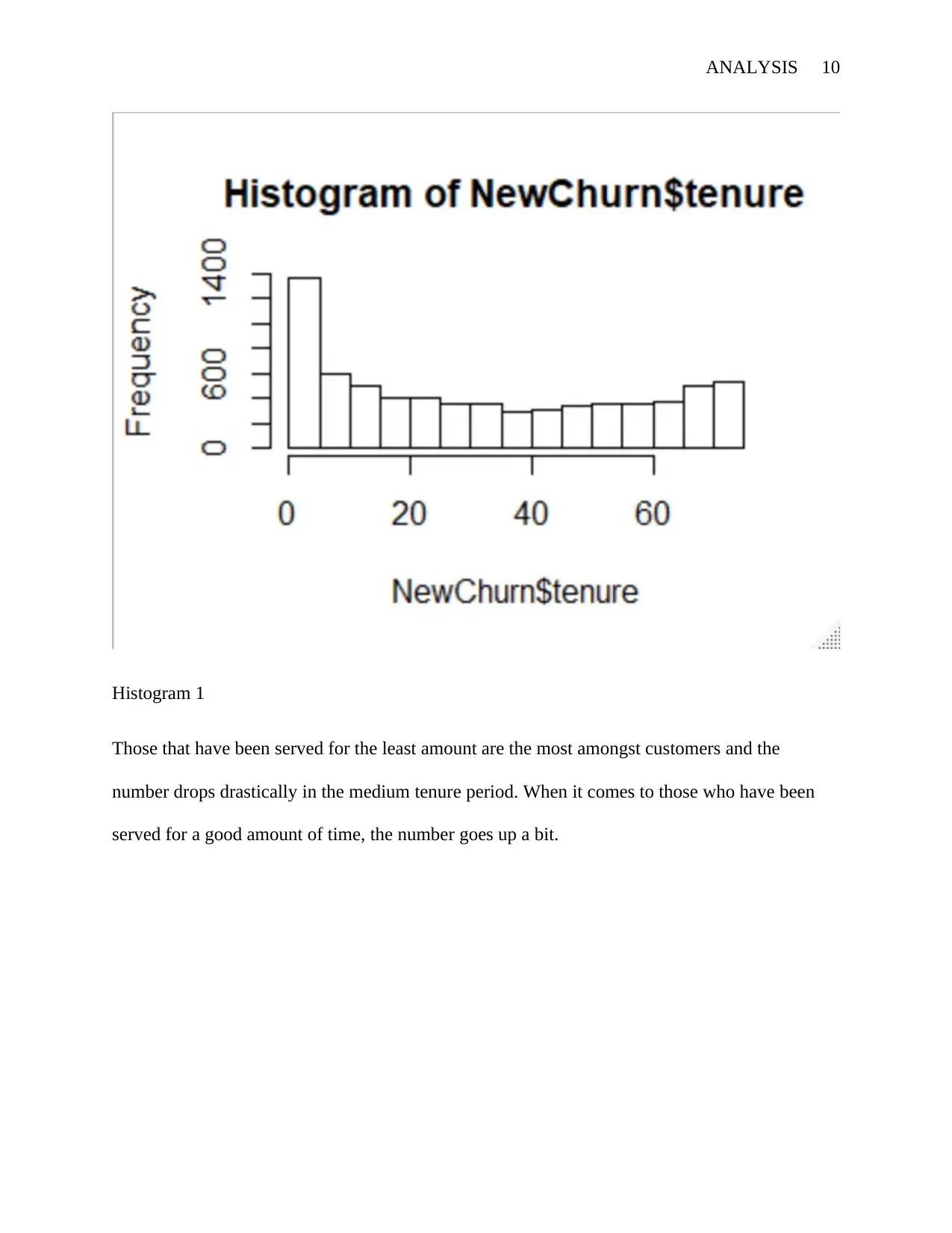
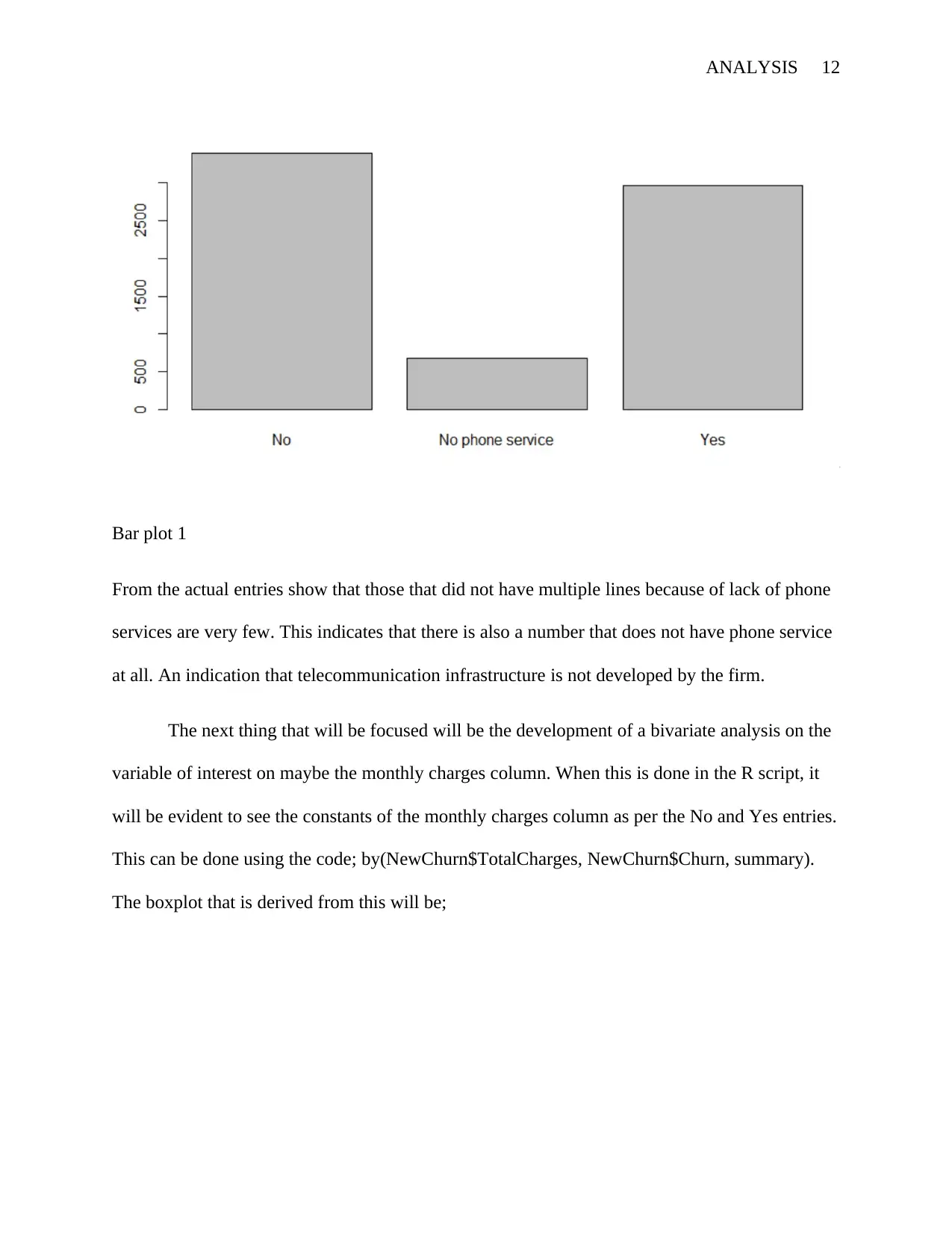
This report provides a comprehensive analysis of customer churn in a telecommunications company. It begins with an executive summary outlining the problem, data collection, analysis, and model development. The introduction identifies customer loyalty as a critical issue, especially with the emergence of new competitors. The report then details the methodology, including data preprocessing, univariate and bivariate analysis, and the application of logistic regression for classification. Data was collected from the company's database, with additional sources from Kaggle and GitHub. The analysis was performed using R, with libraries like 'mice' and 'VIM' used for handling missing data. The report includes visualizations such as histograms and boxplots to illustrate data distributions. A linear regression model was developed to determine relevant variables for the logistic regression model. The final section discusses the model's performance and provides recommendations for improving customer retention, with a focus on identifying inefficiencies and suggesting corrective measures based on the analysis.










1 out of 18
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.