Data Analytics Report
VerifiedAdded on 2019/09/26
|11
|833
|503
Report
AI Summary
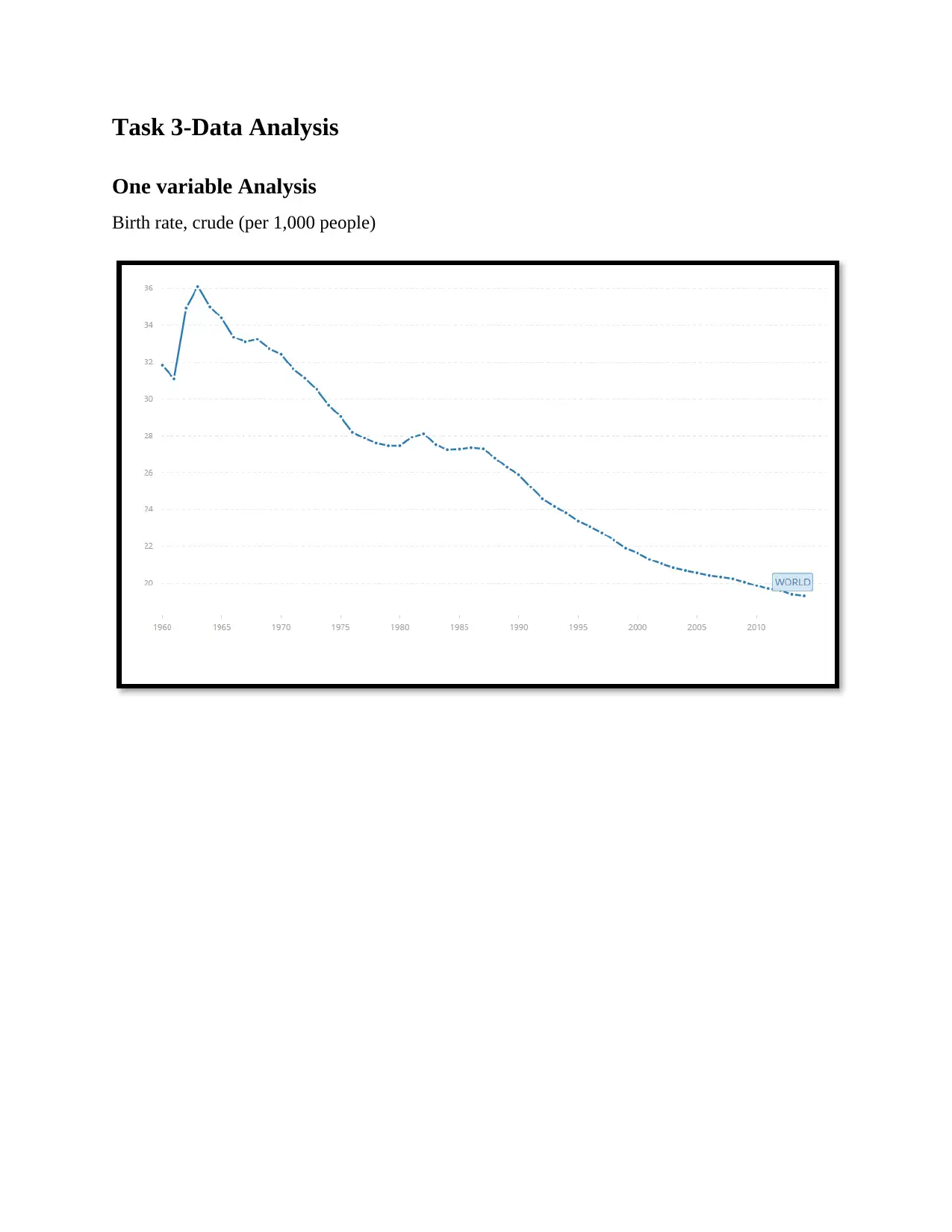
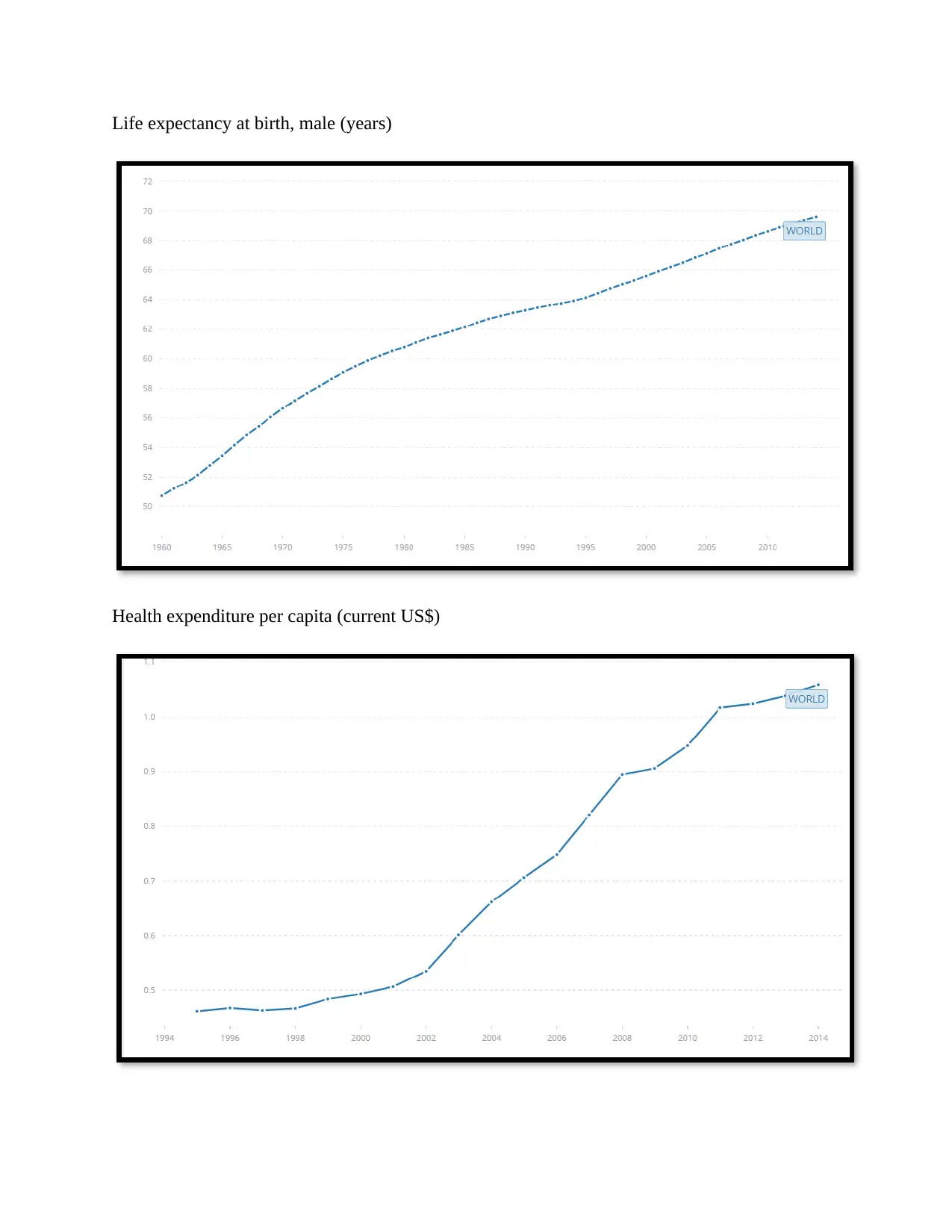
This report details a data analysis project using World Bank data on global health development over the past 15 years. The analysis is performed using R and covers several key areas. It begins with data setup and summary statistics. Then, it moves into one-variable analysis of key health indicators such as birth rate, life expectancy, and health expenditure. The report then delves into more advanced techniques, including k-means clustering to group countries based on similar health profiles and linear regression to model relationships between different health variables. The report concludes with a summary of findings and references to relevant research papers on k-means clustering and linear regression. The document is structured with a table of contents and clearly defined tasks, making it easy to follow the analysis process.







1 out of 11
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.