Comprehensive Data Analysis Report: Durham Humidity Study
VerifiedAdded on 2023/06/14
|10
|1619
|242
Report
AI Summary
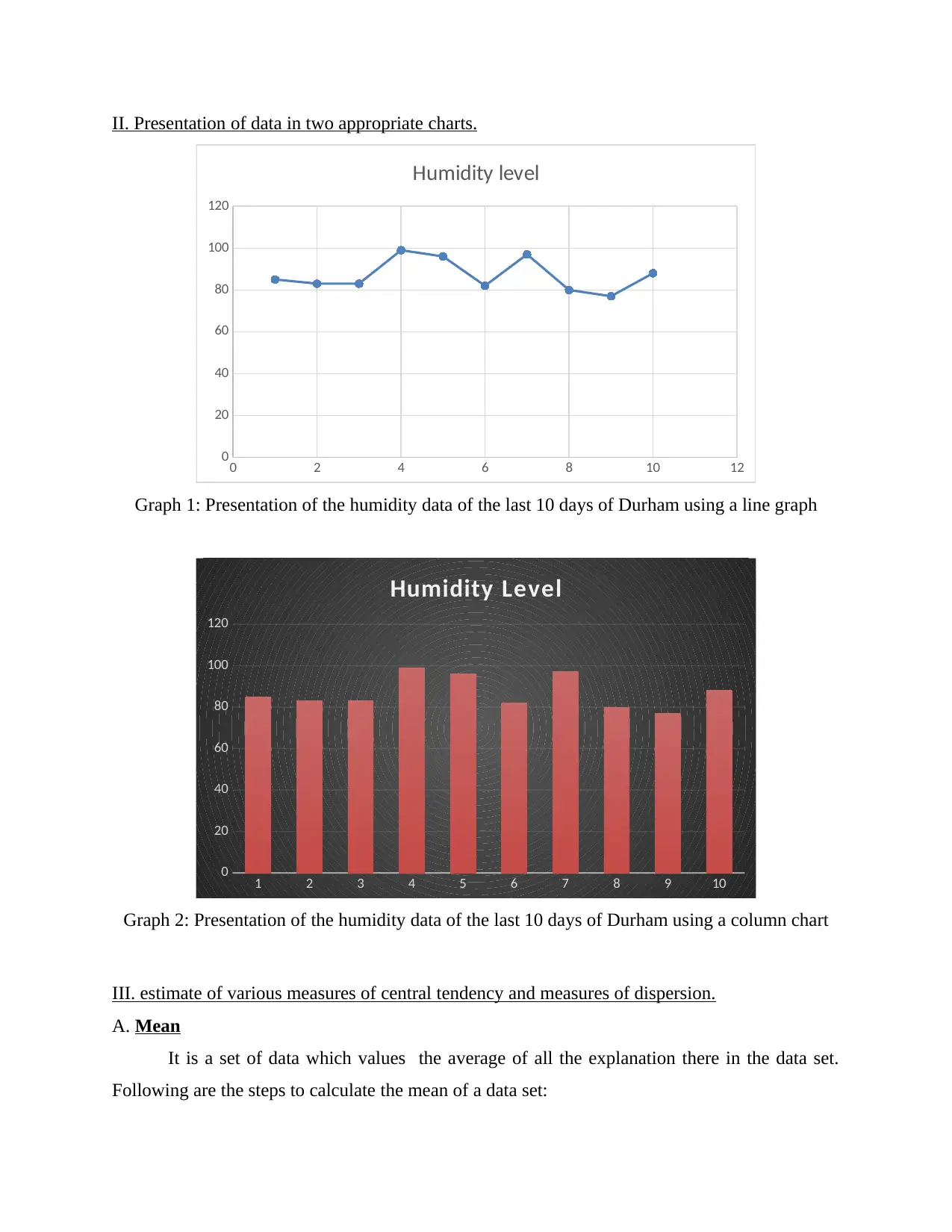
This report presents a comprehensive analysis of humidity data collected in Durham, North East England, employing various statistical methods to derive meaningful insights. The analysis includes data presentation in tabular and chart formats (line and column charts), calculation of measures of central tendency (mean, median, mode), measures of dispersion (range, standard deviation), and the application of a linear forecasting model to predict future humidity levels. The report details the steps involved in calculating each statistical measure and provides interpretations of the results, such as the mean humidity being 87, the median being 83, and the mode being 83. The linear forecasting model predicts humidity levels for the 11th and 13th days based on past data, demonstrating the practical application of data analysis in understanding and predicting environmental conditions. The study concludes that numeracy and data analysis are essential for interpreting and understanding data effectively.









1 out of 10
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.