Data Analysis Report: Monthly Bill Data and Linear Forecasting
VerifiedAdded on 2022/11/25
|11
|1532
|353
Report
AI Summary
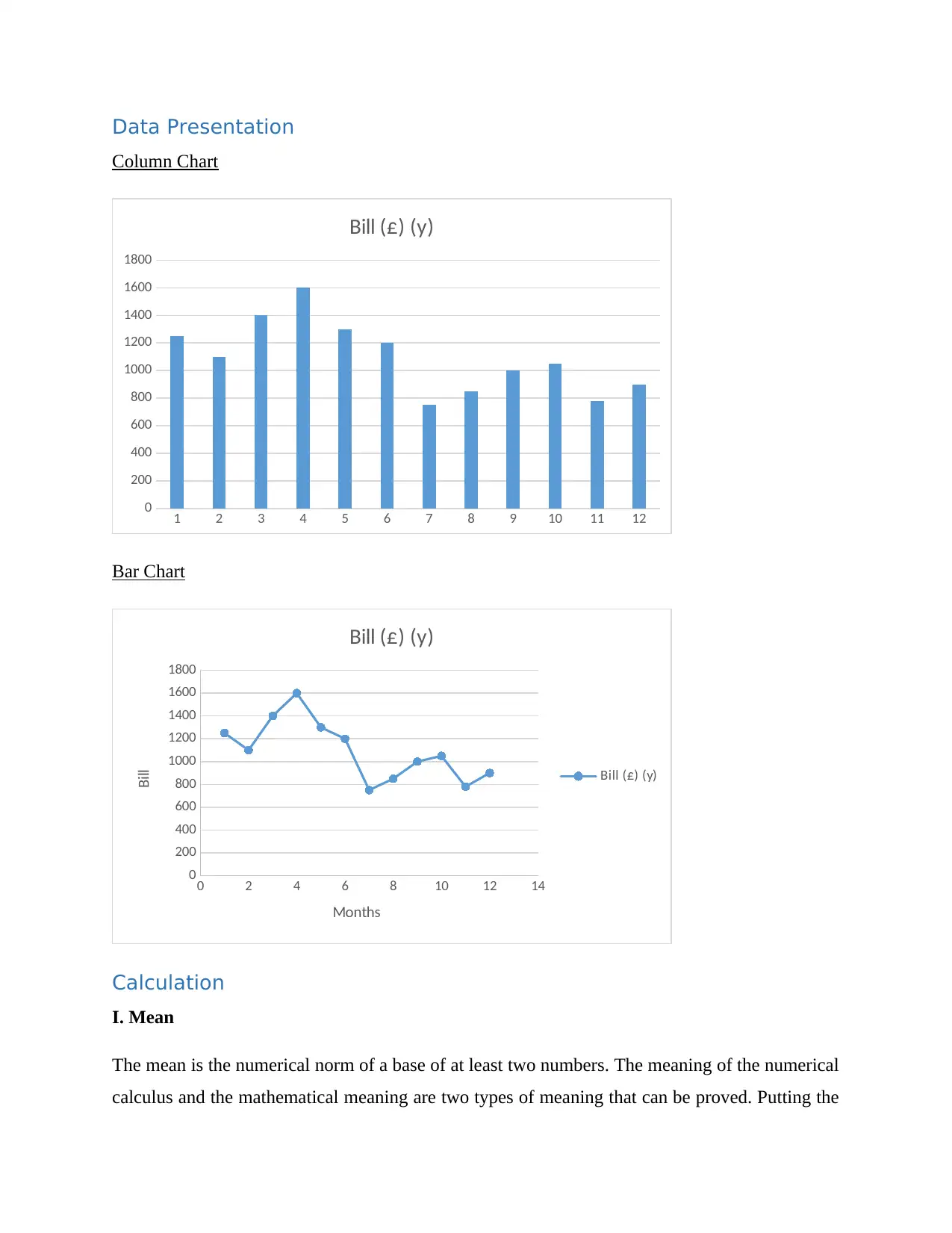
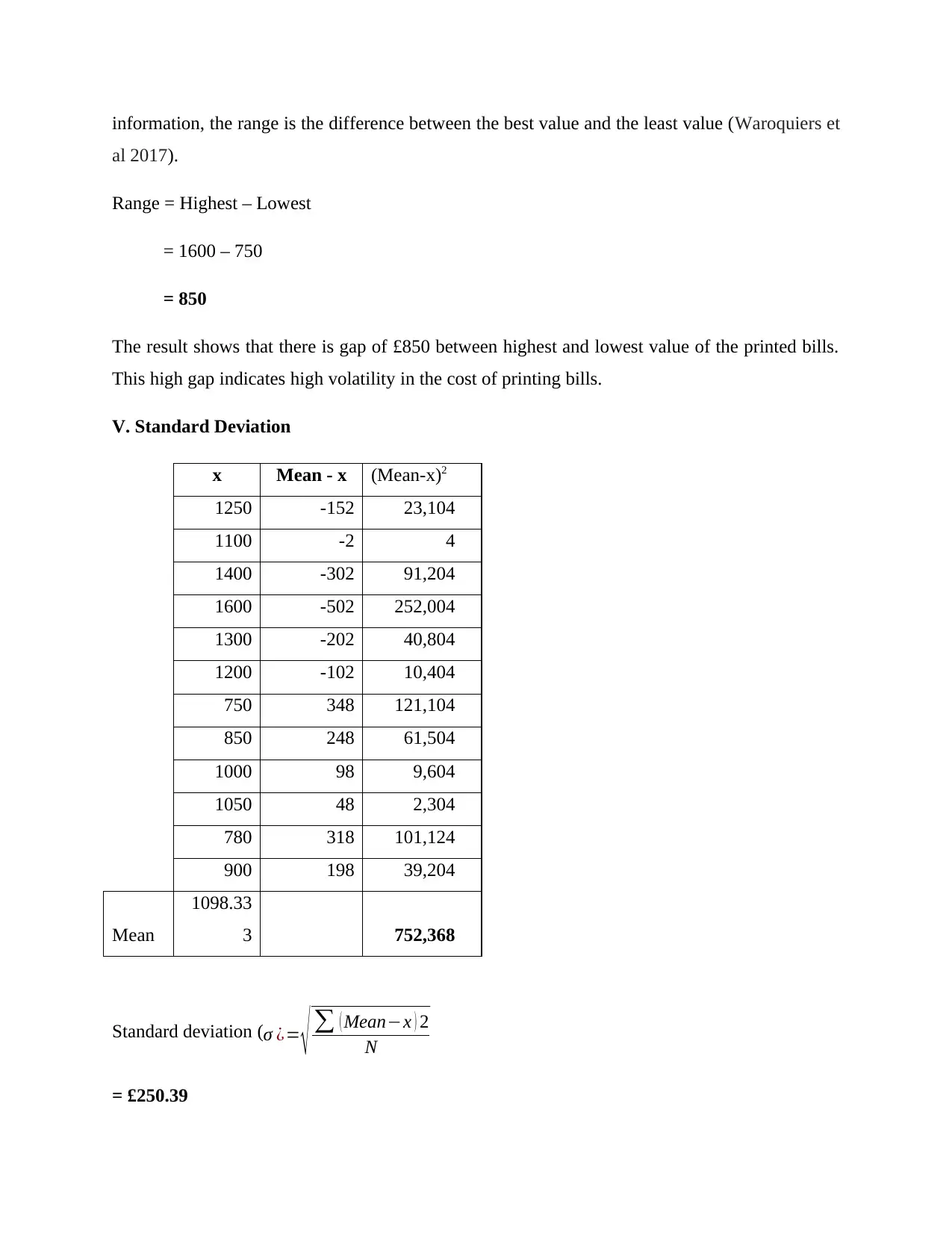
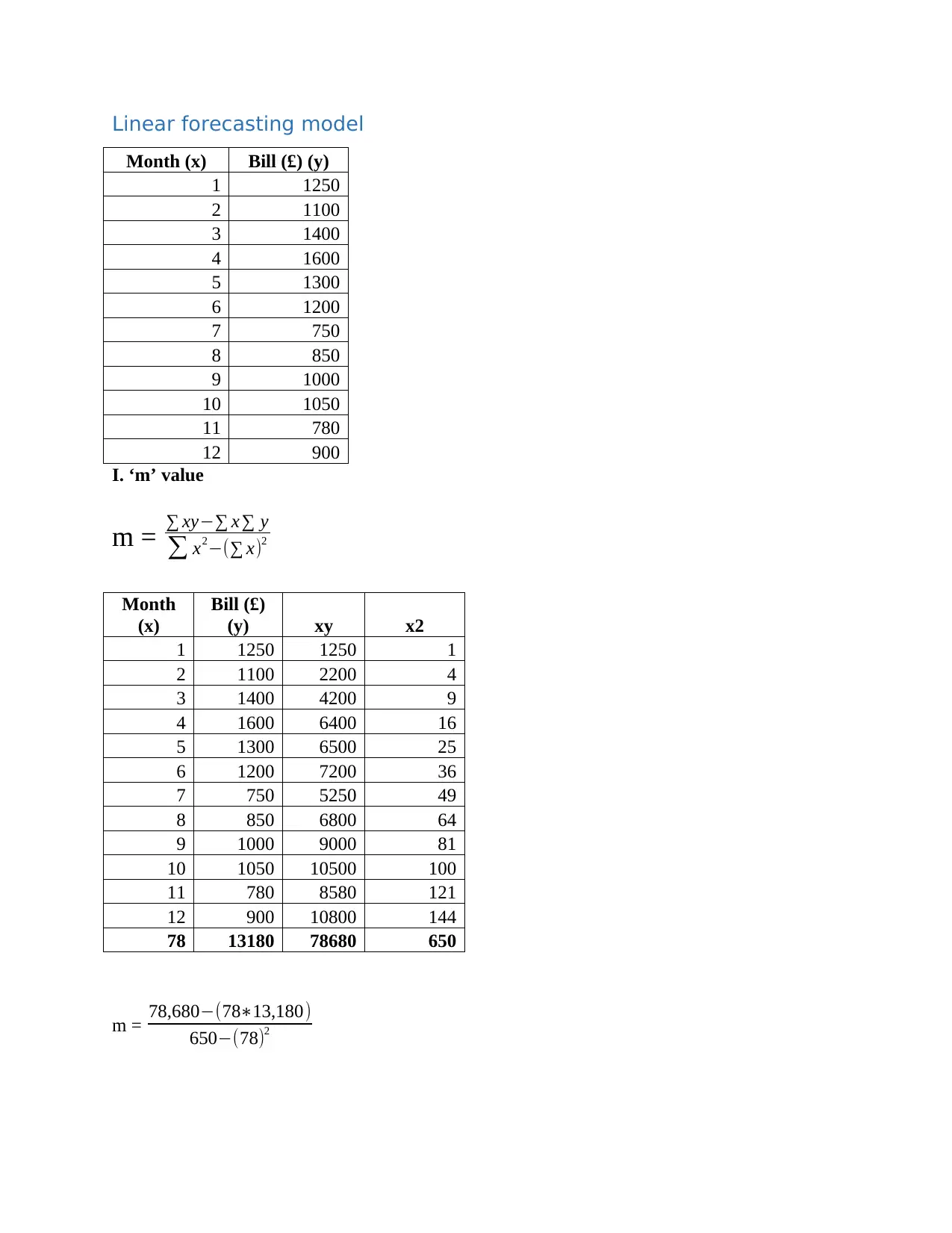
This report presents a comprehensive data analysis of monthly printed bills over a 12-month period. It begins with an introduction outlining the objectives and methodologies employed. The report details the data collection process and presents the data using column and bar charts for visualization. Descriptive statistical methods such as mean, median, mode, range, and standard deviation are calculated and interpreted to provide insights into the central tendency, dispersion, and variability of the bill amounts. Furthermore, a linear forecasting model is developed to predict future expenses, with calculations for the slope (m) and intercept (c) values. The report concludes with an assessment of the model's efficiency and suggests the use of more advanced statistical tools for improved data prediction. References to relevant statistical literature are also included.








1 out of 11



Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.